著者
- 太田恒平(株式会社トラフィックブレイン)
- 伊藤昌毅(東京大学 生産技術研究所)
ご案内
この記事は、2020年3月に開催された技術書典8のために執筆した記事のドラフト版です。BOOTHにおいては、この記事を含む様々な公共交通データ活用技術を紹介した「鉄道とバスのデータをハックする2」をオンライン販売しております。この記事が面白かったという方は、この他にも様々な記事を掲載しておりますので、是非BOOTHにてtechForMobilityの同人誌をご覧下さい。

運行頻度図とは
この記事では、地域に提供された公共交通サービスの品質を直感的に把握できる公共交通の運行頻度図を、GTFSデータから作成する手法を解説します。運行頻度図は1日に走る公共交通の本数を、地図上に線の太さと数字で表現しており、場所ごとに公共交通が十分提供されているかどうかを確認できます。例えば、朝6時から夜10時まで30分おきに走っていれば、1日の運行本数は35本となります。そのため、都市部においては1日の本数が30本前後あることが、最低限のサービスレベルになるでしょう。朝6時から夜11時まで10分おきに走っていれば、1日の本数は103本になります。つまり、1日100本を超えていれば、時刻表をあまり意識せずに公共交通を利用出来るのではないでしょうか。この記事で作成する運行頻度図は、このような公共交通の状況を直感的に表現するものです。交通事業者の戦略立案のほか、自治体が行う交通計画や住民ワークショップなどでの活用が期待されます。

