polarsでLazyFrameからピボットテーブルを作る方法とその速度比較
ピボットテーブルを作る(ここではクロス集計をするという意味)際、pl.DataFrameには.pivot()メソッドがあるが、pl.LazyFrameには用意されていない。ではどのようにすればよいのだろうか。
ここでは簡単な例を用意して、いくつか方法を考案し、速度を比較してみたい。
例題
次のようなデータがあるとしよう。
import numpy as np
import polars as pl
rng = np.random.default_rng(42)
df = pl.DataFrame(
{
"upper": rng.choice(list("ABC"), 10),
"lower": rng.choice(list("abc"), 10),
"value": rng.integers(0, 5, 10),
}
)
print(df)
# shape: (10, 3)
# ┌───────┬───────┬───────┐
# │ upper ┆ lower ┆ value │
# │ --- ┆ --- ┆ --- │
# │ str ┆ str ┆ i64 │
# ╞═══════╪═══════╪═══════╡
# │ A ┆ b ┆ 2 │
# │ C ┆ c ┆ 1 │
# │ B ┆ c ┆ 0 │
# │ B ┆ c ┆ 4 │
# │ B ┆ c ┆ 3 │
# │ C ┆ c ┆ 3 │
# │ A ┆ b ┆ 2 │
# │ C ┆ a ┆ 4 │
# │ A ┆ c ┆ 2 │
# │ A ┆ b ┆ 2 │
# └───────┴───────┴───────┘
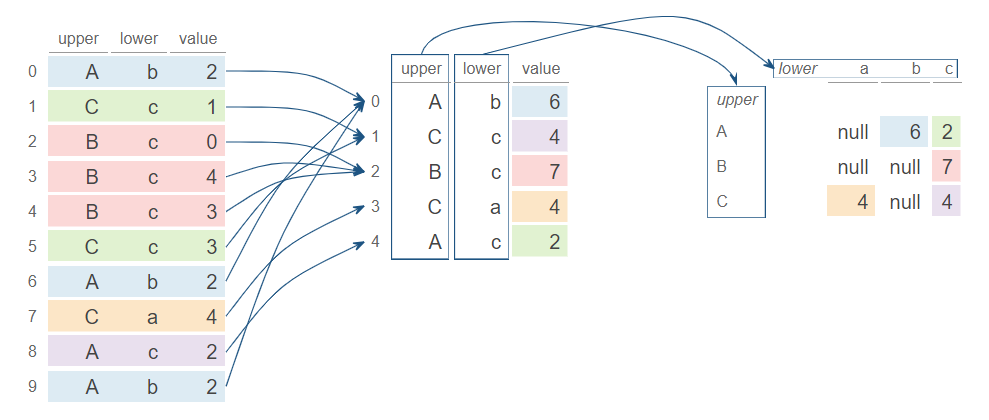
1列目にはA, B, Cのいずれか、2列目にはa, b, cのいずれかが入っている。各アルファベットの組み合わせごとの数値の合計を計算するには、DataFrame.pivot()を用いて次のようにすれば良い(ここでは行・列ともにソートした状態で結果を出力する)。
pivot_df = df.pivot(
on="lower",
index="upper",
values="value",
aggregate_function="sum",
sort_columns=True,
).sort("upper")
print(pivot_df)
# shape: (3, 4)
# ┌───────┬──────┬──────┬─────┐
# │ upper ┆ a ┆ b ┆ c │
# │ --- ┆ --- ┆ --- ┆ --- │
# │ str ┆ i64 ┆ i64 ┆ i64 │
# ╞═══════╪══════╪══════╪═════╡
# │ A ┆ null ┆ 6 ┆ 2 │
# │ B ┆ null ┆ null ┆ 7 │
# │ C ┆ 4 ┆ null ┆ 4 │
# └───────┴──────┴──────┴─────┘

.pivot()はデータフレームに対しては可能だが、レイジーフレームでは不可能である。例えば次のようなデータがあるとする。
import numpy as np
import polars as pl
rng = np.random.default_rng(42)
lf = pl.LazyFrame(
{
"upper": rng.choice(list("ABC"), 10),
"lower": rng.choice(list("abc"), 10),
"value": rng.integers(0, 5, 10),
}
)
次のようなコードはエラーになる。
pivot_df = (
lf.pivot(
on="lower",
index="upper",
values="value",
aggregate_function="sum",
sort_columns=True,
)
.sort("upper")
.collect()
)
# AttributeError: 'LazyFrame' object has no attribute 'pivot'
ではどのようにすればよいのか。
提案方法一覧
(1) データフレームにして.pivot()
もちろん、初手でレイジーフレームをデータフレームに変換すればなんのことはない。
pivot_df = (
lf.collect()
.pivot(
on="lower",
index="upper",
values="value",
aggregate_function="sum",
sort_columns=True,
)
.sort("upper")
)
print(pivot_df)
