データベースの検索を高速化するには、とにかくI/O(ディスクアクセス)の回数を減らすことが重要とのことです。
そのための方法のひとつが、インデックスになります。
学習を深めるに当たって、かなりいろいろなサイトを参考にさせていただいたので、参考リンク&引用元として載せております。素晴らしい記事を書いてくださった皆様に感謝です。
mysql 5.5〜(InnoDB)
(記事作成:2016年3月)
目次
- インデックススキャンとは
- インデックスのアルゴリズムと B-Tree
- インデックスの種類
- 複合インデックスと Covering Index
インデックススキャンとは
データベースの問い合わせ手法として、シーケンシャルスキャンとインデックススキャン、フルテーブルスキャンがあります。
シーケンシャルスキャン (Sequential Scan)
- シーケンシャルスキャン(順次検索)は、すべてのデータを順に検索する、基本の検索方法
- あらゆる SQL に対応できるのがメリット
- 読み込むディスク量に比例して時間がかかる(件数×サイズによる)
これに対して、インデックススキャンは、辞書の中から単語を探すときに使う「索引」のような仕組みを使って検索します。
インデックススキャン(Index Scan)
- 大量のデータから条件にあった一部のデータを取り出すのに有効
- テーブルのカラムに関連づけて利用
- 検索は早くなるが、レコードの更新時にインデックスの更新も必要になるので書き換えは遅くなる
インデックススキャン の場合、検索するときは、最初にインデックスを読み、そのあとでテーブルを直接読む、という2段階の行動になります。
今回は主に、このインデックススキャンについてまとめます。
フルテーブルスキャン(Full Table Scan)
- インデックスを利用せずに、テーブル全体を読み込む方法
- テーブルの中の大部分のブロックにアクセスする場合は、インデックススキャンよりも高速になる場合がある