動作環境
この記事は、以下の環境で動作確認をしております。これらのインストール方法や基本的な使い方は別途入門書などをご参照ください。それぞれ、多少バージョンが違っても動作すると思います。未確認ですが、各ソフトウェアは複数のOSに向けて提供されているので、WindowsやLinuxでもほぼ同様に動作すると思います。
- PostgreSQL 12.1
- PostGIS 3.0.0
- QGIS 3.10.1
- macOS Catalina 10.15.3
下準備: GTFSファイルの準備
この記事では、例として公共交通オープンデータセンターより提供されている東京都交通局バス関連情報(GTFS-JP形式)を利用しますが、GTFS-JPに準拠したGTFSファイルならば同様の運行頻度図が作成できます。バス停情報に関しては、stops.txtが乗り場単位で整備され、データ構造に停留所(親)と乗り場(子)という親子関係が設定されていることを前提としています。停留所(親)しか含まないデータでは、SQLによる集計処理がより簡易になります。乗り場(子)しか含まないデータや、複数のGTFSを統合して扱う場合は、複数の乗り場情報を名寄せして、単一の停留所(親)に所属するように事前に処理する必要がありますが、データの特性を見極めながら処理する必要があるため、この記事では具体的な方法は解説しません。
手順1: GTFSファイルをPostgreSQLに投入する
運行頻度図を作成する大前提として、GTFSファイルをオープンソースのリレーショナルデータベースであるPostgreSQLに投入します。緯度経度データの処理のために、PostGISも使えるようにします。
GTFSDBのインストール
データベースへの投入には、GTFSDBというツールを用います。これはPythonを利用したデータベースへの投入ツールで、そのビルドのためにBuildoutというツールを用います。これらをドキュメントに従ってインストールします。
$ pip3 install zc.buildout
$ buildout --version
buildout version 2.13.2
$ git clone https://github.com/OpenTransitTools/gtfsdb.git
$ cd gtfsdb
$ buildout install prod postgresql
この時点で、bin/gtfsdb-loadとしてGTFSDBが実行できるようになります。
データベースの初期化
PostgreSQLに新しいデータベースを作成し、PostGISも使えるように拡張機能を設定します。データベース名は適宜読み替えてください。
$ createdb gtfs-tobus
$ psql -d gtfs-tobus
gtfs-tobasu=# create extension postgis;
CREATE EXTENSION
gtfs-tobasu=# \q
投入の実行
作成したデータベースに対して、ダウンロードしたGTFSファイルを投入します。データベースのURLにユーザ名やデータベース名を設定するので、適宜読み替えてください。このコマンドの実行が完了すると、GTFSがPostgreSQLに読み込まれたことになります。GTFSファイルのサイズによっては完了まで数分間お待ちください。
$ bin/gtfsdb-load --database_url postgresql://[user]@localhost:5432/gtfs-tobus --is_geospatial GTFS.zip
ちなみに、PostgreSQLのURLは一般的に以下のように表現されます。自身の環境に合わせてください。
postgresql://[user[:password]@][netloc][:port][,...][/dbname][?param1=value1&...]
手順2: SQLで区間ごとの運行本数を集計
停留所間のラインとその間を走る公共交通機関の本数を集計したテーブルを作成します。
最初に、集計用に新しいスキーマ(名前空間・ディレクトリのようなもの)を作成します。 ここまで登録されているデータはpublicというスキーマに登録されていると思いますが、混同を防ぐために、新しく集計用のsummaryスキーマを作成します。
CREATE SCHEMA summary;
対象日のstop_timesを抽出してテーブルに格納