# shape: (3, 4)
# ┌───────┬──────┬──────┬─────┐
# │ upper ┆ a ┆ b ┆ c │
# │ --- ┆ --- ┆ --- ┆ --- │
# │ str ┆ i64 ┆ i64 ┆ i64 │
# ╞═══════╪══════╪══════╪═════╡
# │ A ┆ null ┆ 6 ┆ 2 │
# │ B ┆ null ┆ null ┆ 7 │
# │ C ┆ 4 ┆ null ┆ 4 │
# └───────┴──────┴──────┴─────┘
(2) groupbyしてからデータフレームに変換して.pivot()
今回取り上げている例では、.pivot()に対してaggregate_function="sum"(グループごとの和を処理)を指定している。この和を集計する部分のみをLazyFrame.group_by()で行い、その後データフレームに変換して.pivot()を行うという方法がある。
pivot_df = (
lf.group_by("upper", "lower")
.agg(pl.sum("value"))
.collect()
.pivot(
on="lower",
index="upper",
values="value",
aggregate_function="first",
sort_columns=True,
)
.sort("upper")
)
print(pivot_df)
# shape: (3, 4)
# ┌───────┬──────┬──────┬─────┐
# │ upper ┆ a ┆ b ┆ c │
# │ --- ┆ --- ┆ --- ┆ --- │
# │ str ┆ i64 ┆ i64 ┆ i64 │
# ╞═══════╪══════╪══════╪═════╡
# │ A ┆ null ┆ 6 ┆ 2 │
# │ B ┆ null ┆ null ┆ 7 │
# │ C ┆ 4 ┆ null ┆ 4 │
# └───────┴──────┴──────┴─────┘
この方法は(1)に比べて無駄があるように見えるかもしれないが、縦持ちデータを縦持ちのまま(そしてレイジーフレームのまま)集計し、最後に出力形のみをピボットテーブルに変換しているという点で、実践的(現実への適用可能性が広いという意味)である。
(3) groupbyでカラムごとに集計
これはLazyFrame.pivot()の代替手段として公式APIドキュメントに書かれている方法である。カラムに来る列をフィルターしてそれぞれ集計する。
LOWER_LIST = list("abc")
pivot_df = (
lf.group_by("upper")
.agg(
pl.col("value").filter(pl.col("lower") == lower).sum().alias(lower)
for lower in LOWER_LIST
)
.sort("upper")
.collect()
)
print(pivot_df)
# shape: (3, 4)
# ┌───────┬─────┬─────┬─────┐
# │ upper ┆ a ┆ b ┆ c │
# │ --- ┆ --- ┆ --- ┆ --- │
# │ str ┆ i64 ┆ i64 ┆ i64 │
# ╞═══════╪═════╪═════╪═════╡
# │ A ┆ 0 ┆ 6 ┆ 2 │
# │ B ┆ 0 ┆ 0 ┆ 7 │
# │ C ┆ 4 ┆ 0 ┆ 4 │
# └───────┴─────┴─────┴─────┘
問題点が3つある。第一に、列をあらかじめ指定しておく必要がある。すなわちこの例では、"lower"列で生じる全てのユニークな値(この例ではa,b,c)を過不足なく事前に知っている必要がある。第二に、元のデータに存在しない組み合わせを欠損値にするには工夫がいる(ここではそれを行っていないため、nullになるべき箇所が0になっている)。第三に、forループ内包表記が入ることで意味的可読性が損なわれているし、なんだか遅そそうな気がする。
速度の比較
最終的なピボットテーブルが10x10サイズになるように各列が取りうる値を拡張して、データフレームの長さを1行から1000万行まで変化させ、速度の比較を行った。なおpolarsのバージョンは1.2.1である。
import benchit
import numpy as np
import polars as pl
UPPER_LIST = list("ABCDEFGHIJ")
LOWER_LIST = list("abcdefghij")
# 方法(1)
def eager_pivot(lf: pl.LazyFrame) -> pl.DataFrame:
df = lf.collect()
out_df = df.pivot(
