スクラムサインの西森です。
今回は基礎調査ということで時系列のデータの異常検知に関するサーベイ論文を読みました。この記事はそのまとめになります。
タイトル Anomaly Detection of Time series
著者 Deepthi Cheboli
時期 2010 May
リンクはこちらです。
https://conservancy.umn.edu/bitstream/handle/11299/92985/Cheboli_Deepthi_May2010.pdf%C2%A0?sequence=1
目次
異常検知とは
時系列データの異常検知
・活用領域
.問題設定
・ラベルの有無
・データの種類
手法
・変換手法
・検知手法
異常検知とは
異常検知は、データセット中の他のデータと一致していない観測結果、予期しないパターンなどについてデータマイニングを利用して識別することを指します。 異常検知でいう異常とは、正常のパターンとして明確に定義された概念に準拠しないデータパターンのことです。
上記の正常のパターンを定義する方法の違いが、手法の違いになってきたりします。
異常検知にはいくつか種類があり、データの中での特異値を見つける外れ値検出、連続データの中で異常な変化が起こった点を見つける変化点検知、そのデータが異常であるかどうかを判断する、異常状態検知などがあります。
現実世界においてデータの異常というのは看過できない不具合を反映していることが多いので(心肺停止とか)非常に研究が盛んな領域です。
時系列データの異常検知
現実世界では、連続値を記録して、その値から現実世界における不具合を検出したいという願望がそこかしこで沸いています。多くの場合その不具合は何らかの異常値としてデータに現れているため,
時系列データの異常検知は特に盛んに研究されています。他の領域の異常検知と比べると、その値自体が外れ値であるわけではないが、前後の文脈を考えると異常とみなされる異常(contextual anomaly)を考慮する機会が多いです。
・活用領域
幾つもありますが、代表的なものを挙げると飛行機のセンサーの情報からフライトの際に起こる異常を検知するシステムなどに使われています。
・問題設定
時系列データの異常検知には3つの問題設定が存在します。
1Contextual anomalies
前後のデータを考慮して異常だと判断されるデータ点を検知します。
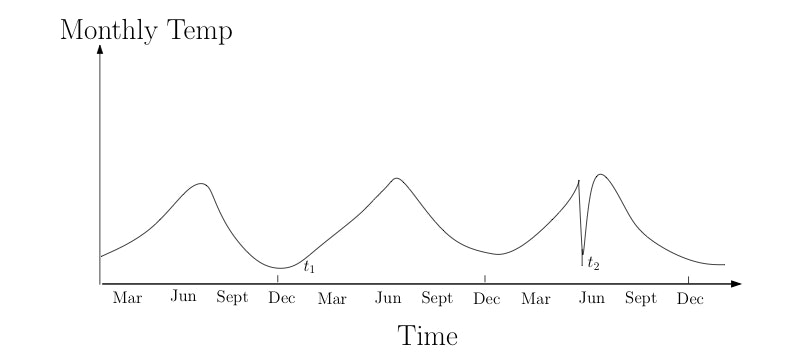
2 anomalous subsequence
時系列データの中で異常と判断されるサブシークエンス(部分区間)を検出する。
3 anomalous dataset
与えられたデータセット全体が異常かどうかを判断する。
・ラベルの有無
訓練データに正常、異常のラベリングがされているかどうかの度合いで、3種類に分類できる。
Supervised → 正常、異常、どちらもラベリングされている状態(現実でどちらもラベリングできるケースは少ない)
Semi-supervised → 正常データのみラベリングされている。
Unsupervised → どちらもラベリングされていない(ただし、多くのunspervisedを前提とした手法は、異常データというのは正常データに比べると数かかなり少ないということを前提にしている。つまり訓練するデータセットを疑似的に正常データとみなしている。)
・時系列データの種類
時系列データには解析を行う際に考慮すべきな特有の特性が二つある。
1周期性(データに周期があるかどうか)
2同期性(複数の時系列データを扱う際に、そのデータが同期しているかどうか)
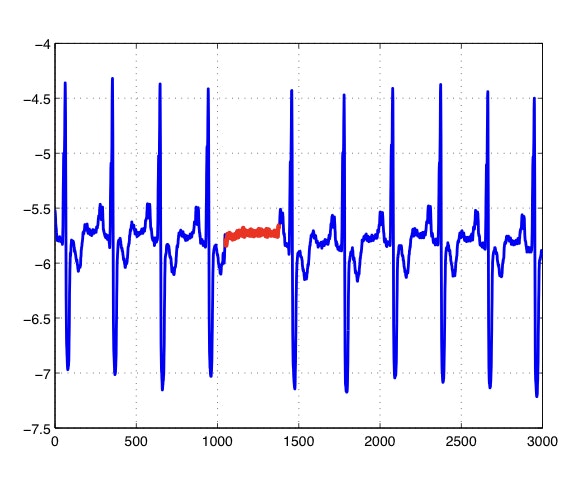
 周期性、同期性共にあるデータの例
周期性、同期性共にあるデータの例