運行頻度図作成の対象とする日のservice_id一覧は以下の方法でuniversal_calendarテーブルから取得出来ます。GTFSでは、本来calendar.txt及びcalendar_dates.txtを解釈することで日付に対応したservice_idを取得するのですが、GTFSDBがデータ投入時にこの手順を実行し、universal_calendarというテーブルに日付ごとのservice_idを格納しているので、シンプルな検索で対象日のservice_id一覧が取得出来ます。
SELECT
service_id
FROM
universal_calendar
WHERE
"date" = '2020-02-12'
;
対象日に紐付いたstop_timesのみを抽出し、summary.stop_times_filteredというテーブルに格納します。WHERE節には、先ほどのservice_id一覧取得のSQLをサブクエリとして組み込み、内部結合(INNER JOIN)したtripsテーブルのservice_idを用いて絞り込みます。また、stop_timesテーブルのstop_idには乗り場(子)のIDが格納されているのですが、後に必要になるため親(parent_station)である停留所IDをstopsテーブルを内部結合して取得します。
DROP TABLE IF EXISTS summary.stop_times_filtered;
CREATE TABLE summary.stop_times_filtered
AS
SELECT
stops.parent_station AS parent_stop_id,
stop_times.*
FROM
stop_times AS stop_times
INNER JOIN
trips AS trips
ON trips.trip_id = stop_times.trip_id
INNER JOIN
stops AS stops
ON stops.stop_id =stop_times.stop_id
WHERE
service_id IN (
SELECT
service_id
FROM
universal_calendar
WHERE
"date" = '2020-02-12'
)
;
隣接停留所ペアのテーブルを作成
停車時刻を意味するstop_timesをtrip_idごとにグループ化しstop_sequence順に並べることで、便単位の時刻表が出来ます。ここでは、停車時刻の情報を停留所と停留所の区間の情報に読み替えます。ここで用いているLEAD()はWindow関数と呼ばれている関数の一つで、ある条件で並べたときのn行後の値を得ることが出来ます。ここでは、trip_id単位で区切り、 stop_sequenceの順に並べたときの1行後のstop_id, parent_stop_idの値を得ています。なお、終点のstop_timesには次の行がないので、next_stop_id, next_parent_stop_idにはデフォルト値としてnullが設定されます。
DROP TABLE IF EXISTS summary.stop_pairs;
CREATE TABLE summary.stop_pairs
AS
SELECT
stop_times.stop_id AS prev_stop_id,
stop_times.parent_stop_id AS prev_parent_stop_id,
LEAD(stop_times.stop_id, 1, NULL) OVER(PARTITION BY trip_id ORDER BY stop_sequence) AS next_stop_id,
LEAD(stop_times.parent_stop_id, 1, NULL) OVER(PARTITION BY trip_id ORDER BY stop_sequence) AS next_parent_stop_id,
stop_sequence,
trip_id
FROM
summary.stop_times_filtered AS stop_times
order by
trip_id,
stop_sequence
;
