はじめに
正しい情報を書くよう注意を払っていますが、間違っている可能性があります。
もし見つけた方はコメント等で教えていただけると幸いです。
3行まとめ
- 事前学習モデルをDiscriminatorに使用することで学習速度を17倍にした
- feature pyramidとrandom projectionを利用することで性能が向上した
- 少ない画像数でも低いFIDを実現

論文情報
NeurIPS2021 : http://www.cvlibs.net/publications/Sauer2021NEURIPS.pdf
arxiv : https://arxiv.org/abs/2111.01007
GitHub : https://github.com/autonomousvision/projected_gan
1.導入
Generatorは画像生成からRGB画像を生成するタスクを行い、Discriminatorは本物か偽物か識別する。Discriminatorは詳しくみると2つのタスクを行っている。1つ目は入力画像を意味空間に投射、入力画像の表現を学習する。2つ目はこの意味空間に基づいて識別する。残念ながらDiscriminatorとGeneratorを同時に学習させるのは非常に難しい。
Discriminatorの正則化は敵対的学習のバランスを整えるが、GradientPenaltyなどの基本的な正則化手法はハイパーパラメータの影響を受けやすく、性能が大幅に低下してしまうことがある。この研究では入力画像を意味空間に投射するタスクをPretrainedモデルに代替することで、性能の向上と学習の安定性を実現した。その中で複数のDiscriminatorによるマルチスケールフィードバックを可能にするfeature pyramidと、Pretrainedネットワークの深い層をより利用するためにrandom projectionが重要である。
2.関連研究
GAN学習での事前学習モデル
GANでの事前学習表現の研究は2つに分けられる。
1つ目はGANの一部分を新しいデータセットへ転移学習させる手法で、2つ目はGANの制御と性能向上に事前学習モデルを使用する手法である。2つ目の手法は事前学習は敵対的学習でなくても問題ないという利点がある。この研究では2つ目の方法に該当する。
事前学習モデルを用いて学習する場合、よくPerceptual Lossが用いられる。しかしこれは再構成対象があるimage-to-image変換タスクに特化している。この研究ではUnconditionalなGANの学習に使用できる手法を提案。
Discriminatorのデザイン
多くのGANの研究では新しいGeneratorの構造に重点を置いている一方、Discriminatorはシンプルな畳み込みニューラルネットワークに近いかGeneratorの前後を反転したものである。例外的にencoder-decoder構造を用いたDiscriminatorも提案されている。しかし、この論文と対照的にrandom projectionを使用していない。別の研究では複数のDiscriminatorを使用したり、低次元への投射を用いたりしている。
複数のDiscriminatorの使用は多様性や学習速度、安定性の向上が見込まれる。しかしながら、これらの手法は計算量の増加に比べリターンが少ないため現在のSoTAでは利用されない。1もしくは複数のDiscriminatorでのマルチスケールフィードバックは画像生成や画像変換で役立つ。
また、微分可能なDataAugmentationはDiscriminatorの過学習を抑制し、性能を向上させる。
3.提案手法
GANは学習データセットの分布をモデル化することを目的としている。Generator $G$は単純な分布$P_z$からサンプリングした潜在変数$z$(多くの場合は正規分布)を対応するサンプル$G(z)$に投射する。Discriminator $D$は実際のサンプルか($x \sim P_x$)、生成されたサンプルか($G(z) \sim P_{G(z)}$)識別することが目的である。この基本的な考え方から以下ような目的関数が導かれる。

この研究では特徴量写像 { $P_l$ }を導入する。これは実際の画像と生成画像をDiscriminatorの入力次元へ投射する。Projected GANの学習は以下のように定式化される。

{ $D_l$ }は異なる特徴量投射で動作する独立したDiscriminatorの集合である(この論文では入力解像度が異なる)。 { $P_l$ }のパラメータは固定され、$G$と{ $D_l$ }のみ最適化される。この特徴量投射{ $P_l$ }は微分可能であること、入力の十分な統計量を提供すること、つまり重要な情報を保持することの2つの条件を満たさなければならない。さらに、(1)の最適化が困難な目的を、勾配に基づく最適化に適した目的に変える特徴量投射{ $P_l$ }を見つけることを目指す。
{ $P_l$ }は事前学習モデルから複数解像度の中間特徴量を使用することで実現する$(𝐿_1=64^2,𝐿_2=32^2 ,𝐿_3=16^2,𝐿_4=8^2)$。また、それぞれの解像度において別々のDiscriminatorを使用する。このDiscriminatorは単純な畳み込み構造であり、spectral normalizationをそれぞれの畳み込みに使用する。このとき、Discriminatorの出力サイズを同じ$(4^2)$にすることでパフォーマンスが向上する。すべてのDiscriminatorの出力は加算してlossを計算する。
Discriminator
しかしながら、深い特徴量の層だけで識別するのはかなり難しい。また、Discriminatorは特徴量の一部にだけ焦点を当て、ほかの部分は無視することができると仮定すると(これは例えば顔画像であれば瞳だけで識別するようなこと)、この問題は層が深くなるほど問題になる。深いほど意味的情報になるため一部の意味的情報のみを使用してしまう。
この一部分にしか注目しない問題を軽減することでDiscriminatorにすべての情報を等しく利用させる。よく使用される方法は特徴量をランダムに固定の微分可能な投射を行うことであり、例えば畳み込みでランダムな初期化を行い重みを学習しないことで実現できる(ランダムプロジェクション)。