インデックスのアルゴリズムと B-Tree
インデックスは、 B-Tree というアルゴリズムを使って実装されていることがほとんどです。
名前の通り、ツリー型の構造を持ったアルゴリズムで、各ノードは2つ以上の子ノードを持てるようになっています。二分探索木をより複雑化した感じです。
B-Tree はハードディスクの構造との相性がよく、検索が早くなるために採用されているみたいです。
(インデックスの内部で使っているアルゴリズムによって、どのような検索を高速化できるかが異なります。ある種類のインデックスは一致検索に、あるものは大小比較に、あるものは全文検索にと、適用分野によって違いがあります。)
参考リンク
なぜBTreeがIndexに使われているのか
B-Tree インデックスの構造
インデックスに含まれるデータは、「各レコードのカラム値」と「レコードのポインタ」です。
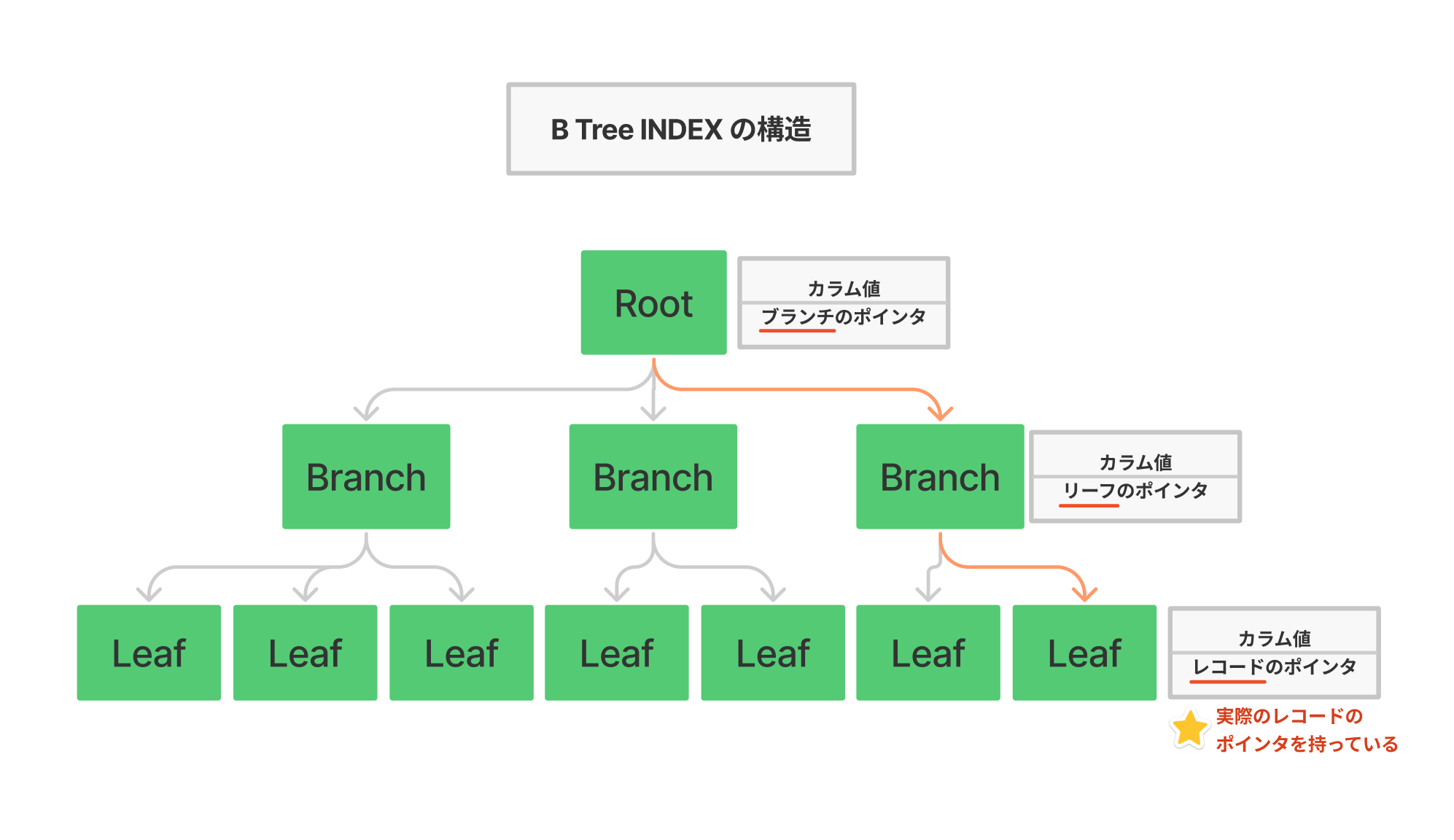
参考リンク
RDBMSをブラックボックスにしない - [第6回]Bツリー・インデックスの構造
インデックスの種類
インデックスは2種類に分けられます。
Primary index (Clustered index)
主キーまたはユニーク制約のある(重複しないことが確約されている)カラムに対して付与されるインデックス。
Secondary index
Primary index 以外の(重複の可能性がある)インデックス。
ex.) 従業員の名前など
パフォーマンス改善のために任意のカラムに付与される。
セカンダリインデックスのリーフノードには、対応する主キーの値が格納されている。
引用元
What is difference between primary index and secondary index exactly? [duplicate]
Differences between INDEX, PRIMARY, UNIQUE, FULLTEXT in MySQL?