ここまでで出力されたデータは、以下のようなテーブルになります。全ての便の停留所の区間ごとに、前の停留所IDと乗り場ID、次の停留所IDと乗り場IDが格納されていることが分かります。なお、終点においては次の停留所、乗り場がデフォルト値のnullになります。
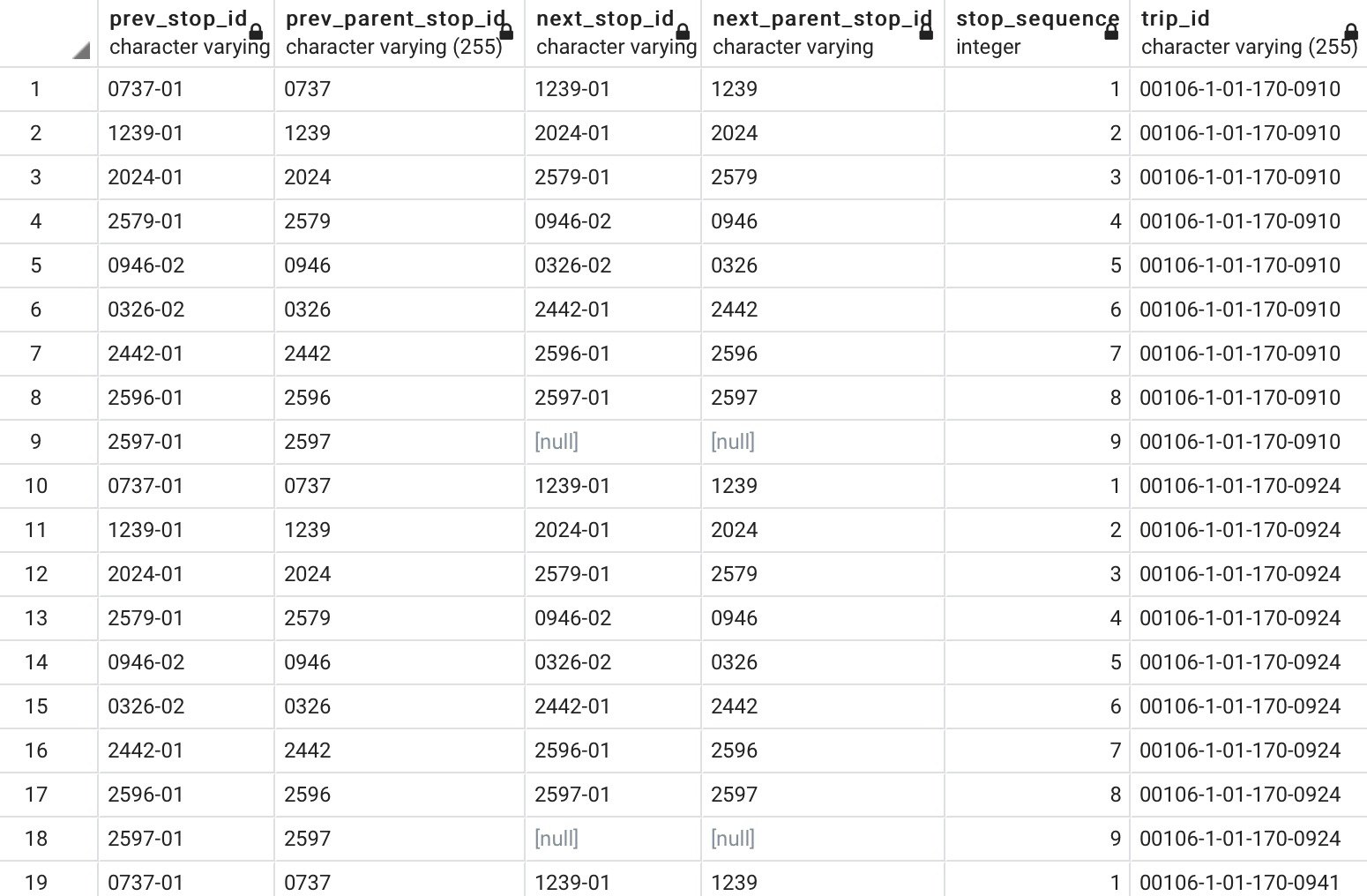
隣接停留所ペアで集計し、区間ごとの本数を格納するテーブルを作成
前停留所ID(prev_parent_stop_id)、次停留所ID(next_parent_stop_id)で集計(GROUP BY)し、停留所区間ごとの運行本数を求めます。WHERE節では、終点にあたるnullが設定されているデータを除去し、区間のみを抽出しています。
DROP TABLE IF EXISTS summary.freq;
CREATE TABLE summary.freq
AS
SELECT
prev_parent_stop_id,
next_parent_stop_id,
count(*) as cnt
FROM
summary.stop_pairs
WHERE
next_parent_stop_id IS NOT null
GROUP BY
prev_parent_stop_id,
next_parent_stop_id
隣接停留所ペアに地理形状を付与する
停留所間の情報を地図化するために、対応する地理形状を紐付けます。地理形状を表すshapes.txtを含むGTFSデータの場合は、道路に沿ったデータを作ることも可能ですが、ここでは、簡易な方法として停留所間の直線を地理形状に設定しています。PostGISのST_MakeLine()関数に前停留所の位置情報、次停留所の位置情報を渡し、同じくPostGISのST_SetSRID()関数で適切なSRID(GPSに使われるWGS84を表す4326)を設定し、直線のデータを作成しています。
DROP TABLE IF EXISTS summary.freq_line;
CREATE TABLE summary.freq_line
AS
SELECT
freq.*,
prev_parent_stops.stop_name AS prev_name,
next_parent_stops.stop_name AS next_name,
ST_SetSRID(ST_MakeLine(prev_parent_stops.geom, next_parent_stops.geom),
4326) AS geom
FROM
summary.freq freq
INNER JOIN
stops AS prev_parent_stops
ON prev_parent_stops.stop_id = prev_parent_stop_id
INNER JOIN
stops AS next_parent_stops
ON next_parent_stops.stop_id = next_parent_stop_id
;
ここまでの結果として、以下のようなテーブルが得られます。前後バス停のIDと名称、運行頻度、直線を表すPostGISの地理データが格納されています。
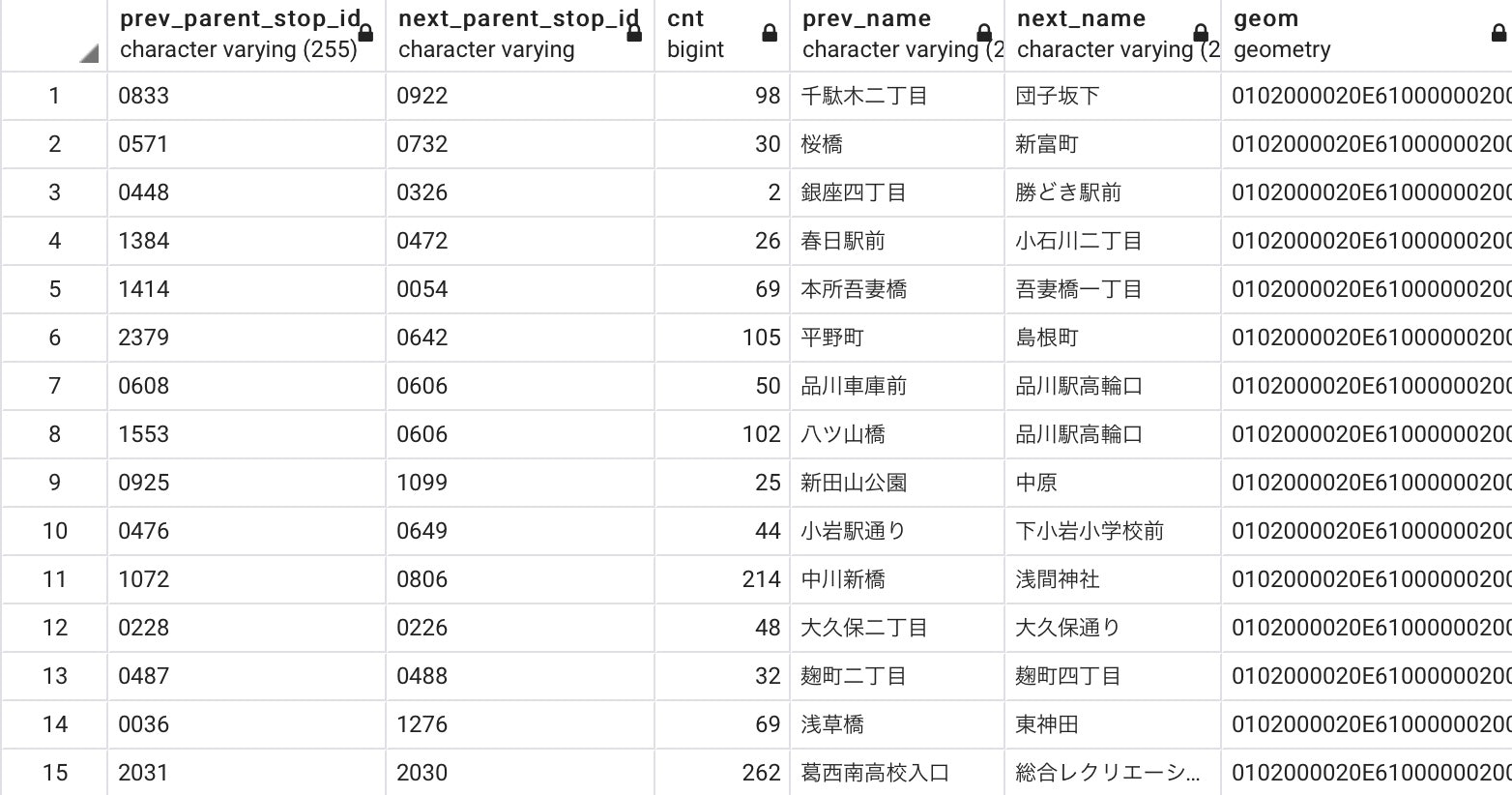
手順3: QGISにデータを読み込み整形する
QGISを起動し新規プロジェクトを作成した後、以下の手順で運行頻度図の作成を進めていきます。トラブルを防ぐため、作業中は適宜プロジェクトを保存して下さい。
QGISにおいて地理院タイル地図を利用可能にする
国土地理院より提供されている地図データを、今回作成する運行頻度図の背景図として利用します。メニューの「レイヤ」→「データソースマネージャ」→「ブラウザ」を開き、「XYZ Tiles」を右クリックし「新しい接続」を選びます。
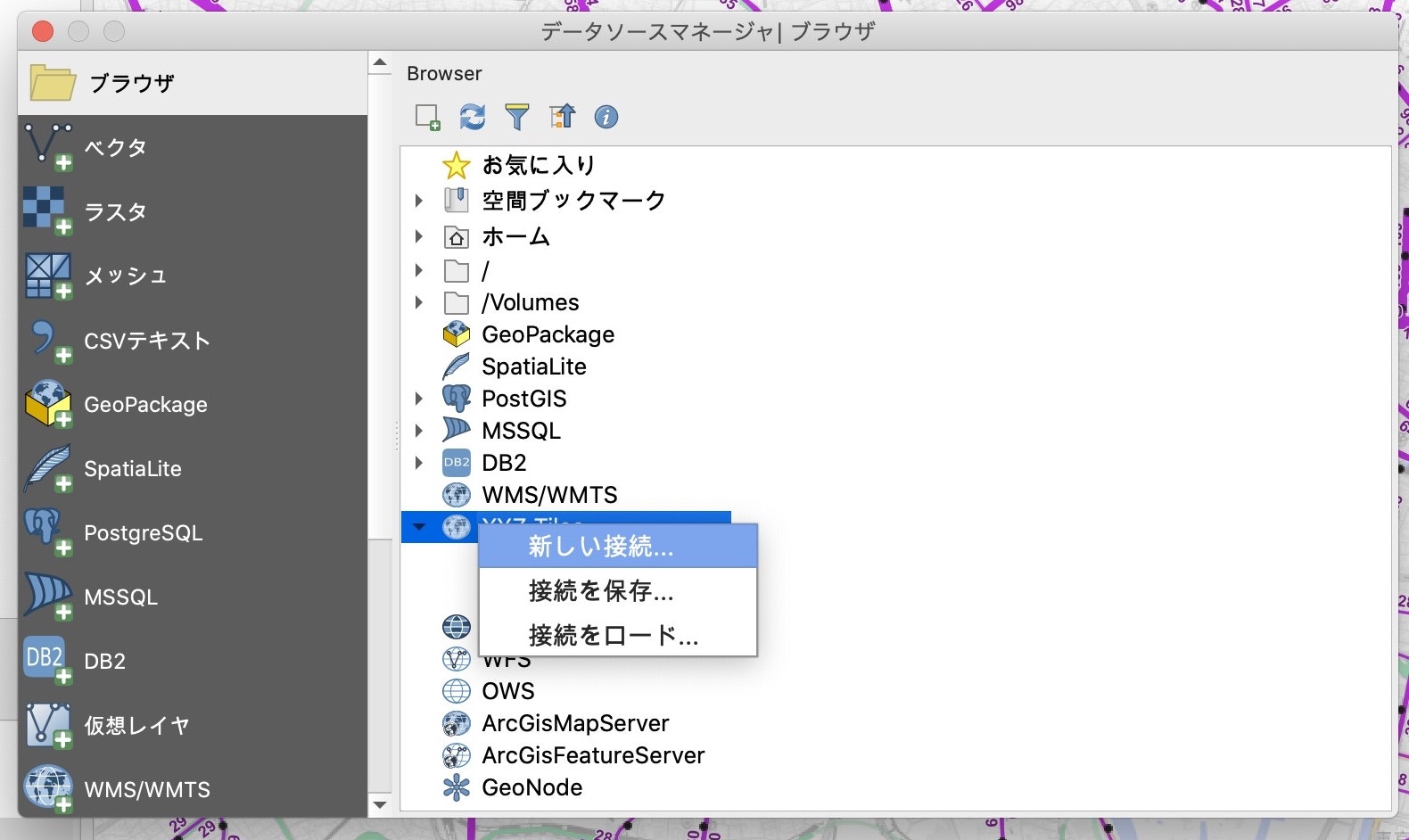
名前を「地理院地図(淡色)」とし、URL欄にhttps://cyberjapandata.gsi.go.jp/xyz/pale/{z}/{x}/{y}.pngを設定しOKを押します。
データソースマネージャに追加された「地理院地図(淡色)」をダブルクリックすることで、地理院地図が表示されます。うまく表示されない場合は、拡大ボタンなどを用いて縮尺を調整することで表示が出来るようになることがあります。マウスを用いて対象地域の付近を拡大します。タイル地図を利用するので、レンダリングにおける座標参照系はEPSG:3857を使うのがいいでしょう。