ランダムプロジェクションは情報保存的であり、3次元的に反転可能であってはならない(逆写像が存在しないように?)という2つの要素を満たす必要がある。簡単な例は1x1畳み込みである。これは入力の情報を保持でき、また元の次元よりチャネル数が大きいとよい性能がでることが分かった。
初期化時にランダムな回転行列で畳み込みレイヤーを初期化する手法があるが、これはGANの性能が向上するわけではなかった。そのためここではランダムな初期化を行うが、このとき活性化関数は使用しない。

この論文では解像度ごとの特徴を混ぜ合わせるためCCMを拡張したCSMを使用する。これは低解像度の特徴量(ランダムプロジェクション適応済み)に3x3畳み込み(CCMと同様にランダムに初期化)を使用し、Bilinear補間を行ったあと同じ解像度の特徴量と足し合わせる。これにより複数の解像度の特徴量を同時に見ることができ性能が向上する。構造はU-Netに似ているが、U-Netと異なり1つの畳み込みを使用する。
Ablation Study
CCM,CSMがどのくらい効果があるのか、また複数のDiscriminatorで性能が変化するのか比較した。ここでは特徴量プロジェクションとしてEfficient Net Lite1を使用した。様々な結果から、Discriminator Augmentationはすべての方法で性能が向上し、SoTAに達する性能が出るということと、FastGAN(Lightweight GAN) GeneratorにはDifferentiable data-augmentationが最も性能がよかった。
評価の計算にはFréchet Distance (FD)を使用しGeneratorがどの特徴量にfitしているか調べた。Perceptual Discriminator(複数の特徴量を同じDiscriminatorに入力し予測するモデル)との性能を比較する。
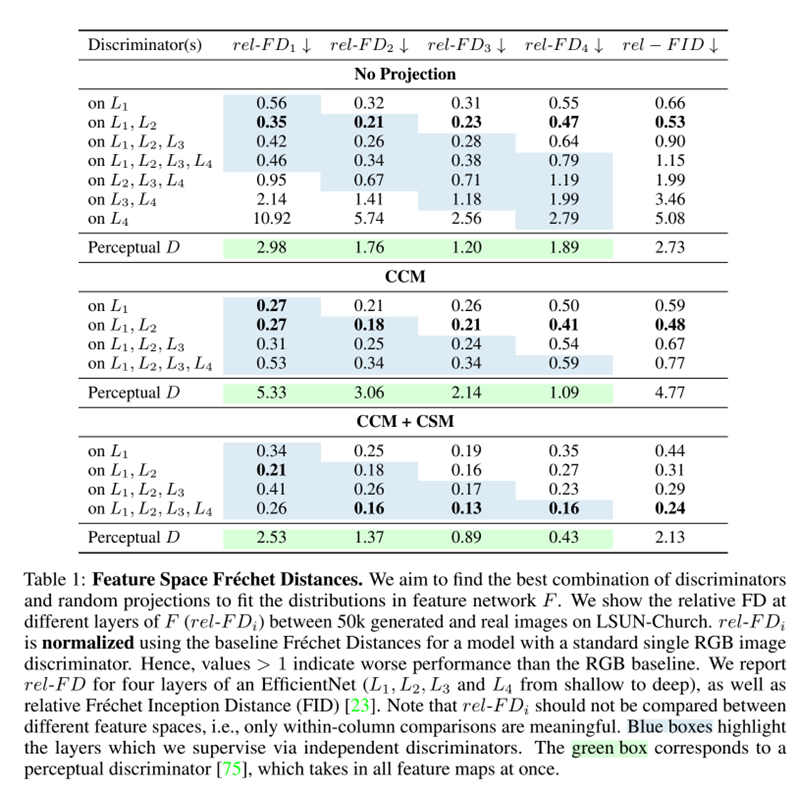
まず、複数のDiscriminatorを使用する必要があるのかを調べた。No Projectionの2行目から、Discriminatorが1つのものよりも2つ使用したほうが性能が改善していることがわかる。しかし、6,7行目から深い層にDiscriminatorを挿入すると性能が悪化することがわかる。これは深い層ほど特徴量が意味的情報になってくが、この意味特徴量が直接的に敵対的損失と対応するわけではないということである。また、オリジナルの画像をリサイズしても性能は改善しなかった。
また、3,4,5行目から浅い層のDiscriminatorを省略すると性能が下がることもわかる。これは浅い層は元画像のほとんどの情報を含んでいるためと推測する。Feature Inversion(特徴量から元画像を復元するタスク)の研究によると深い層ほど情報をもとに戻すのが難しい。
4行目を見るとPerceptual Discriminatorよりも性能がいいことがわかる。つまり独立したDiscriminatorはより高い性能を実現するということである。
次にCCMとCSMを比較した。CCMはNo Projectionと比較するとすべての設定においてFDを減少させることがわかる。また、CSMを加えるとさらに性能が向上することがわかる。特に深い層でのrel-FDが改善していることがわかる。以上より、独立したDiscriminatorは性能を向上させ、さらにCCM,CSMを用いることで深い層でのDiscriminatorの性能が向上し、全体のFIDがもっとも低くなった。
事前学習モデル
ここまではDiscriminatorの構造がどのような構造が適しているか調べたが、特徴量プロジェクションに使用する事前学習モデルによってもDiscriminator全体の性能が異なる。そこでさまざまなモデルを事前学習モデルとして使用することで、どのようなモデルが最適なのか検証する。
使用するモデルは
- Efficient Net Liteの複数のバージョン(Imagenetで学習)
- ResNet18(Imagenetで学習)
- ResNet50(Imagenetで学習したものとCLIPで学習したものの2つ)
- Vision Transformerと蒸留したDeiT(Imagenetで学習)
Inception NetworkはFID計算に用いるので使用していない。CCM+CSM+4 Discriminatorsの設定でそれぞれのネットワークを比較した。