検索時の Primary index (Clustered index) と Secondary index の違い
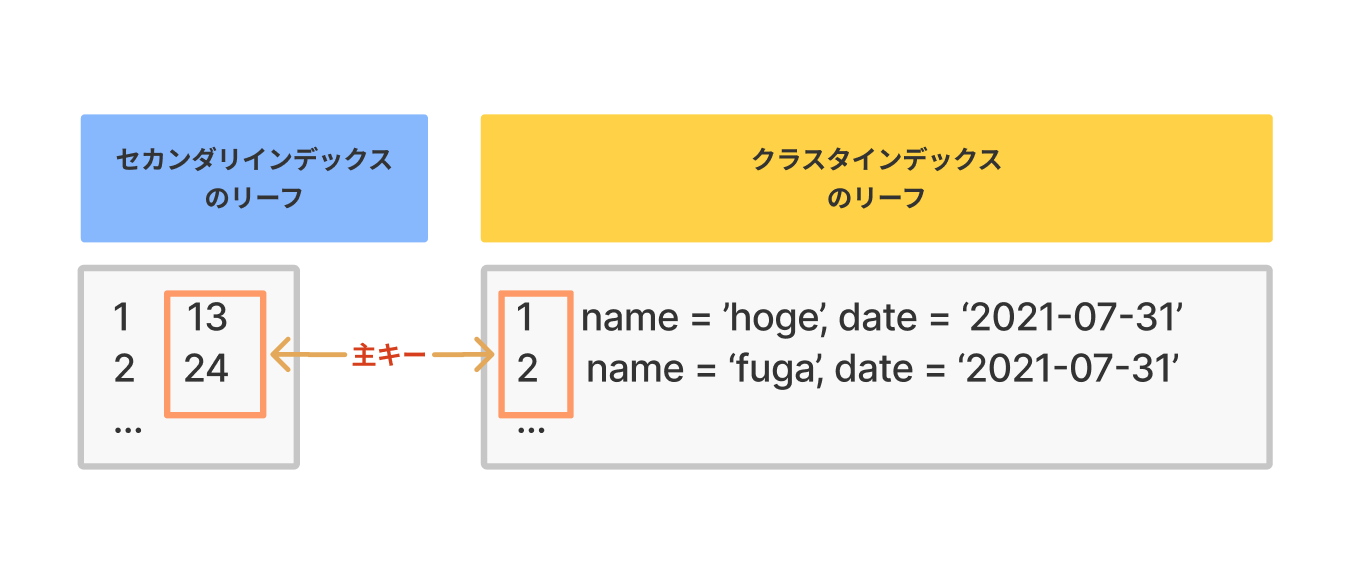
クラスタインデックスの場合には、主キーとそれ以外の列値がそのまま保存されています。そのため、インデックスの値を読めば即、その他の列値も取得できます。一方、セカンダリインデックスではインデックスを検索することで主キーの値がわかり、その主キーの値を使って、その他の列値の値を知ることが出来ます。
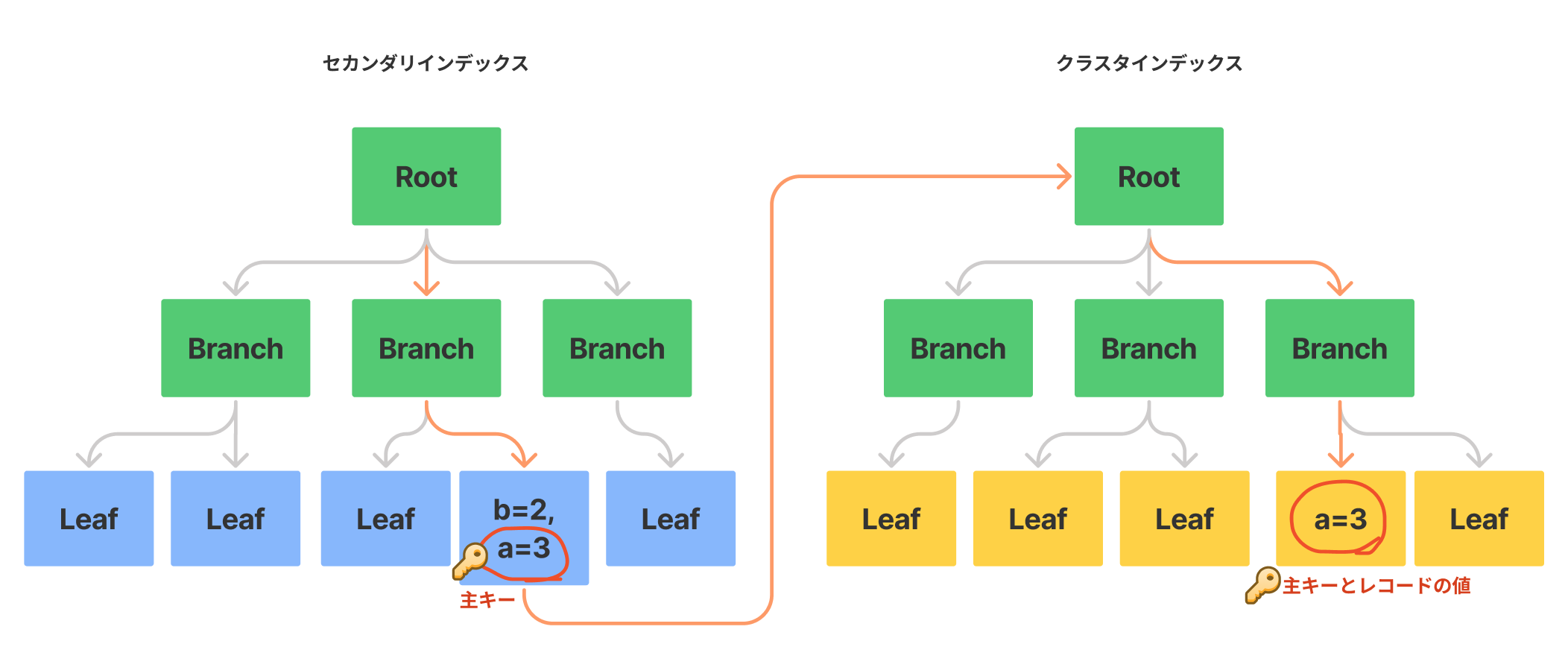
つまり、クラスタインデックスで検索が済む場合は非常に高速になります。
また、セカンダリインデックスでの検索は、1回目に該当するID(主キー)を探し出し、2回目にそのID(主キー)をもとにクラスタインデックスを使って、主キーに紐付いているレコードの値を取得するので、最低でも2回以上検索が走ることになります。
引用元
MySQLでインデックスを使って高速化するならCovering Indexが使えそう
引用元
知って得するInnoDBセカンダリインデックス活用術!
複合インデックスと Covering Index
何度も検索が走るのを防ぐために、複合インデックスを活用することができます。
複合インデックスとは
複数のカラムに渡って指定するインデックス。
CREATE INDEX インデックス名 ON テーブル名 (カラム名[, カラム名…])
検索するカラムが複合インデックスで指定したカラムに含まれていて、かつ、複合インデックスの指定したカラムに先頭から順に一致する場合は、検索に使うことができます。

Covering Index とは
ひとつのインデックスだけで検索が完結するインデックスのこと。
SELECT 文でカラムが絞られているのがポイントです。
主キーに紐付いている訳ではないので、レコードの全てのカラムの値は取れませんが、リーフだけで必要なデータが全て取得できるため1回の検索で済み、検索がとても高速になります。
ex.)
SELECT hoge, fuga FROM table_a WHERE foo = 1;

普通に考えると [foo] にインデックスを張って、リーフで得られた値から他の列値 (hoge, fuga) を取得する、とやりたくなるところです。ただ、ここで [foo, hoge, fuga] という複合インデックスを張ることで、リーフだけで必要なデータが全て得られ、その後のランダムアクセスが無くなるため高速になります。
引用元
MySQLでインデックスを使って高速化するならCovering Indexが使えそう
例えば、セカンダリインデックスを age に貼っておけば、以下のケースも、自然と Covering Index になります。
SELECT id, age FROM users WHERE age = 12 ORDER BY id;