バス停・運行頻度線レイヤーを追加する
PostgreSQLの接続を設定します。メニューの「レイヤ」→「データソースマネージャ」→「ブラウザ」を開き、「PostgreSQL」を選択し「新規」を押します。

以下のような設定で、新しいPostGIS接続を作成し、入力後「OK」で確定します。
名前:任意の名称、ホスト:localhost、ポート:5432、データベース:gtfs-tobus

新たに作成したPostGIS接続が選択された状態で、(1)接続 を押します。PostgreSQLのユーザ名、パスワードを入力します。接続に成功すると、publicとsummaryのスキーマ、その中にいくつかのテーブルが表示されます。この中から(2)summary.freq_lineテーブルを選択して (3)追加、(4)public.stopsテーブルを選択して (5)追加します。

QGIS画面にバス停と路線が表示されます(色はランダム)。

この状態では、停留所(親)と乗り場(子)双方が表示されているので、停留所のみ表示するように設定します。レイヤの「stops」を右クリック→プロパティをクリックしレイヤプロパティの画面を呼び出します。
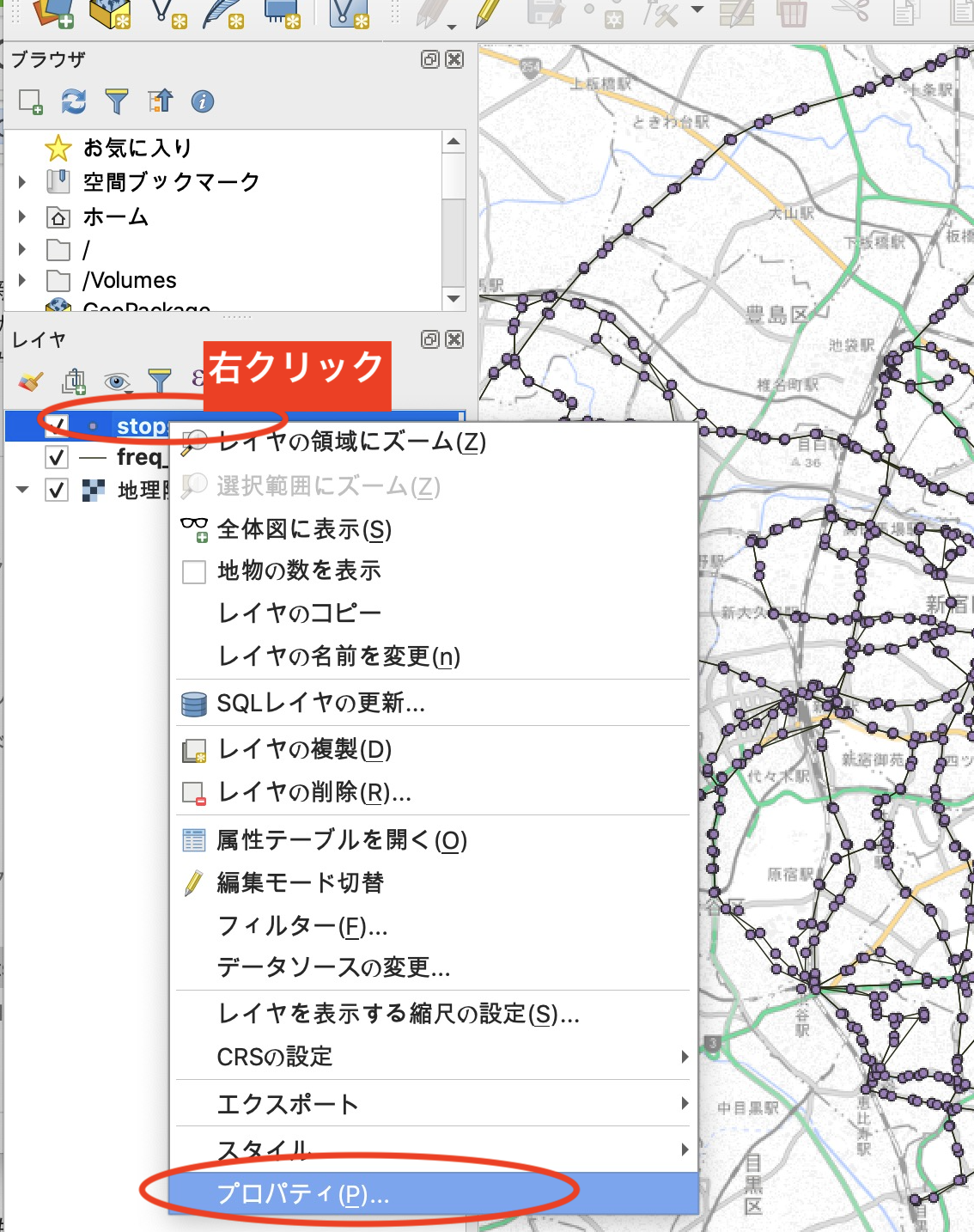
レイヤプロパティの「ソース」から「クエリビルダ」を呼び出します。
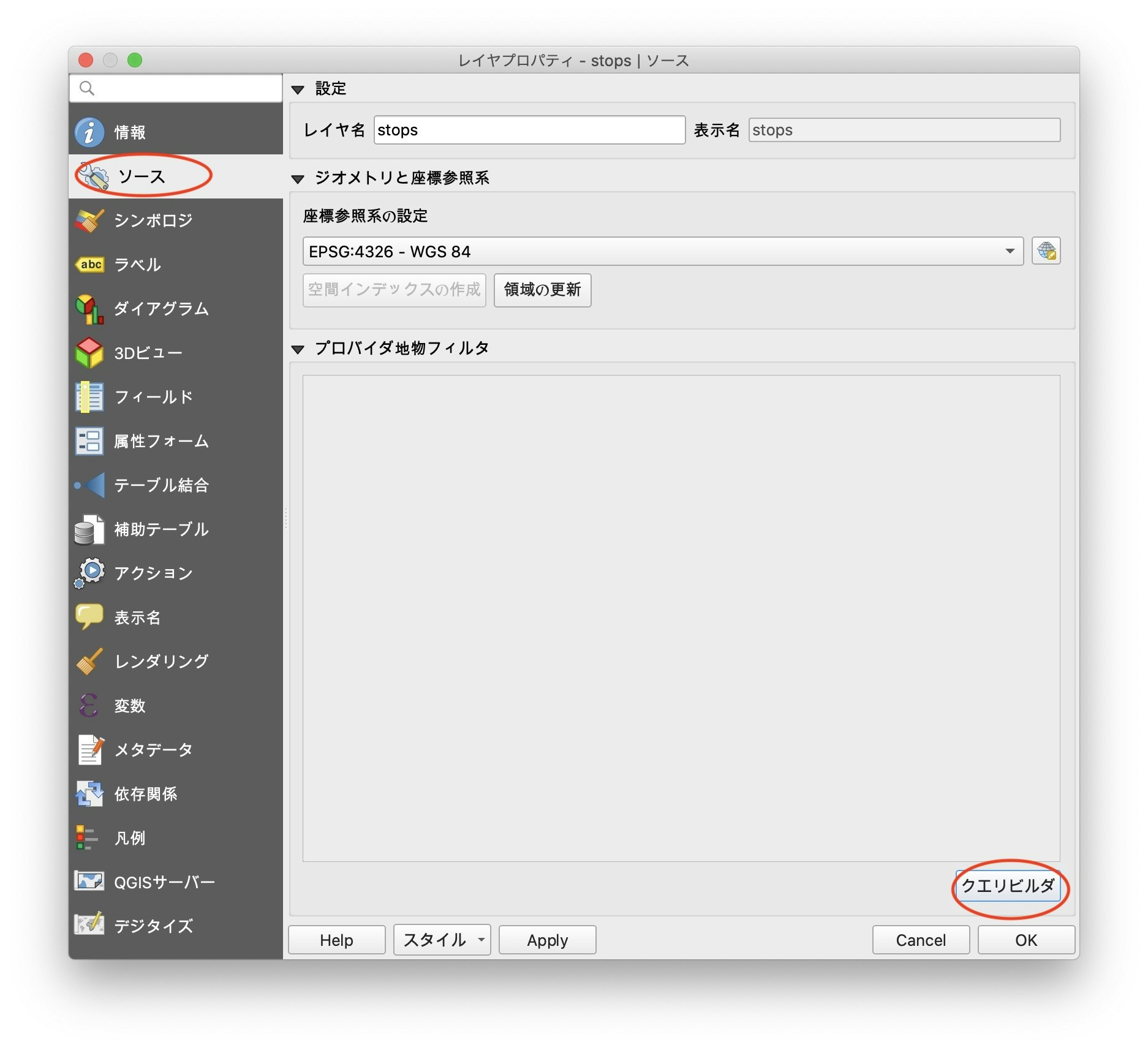
クエリビルダの「プロバイダ特有のフィルタ式」に"location_type" = 1と入力し、OKでウィンドウを閉じます。このまま手入力も可能ですが、右上の「フィールド」欄からlocation_typeをクリックし、「演算子」から*=*を入力することで、ミスなく入力が出来ます。
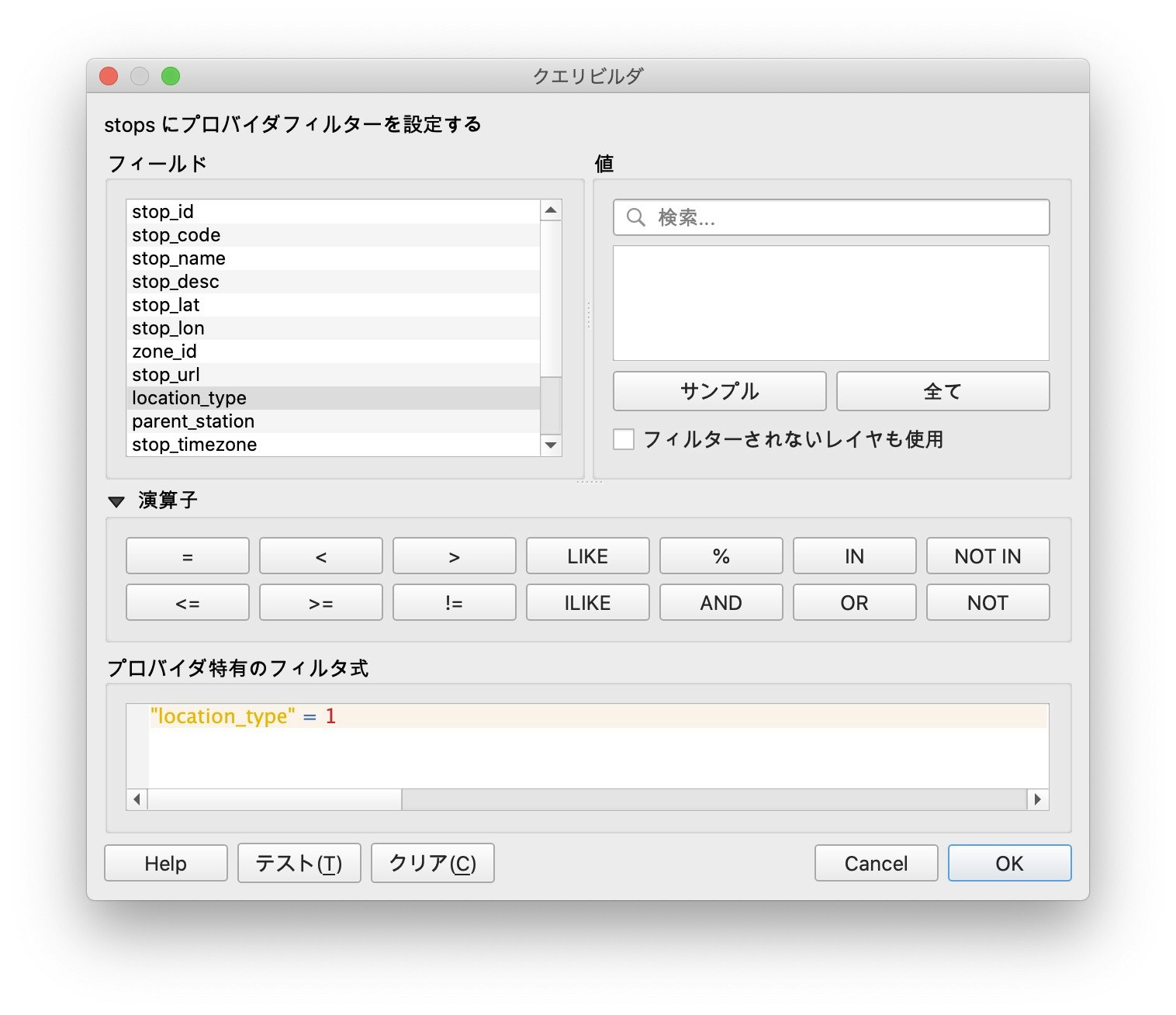
GTFSのlocation_typeフィールドには、停留所(親)ならば1が、と乗り場(子)ならば0が入力されているので、これを設定することで停留所のみがQGISの画面上に表示されるようになります。
バス停のスタイル設定
バス停の表示を調整します。レイヤの「stops」を右クリック→プロパティをクリックしレイヤプロパティの画面を呼び出し、「シンボロジ」を選択します。「シンプルマーカー」を選択し、[大きさ]を1.5、[塗りつぶし色]を黒、[ストロークスタイル]をペンなしに設定してOKを押します。

バス停の描画スタイルが変わり、黒い点で表示されるようになります。
次にバス停のラベルとしてバス停名が表示されるように設定します。レイヤの「stops」を右クリック→プロパティをクリックしレイヤプロパティの画面を呼び出し、「ラベル」を選択します。「ラベルなし」を「単一定義(single)」に切り替え、値としてstop_nameを選択します。フォントやスタイル、サイズや色を適宜選択してOKを押します。