これを見ると、Imagenetの性能とFIDに関係性がないことがわかる。たとえばViT,DeiTはImagenetの性能が非常に高いが、ViTのFIDは非常に大きくDeiTと大きく異なる。逆にImagenetの性能が低いEfficienNetのほうがFIDが小さい。
パラメータとFIDを比較すると、パラメータが小さいほどFIDが低くなる傾向がある。つまり提案手法はよりコンパクトな特徴量表現のほうが性能を発揮できることがわかる。
次にResNet50を見る。ImageNetで学習したものよりCLIPで学習したもののほうが性能が高いことがわかる。つまりImageNetで得られた特徴量が重要ではないことがわかる。また、ランダムに初期化したネットワークを使用するとFIDが非常に大きくなるため、何らかのデータセットで学習したモデルの特徴量が重要だとわかる。
すべての結果を比較し、最もFIDが低かったEfficientNet-Lite1を以降の実験では特徴量ネットワークとする。
SoTAの手法との比較
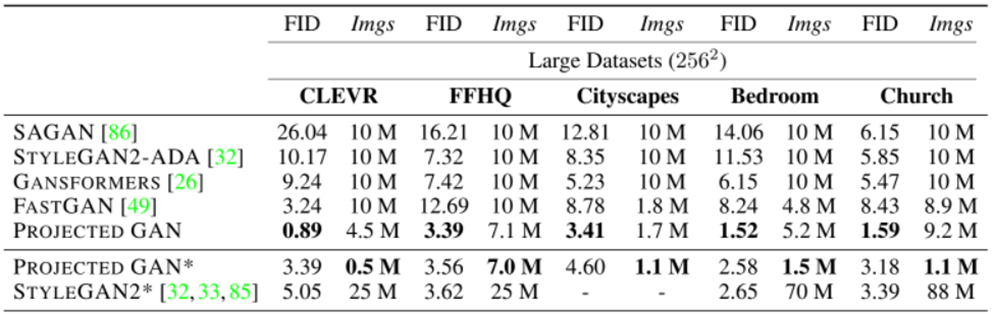
生成画像50kとすべての実際の画像間でFIDを比較した。FIDはそれぞれの手法で最も良い値を選んだ。$imgs$は最良のFIDの5%以内に到達したときの画像数を表す。StyleGAN2-ADAとFastGANをベースラインとして使用した。DataAugmentationはDifferentiable Data AugmentationとAdaptive Discriminator Augmentation(ADA)の2種類を使用し、そのうちでより良い性能を出したものを選択した。また、すべてのデータセットで水平フリップを適用した。
Projected GANは同じGeneratorとDiscriminator、ハイパーパラメータをすべての実験で使用した。ただし高解像度の画像生成で追加でUpsampleブロックを追加した。
ベースラインの最良の結果のためにハイパーパラメータを注意深く調整した。その結果、FastGANはバッチサイズに敏感に反応したり、StyleGAN2-ADAは学習率とR1 Penaltyに強く反応した。
LSUN-Church, CLEVRデータセット
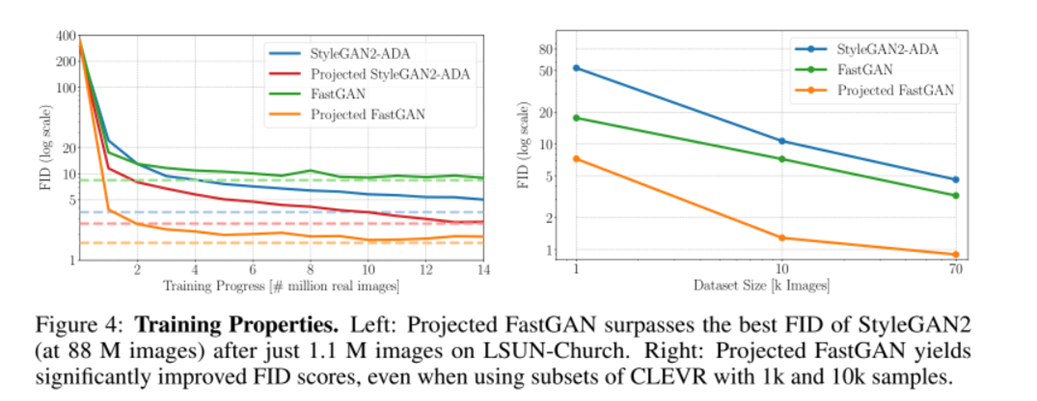
(左)FastGANは収束が速いが最終的なFIDはStyleGAN2のほうが高い。Projected GANは収束も早く最終的なFIDも低い。(右)CLEVRデータセットの中からランダムに10k,1kの画像を抽出した場合の性能を比較した。Projected GANはどちらのベースラインの性能を大きく上回っており、つまりデータ効率が非常に良いことがわかる。
StyleGAN2で88Mの画像を使用した場合よりもProjected FastGANで1.1Mの画像を使用した場合のほうがFIDが低い。