on="lower",
index="upper",
values="value",
sort_columns=True,
aggregate_function="sum",
).sort("upper")
return out_df
# 方法(2)
def lazy_group_by_pivot(lf: pl.LazyFrame) -> pl.DataFrame:
agg_df = lf.group_by("upper", "lower").agg(pl.sum("value")).collect()
out_df = agg_df.pivot(
on="lower",
index="upper",
values="value",
sort_columns=True,
aggregate_function="first",
).sort("upper")
return out_df
# 方法(3)
def lazy_group_by(lf: pl.LazyFrame) -> pl.DataFrame:
out_df = (
lf.group_by("upper")
.agg(
pl.col("value").filter(pl.col("lower") == lower).sum().alias(lower)
for lower in LOWER_LIST
)
.sort("upper")
).collect()
return out_df
rng = np.random.default_rng(0)
funcs = [eager_pivot, lazy_group_by_pivot, lazy_group_by]
inputs = {
n: pl.DataFrame(
{
"upper": rng.choice(UPPER_LIST, n),
"lower": rng.choice(LOWER_LIST, n),
"value": rng.integers(0, 10, n),
}
).lazy()
for n in 10 ** np.arange(0, 8)
}
t = benchit.timings(funcs, inputs)
t.plot(figsize=(8, 5), logx=True)

※グラフ縦軸は処理速度(下の方が速い)、横軸は元データフレームの行数
今回の例では、元データフレームの行数が10万行程度ならば最初にLazyFrameをDataFrameに変換するのが最も速く、100万行以上の場合は集計作業のみをLazyFrame.group_by()で行ってデータ形状変換のみをDataFrame.pivot()に任せるのが速いという結果となった。これは、大規模データを集計演算という観点ではLazyFrame.group_by()の方がDataFrame.pivot()よりもわずかに速いということなのかもしれない。
追加検証
ここで、方法(3)ではカラム数に応じたforループが使われていることから、方法(3)の速度は特にデータ内容(すなわちon=引数に指定した列のユニークカウント数)に依存するのではないかという疑問が生じる。
そこで次のように、最終出力ピボットテーブルの列数が少なくなるようにしたケースを実行したところ、異なる結果となった。
import benchit
import numpy as np
import polars as pl
UPPER_LIST = list("ABCDEFGHIJ")
+ LOWER_LIST = list("abc")
- LOWER_LIST = list("abcdefghij")
# (以下同)

1万行以下では、手法(3)が他の方法を上回る結果となった。
結論
DataFrame.pivot()と同様の作業をLazyFrameに対して行いたい場合の効率的な方法は、おおむね次のように設定できるだろう。
- 最終的な列数(
on=引数に渡す列のユニークカウント数)が既知で数個、かつ全体の行数が1万行以下程度であれば、公式のDataFrame.pivot()のドキュメントで紹介されている、forループを用いる方法を用いるのが良い。 - 最終的な列数が未知で、全体の行数が10万行以下であれば、
LazyFrameをDataFrameに変換してDataFrame.pivot()を適用するのが良い。 - 最終的な列数が未知で、全体の行数が10万行以上であれば、集計演算を
LazyFrame.group_by()で行った後に、結果をDataFrameに変換してDataFrame.pivot(aggregate_function="first")を適用するのが良い。
ただし、今回は加算を例にしたが、集計演算の内容によっては速度が変わるかもしれないことには注意が必要である。また、集計対象の列数が増えた場合も結果が変わるかもしれない。