設定したフォントでバス停名が表示されることが確認できます。
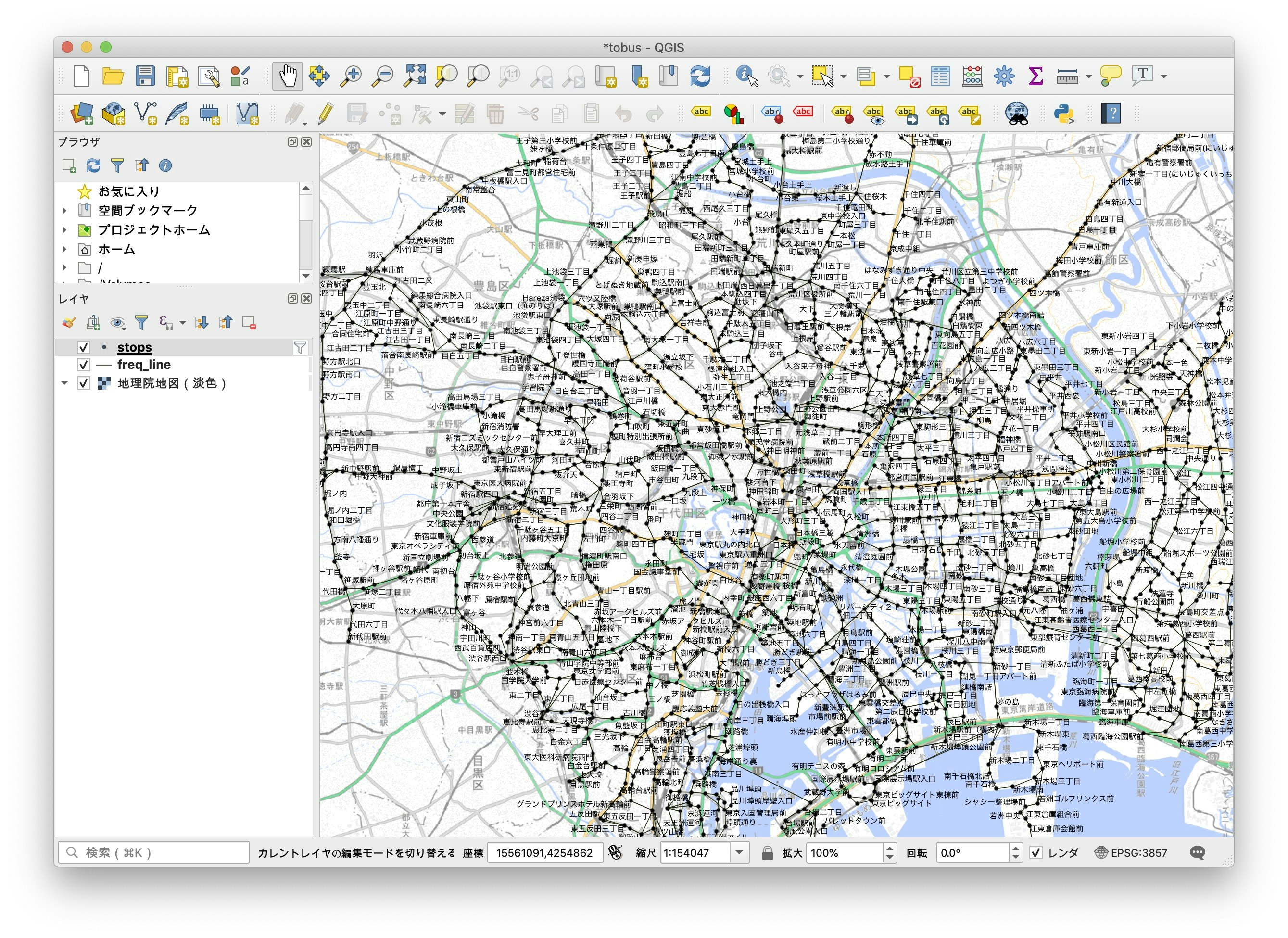
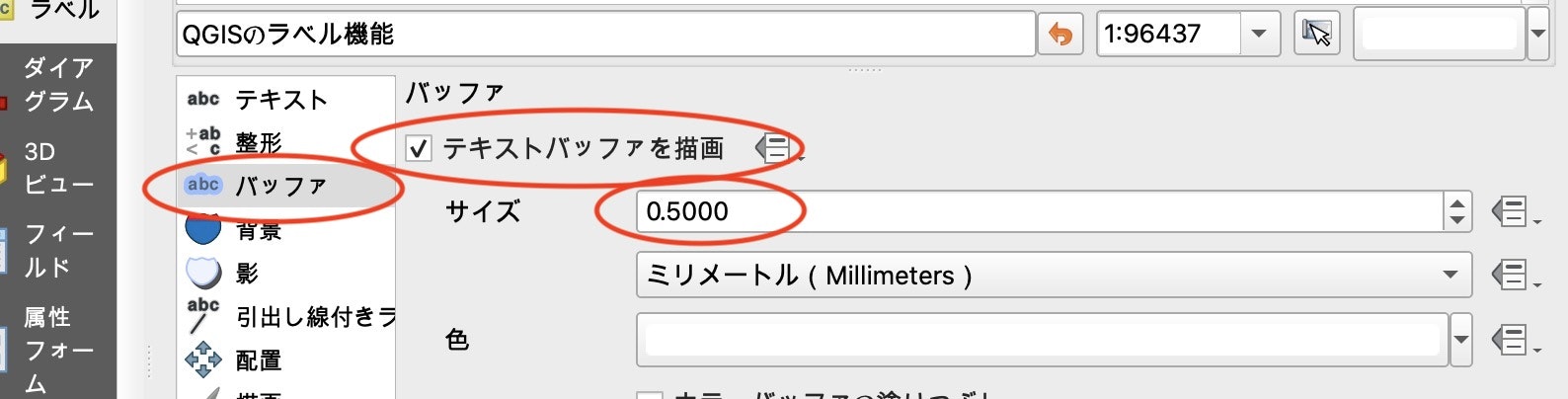
さらにこのスタイルを改良します。再度レイヤプロパティの画面から「ラベル」を選択し、[バッファ]-[テキストバッファを描画する]をチェックします。文字の周辺が設定した色で縁取りされ、地図上でラベルが判読しやすくなります。

さらに、ラベルが表示される条件を設定し、拡大したときだけ表示されるように調整します。[描画]-[縮尺に応じた表示設定]をチェックし、1:50000を縮小側の限界に設定してOKを押します。

