はじめに
時系列データ予測に適用したTransformerの例をあまり見かけないため、代表的な学会で発表された最近の時系列データTransformer論文について読み、適用のポイントをまとめてみました。
(理解不足により記述に誤っている箇所があるかもしれませんが、ご了承ください。)
論文3選(時系列順)
| # | タイトル | 年 | 学会 | 著者 | 概要 |
|---|---|---|---|---|---|
| 1 | Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting | 2019 | NeurIPS | Shiyang Li (UCSB) et al. | 時間的に近い情報と遠い情報を効率良く利用するTransformerを提案 |
| 2 | Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction | 2020 | ECCV | Cunjun Yu (SenseTime), Xiao Ma et al. | 各歩行者の時間的な変化と歩行者間の空間的な関係をそれぞれTransformerでモデル化 |
| 3 | Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting | 2021 | AAAI | Haoyi Zhou (Beihang Univ.) et al. | attentionすべきところを効率良く選択し長期予測を行うTransformerを提案 |
1. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
- 「時系列予測におけるTransformerの局所コンテキストの考慮と空間計算量課題の解決」
- NeurIPS2019
- Paper: https://arxiv.org/abs/1907.00235
- 【概要】 時系列予測にTransformerを適用する課題は、1. 局所的なコンテキストを考慮できないこと(locality-agnostics)、2. 空間計算量がシークエンス長の二乗に比例すること(memory-bottleneck)である。そこでcausal convolutionを使ったself-attention mechanism(ポイント①)と、空間計算量が$O(L(logL)^2)$のLogSparse Transformer(ポイント②)を提案。
- 【ポイント①】 従来のcanonical self-attentionはQuery/Keyにpoint-wiseな値を使うため、局所的な構造(なだらかに変化しているのか、急な変化なのかなど)を考慮できない(Fig.(a),(b))。一方、convolutional self-attentionではQuery/Keyに周辺情報も畳み込むため、局所的な構造を考慮できる(Fig.(c),(d))。本論文では時系列データを扱っているため、convolutionは「前後」の情報ではなく「前」の情報のみを使うcausal convolutionを提案している。