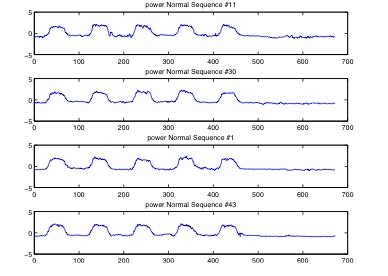
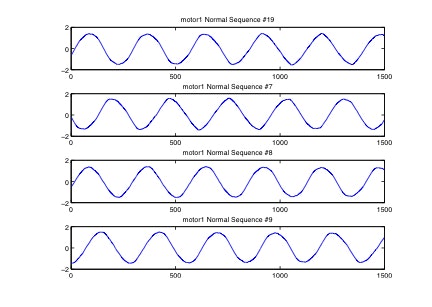 周期性はあるが同期生はないデータの例
周期性はあるが同期生はないデータの例
手法
論文では二種類の手法が紹介されていました。時系列データにおいてはいわゆる前処理が非常に重要です。今回のTransformationはこの前処理にあたる部分かと思われます。
1 与えられた時系列データをより解析しやすいデータに変換する手法(Transformation)
2 時系列データから異常を検知する手法( Detection)
Transformation
1 Aggression
説明
データをよりよく表現している値に圧縮する。代表的な手法としてはPAA(piecewise aggregation apporoximation)が挙げられる。
次元を削減してくれるため、計算効率が上がるというメリットがあるが、それによって大事な特徴を隠してしまう危険性もある。
PAA
長さnの時系列データをw次元のベクトルに変換することを考える。
以下の式では長さnの時系列データCをw次元のベクトルに変換している。
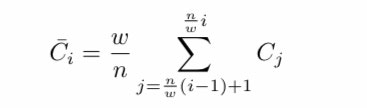
つまり,データを等間隔に w 個のフレームに分け, それぞれのフレーム内でのデータの平均をとることで, n 個ある時系列データを w 個の要素に簡約することができる.
2 Signal Processing
説明
信号処理の技術(フーリエ変換、ウェイブレット)などを用いて周波数領域に変換して解析を行う。
最もよく使われるのはハール変換
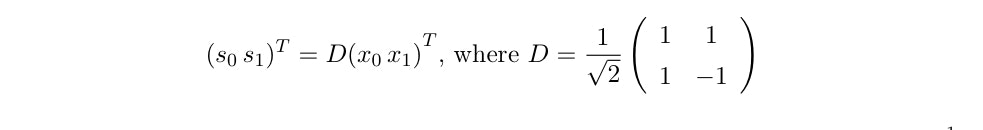
3 Discretization
説明
時間の関数として変動する値のマックスからミニマムまでを複数の領域に分けて、各データをそのデータが属している領域に割り当ててアルファベットを振るイメージ

よく使われている手法はSAX
SAXについての説明はこちらです。
https://ipsj.ixsq.nii.ac.jp/ej/index.php?action=pages_view_main&active_action=repository_action_common_download&item_id=109658&item_no=1&attribute_id=1&file_no=1&page_id=13&block_id=8
Detection
1 window based
説明
トレーニングデータをn個の窓に分割、テストデータはその各窓を少しずらすことで得る。異常度はテストデータと正常データの距離によってて各窓ごとに図られて集計される。(トレーニングデータとの類似度で異常度合いを測る、距離の概念が適用可能であるということを前提にしている。)
メリット
・上述のどの問題設定にも対応できる
デメリット
・窓の幅を決定するのが困難
・窓をずらす幅をきめることが非常に難しい。(幅が狭いと、計算コストがかかり、幅が広いと、ずらす幅以内単位で起きている異常を検知できない。)
・計算コストが非常に大きい
2 prediction based
説明
時系列データの分野で最も活発に研究されている。
ある確率的なプロセスから正常データは生成されていて、異常データはそのプロセスにフィットしないということを前提にしている。
①確率モデルをトレーニングして、時間tの状態からt+1の状態を予測するようにする。
②その予測に基づいて、テストデータを予測して、予測との誤差を閾値を設けて異常度とする
このプロセスが一般的。
代表的な手法としては
MovingAverage, Autoregression, ARMA, ARIMA, Kalman Filter
などが挙げられる。
メリット