この設定により、1:50000より拡大したときだけ、白で縁取られラベルが表示されるようになりバス停名が見やすくなります。
運行頻度線のスタイル設定
次に、運行頻度線の表示を調整します。レイヤの「freq_line」を右クリック→プロパティをクリックし、レイヤプロパティの画面を呼び出し、「シンボロジ」を選択します。「シンプルライン」を選択し、色を青色など分かりやすい色に設定します。
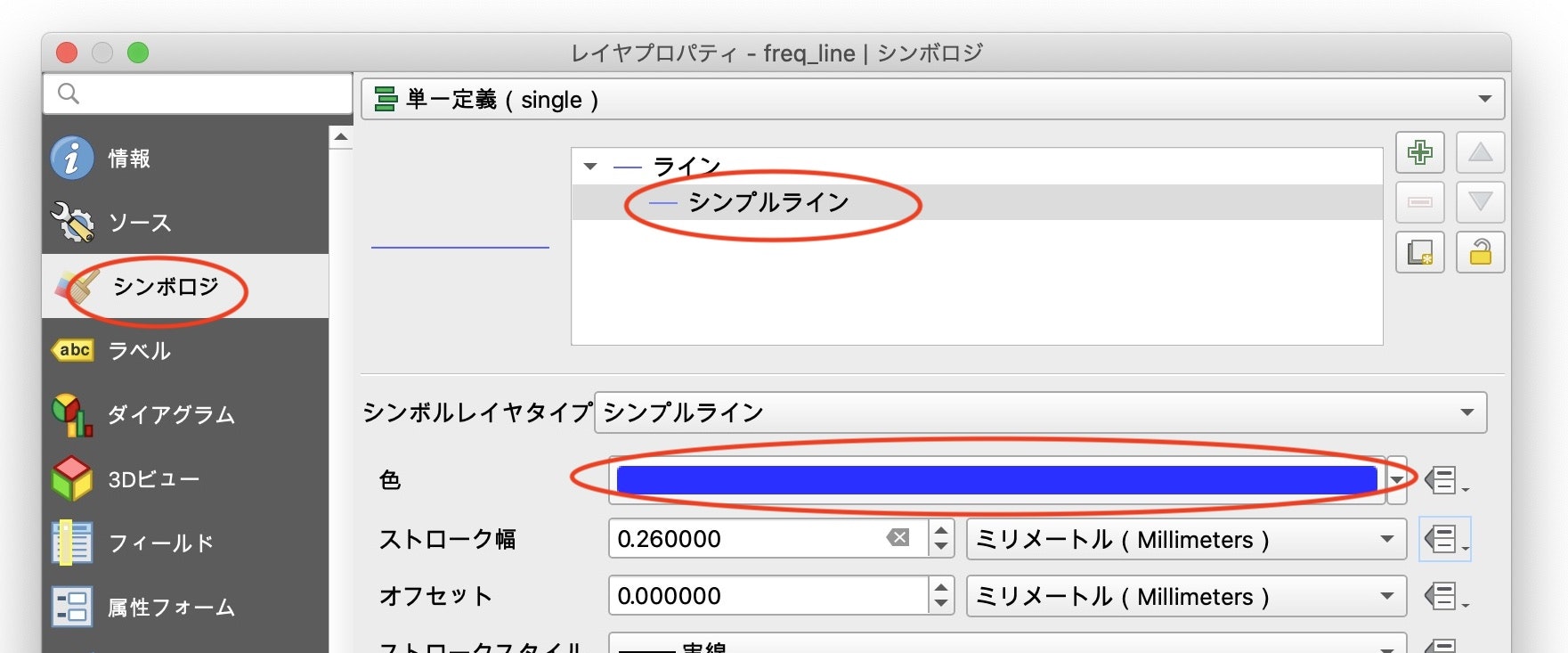
次に、ストローク幅を運行本数に応じた幅になるように設定します。ストローク幅設定欄の右端にあるアイコンをクリック、出てきたメニューから「編集」を選択し、式文字列ビルダを呼び出します。
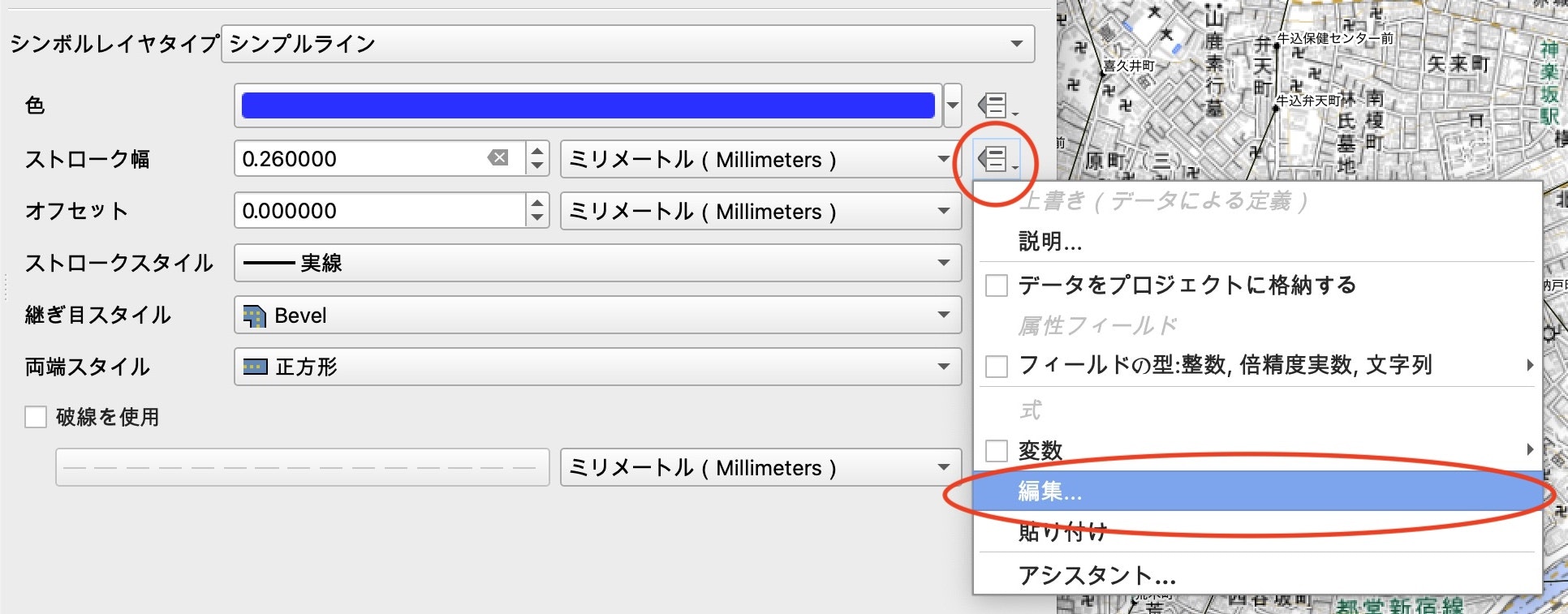
式入力欄に線幅の計算式を入力します。運行頻度がcntという変数に格納されているので、この値から線幅を計算します。ここでは、("cnt"^0.8) * 0.04と入力してOKを押します。^(ハット)はプログラミング言語において階乗を表現します。本数と線幅を比例にせず、0.8乗することで、頻度が多い路線も少ない路線もそれぞれバランス良く表示しています。

ここまでの設定で、運行頻度に応じた線幅で路線が表示されるようになります。

運行頻度のラベル設定
最後に、運行頻度の数値を線に付随するラベルとして表示します。再びレイヤの「freq_line」のレイヤプロパティの画面を呼び出し、「ラベル」を選択します。「単一定義(single)」を選択し、値として「cnt」を選択します。フォントやサイズも適宜設定します。