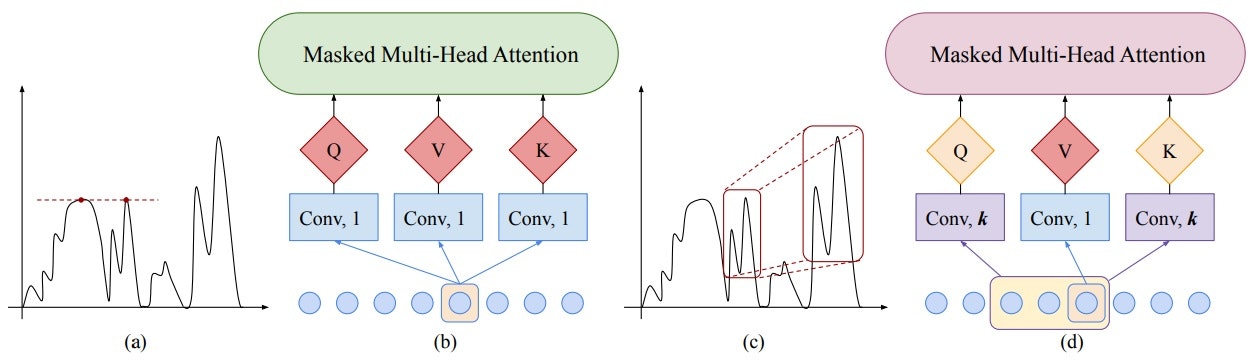
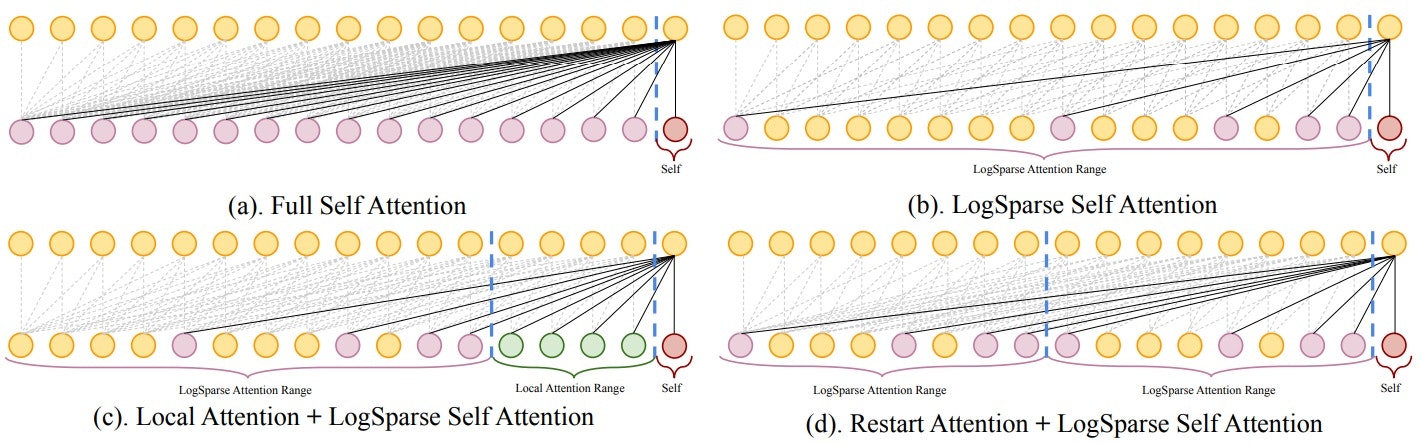
- 【ポイント②】 self-attention layerにおいて、全ての点同士の関係性を見ると$O(L^2)$の空間計算量となる(Fig.(a))。一方、提案するLogSparse self-attentionでは、時間的に近い点は密に、遠い点は疎にとることで$O(L(logL)^2)$の空間計算量に減らすことができる(Fig.(b))。
2. Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction
- 「歩行者軌道予測のための時空間Graph Transformer Network」
- ECCV2020
- Paper: https://arxiv.org/abs/2005.08514
- Code: https://github.com/Majiker/STAR
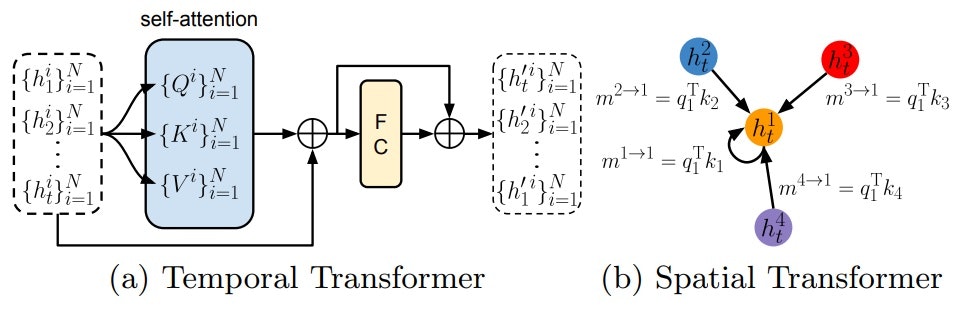
- 【概要】 歩行者の軌道予測をするSTAR(a Spatio-Temporal grAph tRansformer framework)の提案。STARは、Temporal TransformerとSpatial Transformerで構成され、Temporal Transformerは各歩行者を独立に扱って時間的な変化をモデル化し、Spatial Transformerは歩行者間のinteractionをグラフとしてモデル化する。時間的な予測をより滑らかにするため、external graph memoryを導入しTemporal Transformerで更新する。
3. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
- 「Informer: 長期時系列予測のための超効率Transformer」
- AAAI2021 Best Paper
- Paper: https://arxiv.org/abs/2012.07436
- Code: https://github.com/zhouhaoyi/Informer2020
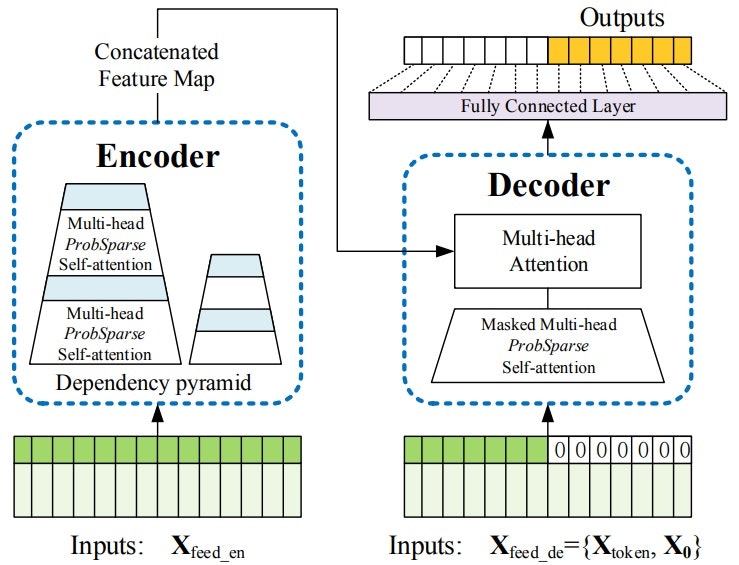
- 【概要】 長期予測にTransformerを適用するためには、シークエンス長$L$の二乗オーダーの空間計算量が課題。そこで、1.$O(LlogL)$の空間計算量であるProbSparse self-attention mechanismの導入(ポイント①)、2.Encoderの省メモリ化を図るSelf-attention Distillingの導入(ポイント②)、3.Decoderの処理高速化のためGenerative Style Decoderの導入(ポイント③)をおこなうInformerというフレームワークを提案