・時系列データの特性を反映しやすい手法であるため、性能が良い
・どの問題設定にも対応できる。
・想定する分布が正しいと高い精度を発揮する。
デメリット
・自己回帰などの場合window basedの手法と同じように、予測に使う区間を決定するのが難しい。(異常を含んだ区間を設定しないと、適切に異常を検知できない)
3 hidden Markov model based
説明
時系列データはある隠れ状態の時系列によって生成されており、その時系列はマルコフ的に作り出されているということを前提とした手法である。
①与えられたデータから隠れマルコフモデル(HMM(λ))を作る。トレーニングデータ(train=O1,O2…)に対して P(train|λ)の確率の最大値ををBaum-Welch re-estimation procedure を使って求め、HMMのparameterを同定する。
②testデータに対してP(Otest|λ)を求めて、確率の低いものを異常とみなす。
メリット
・全ての問題設定に対応できる
デメリット
・隠れ状態の時系列の存在を仮定しているが、その存在がないような時系列データだと、うまく異常検知を行うことができない。
4 segment based
説明
時系列を同質セグメントに分解して、そのセグメント間のFSA(有限オートマン(論理的につながっているい要素たちが、ある状態においてどのような論理の流れを表現するのかというモデル。))をモデルに学習させる。(今回のモデルでは、論理的つながりは遷移確率として表現される。)
以下が有限オートマンの説明のリンクです。
https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=2ahUKEwj-lMqxhvHoAhXCPXAKHRJ9Dm0QFjAAegQIAhAB&url=https%3A%2F%2Fja.wikipedia.org%2Fwiki%2F%25E6%259C%2589%25E9%2599%2590%25E3%2582%25AA%25E3%2583%25BC%25E3%2583%2588%25E3%2583%259E%25E3%2583%2588%25E3%2583%25B3&usg=AOvVaw0fOQ4xY7fgxP189BFnv09U
異常検知の流れ
①トレーニングデータにおいてFSAを作成
②テストデータ( X= X1,X2,,,,Xn)以下のように予測
X1を現在の状態とする、次に X2からXnについて順番に
(a)現在の状態と一致したらそのまま
(b)次の状態(起こりうる)ならそこに遷移
(c)そのどちらでもなければ異常と判断
メリット
・上記の全ての問題設定をカバーしている。
デメリット
・データを同質なセグメントに分割できなかったら失敗する。
・訓練においてもテストにおいても、全点をチェックするので計算コストが多い
まとめ
時系列の異常検知についてのサーベイ論文をまとめてみました。サーベイ論文はやはりある領域の調査においてはまず読むべきものだと再認識できました。異常検知全体に言えることでしょうが、データの性質を把握した上で検知手法を選ぶことが非常に重要で、人間がする作業の中で最も重要なものだと感じました。これはおそらく機械学習全般に言えるのではないかと感じています。まだまだ駆け出しですが、これからもこの論文で学んだことを一つ自分の知識として、学習を進めていきたいです。
課題と今後の展望
今回数学的な知識が乏しかったというのもあり、一つ一つの手法を深掘りするということができませんでした。今後の展望としては実際に今回学んだ手法を試してみるというのが挙げられます。特にprediction based の手法は実装しやすそうだと思うので試してみたいと思います。まだまだ駆け出しですが焦らず目の前の理解に徹していきたいです。