FastGAN,StyleGANともにテクスチャはグローバルな構造に変化していくが、Projected GANは時間の経過とともに構造が細かくなるという違いがある。しかし同じ潜在変数でもかなり見た目が変わってしまう。それは意味的フィードバックを行うためではないかと推測している。
LSUN-Bedroom,FFHQ,Cityscapes
ProjectedGANはモデルに通した画像数が少ないにも関わらず、すべてのSoTAモデルの性能を上回っており、収束速度も高速であることがわかる。また、これらのデータセットはさまざまな物体、シーンを含むので、データセットを選ばないということがわかる。
Small Dataset
それぞれのデータセットの画像数は
- WikiArt : 1000
- Oxford Flowers : 1360
- Landscapes : 4319
- AnimalFace-Dog : 389
- Pokemon : 833
- AFHQ-Wild : ~5k

すべてのデータセットにおいて性能を大きく改善したことがわかる。0.6Mの画像だけでほかのベースラインの性能を超えた。特にAnimalFaceではたった20kの画像だけで超えた。ただし、これはEfficientnetがImageNetで学習しており、動物のデータが含まれていたからではないかと推測する。しかしPokemonなどImageNetと大きく異なるデータセットでも性能が出ている。
高解像度データセットでは、ベースラインより何倍も早く同じFIDの値に到達しており、AFHQ-CATはStyleGAN2-ADAの10倍の速度で収束し、PokemonはFastGANの4倍の速度で収束した。
まとめ
- Discriminatorに事前学習ネットワークを特徴量プロジェクションを導入
- CSMによりほかの解像度の特徴量も参照でき性能が改善
- EfficientNet,ResNet,Transformerの事前学習モデルを比較したとき、EfficientNetの性能が- 最もよかった
- 以上の技術でGANの収束速度を大きく向上させただけでなく、少量の高解像度データセットでも高い性能を出した
感想
Discriminatorを変えるだけで性能も上がるし収束速度も上がるめちゃめちゃすごい技術ですね...
ちなみにGitHubに簡単にこのDiscriminatorを使用できるような実装があるので、興味ある人はぜひ見てみてください!!