- 【ポイント①】 ProbSparse self-attention mechanismは、QueryとKeyの内積をすべて計算するのではなく、確率$p(k_j|q_i)$の大きいところだけ計算する。考え方としては、一様分布とのKullback-Leibler divergenceの上限値(式)を基に、近似的に確率$p(k_j|q_i)$が大きいかを判断し、サンプリングにより確率が大きいものを抽出する。
- 【ポイント②】 Self-attention Distillingは、Self-attention layerの各層での出力をMaxPoolingにより蒸留(Distilling)し、Encoderの出力するfeature mapの次元を削減することで、省メモリ化を図るものである。
- 【ポイント③】 Generative Style Decoderは、再帰的(auto-regressive)に時系列を予測するのではなく、一気(one forward procedure)に長期の時系列を予測して、処理の高速化を図る。
おわりに
時系列データにTransformerを適用する場合には、下記ポイントをおさえる必要がありそうです:
長期予測をする(長期的なパターンを考慮する)場合、いかに空間計算量を減らして長期的なself-attentionを構築するかが重要
ノード間のインタラクションが発生する場合、時間的な変化と空間的なインタラクションとをそれぞれ考慮する必要があるかもしれない
また、自然言語処理の場合はパターンが決まっており学習済みモデルの転用が容易ですが、時系列データは対象とする事象がそれぞれ異なる(時系列パターンが異なる)ため学習済みモデルの転用が難しい点も発展しにくい点としてあるかもしれないと感じました。
以上です。お読みいただき、ありがとうございました。
参考文献
[1] Shiyang Li (UCSB) et al., Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting, NeurIPS2019
[2] Cunjun Yu (SenseTime), Xiao Ma et al., Spatio-Temporal Graph Transformer Networks for Pedestrian Trajectory Prediction, ECCV2020
[3] Haoyi Zhou (Beihang Univ.) et al., Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting, AAAI2021