色設定欄の右端のメニューをクリックし、「編集」を選択、式文字列ビルダを表示します。
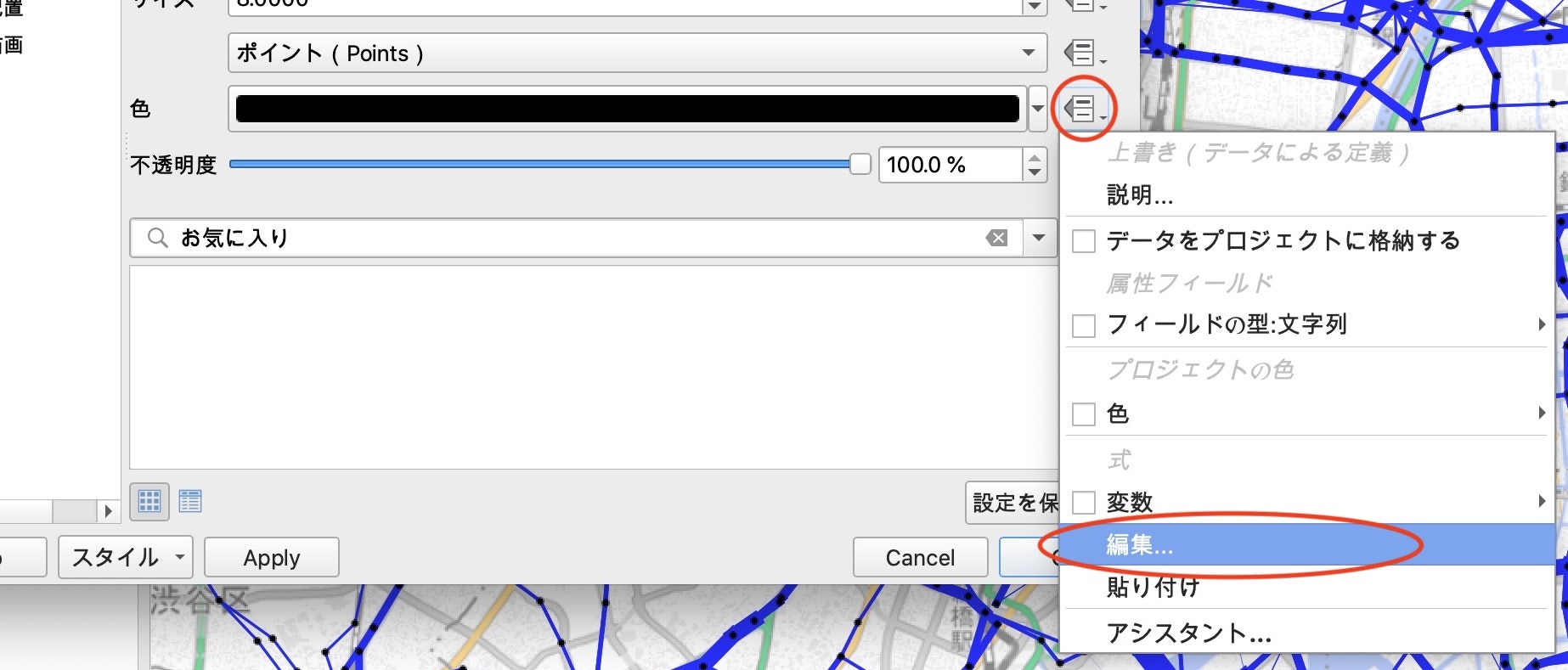
線の色を少し暗くした値を設定するために、darker(@symbol_color, 150)と入力してOKを押します。

[バッファ]-[テキストバッファを描画する]をチェックし、サイズを「0.5」にします。
ラベルが路線沿いの左側に表示されるように、[配置]-[線の向きに依存した位置]をチェックします。

ここまでの手順で、運行頻度図が完成しました。このあと、色や太さなどのパラメーターを調整しながら、その地域にふさわしい運行頻度図を作って下さい。完成した運行頻度図は、QGISのエクスポート機能で画像やPDFなどに出力することも出来ます。

運行頻度図の作成:応用編
地域の交通の実態を表現するためには、ここまで解説した技術を応用して、より高度な運行頻度図をつくる必要が出てくる場合があります。具体的な作り方に関してはページの関係で解説出来ないですが、ヒントとなりそうな3つの例を以下に示します。
Shapeを使った運行頻度図
GTFSDBによって作成されるpatternsテーブルに、GTFSファイルに含まれるshapes.txtに登録されている運行経路の形状(shape)がPostGISのLINESTRING(地理的な折れ線)として格納されています。これをバス停区間ごとに切り出すことで、バス停間を直線ではなく実際の道路形状に沿った形で運行頻度図を作成出来ます。都市域を拡大して捉えたいときなどは、この精度の運行頻度図があった方がいいでしょう。
実際に作成したShapeを使った場合の都バスの運行頻度図(平日)の例を以下に示します。

LINESTRINGの切り出しには、PostGISのST_LineLocatePoint()関数でバス停のPOINTがLINESTRINGのどの位置に最も近いかを求め、それを引数としてST_LineSubstring()関数で実際に切り出しを行います。実際の作業においては、二つのバス停間を結ぶLINESTRINGは一種類とは限らないため、代表するLINESTRINGを選択する必要があるなど様々な課題があるため、ここでは詳細は説明しません。
小数点を考えた運行頻度図
地域によっては、バスが来るのは特定の曜日だけ、など1日1便も走らないエリアもあります。このような場合は、特定の1日の本数を図示するより、ある期間の平均本数を示した方が地域の公共交通の理解に役立ちます。例では、宮崎県串間市のGTFSデータから、この地域の路線バスの1日あたりの平均本数を示しています。山間部では、1日に1便も走っていないことがよく分かります。

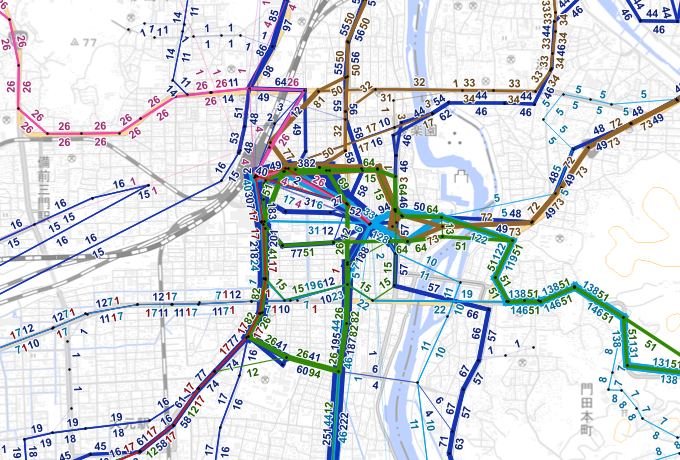
複数事業者を色分けした運行頻度図
複数事業者が競合するエリアにおいては、事業者ごとの領域やサービス水準を知りたい場合があります。こうした場合は、運行頻度図を事業者ごとに色分けして重ねることで地域全体の公共交通の状況を把握することが出来ます。例では、6事業者が競合する岡山市内のバスの状況を図示しています。
まとめ
この記事では、運行頻度図の作図方法を解説しました。地域の公共交通の状況を直感的に把握するツールとして有効で、行政の職員などにこの図を見せるとダイヤや路線計画に込めた思いをいろいろと引き出せるなど、コミュニケーションツールとしての機能も実感しています。GTFSを利用することで、データさえあれば各地域でほぼ共通の方法で作れるようになったので、是非、各地で運行頻度図を作成してみて下さい。