概要
2020年にリリースされたサーバーレス時系列データベースAmazon Timestream(以下、Timestream)について知見がなかったので調べたりハンズオンをやってみました。
普段DynamoDBを中心に使用している関係でDynamoDBとの比較が多いですがご了承ください。
なお、こちらの情報は2023年4月時点での情報です。
Amazon Timestreamとは
時系列データを対象としたサーバレスデータベースです。IoTデバイスから送られてくるセンサーデータやシステムの運用メトリクスに対してSQLを使った分析などをするようなケースにおいて有用そうです。
スキーマについて
データベースで悩みがちなスキーマの定義は一切不要です。DynamoDBもスキーマと呼べるものはほとんど定義不要ですが、それでもパーティションキーとソートキーは事前に決める必要があります。Timestreamはそれすらも不要です。
Timestreamのテーブルの構成要素は次のようになっています。
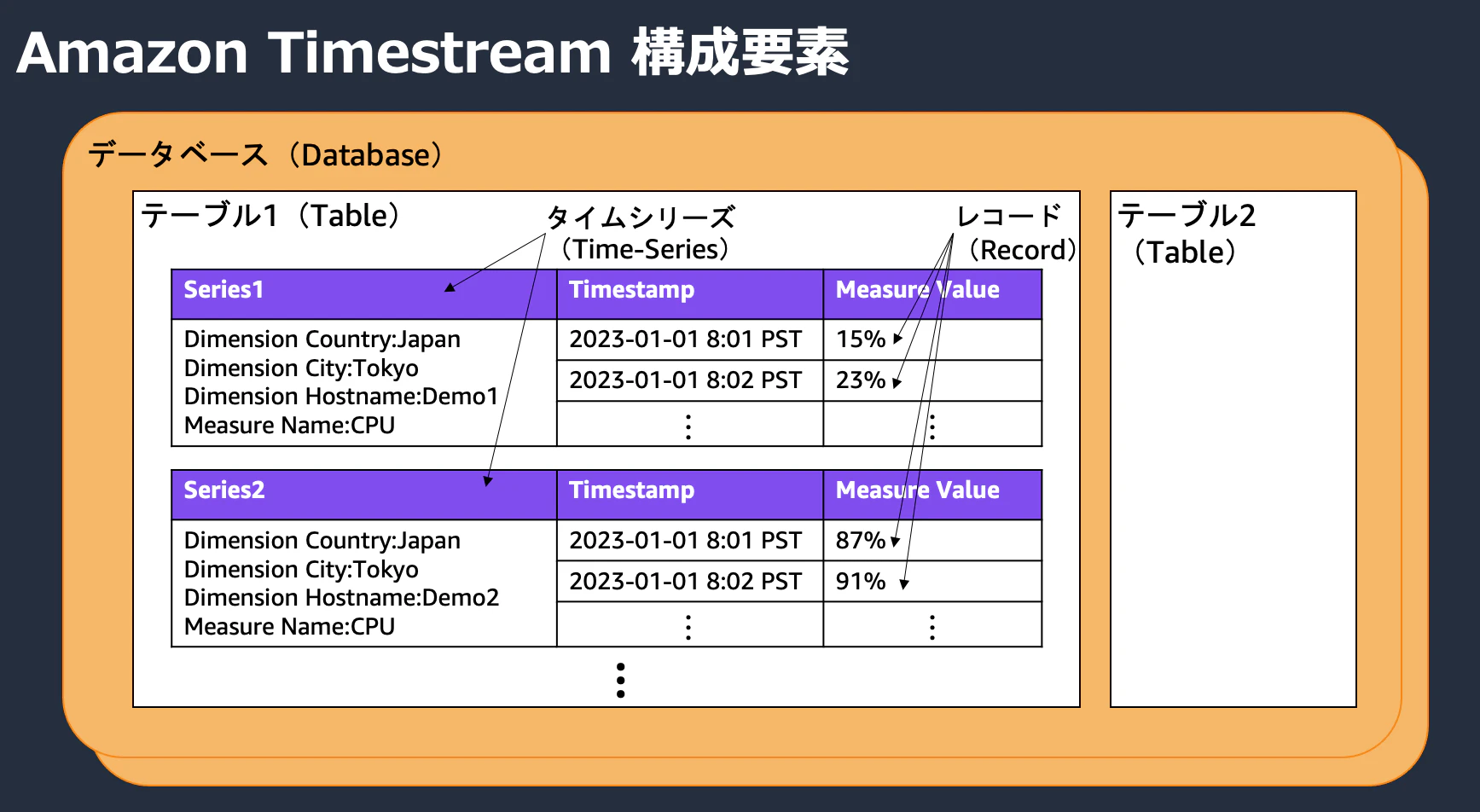
| 構成要素名 | 構成要素説明 |
|---|---|
| データベース (Database) | テーブル (Table) を保持するコンテナ |
| テーブル (Table) | タイムシリーズ (Time-Series) を保持するコンテナ |
| タイムシリーズ (Time-Series) | ある属性値で説明できる、時系列に並んだレコードのまとまり |
| ディメンション (Dimension) | 測定値を識別するための属性情報セット |
| メジャー (Measure) | 測定値 (名前 (measure_name) と値 (measure_value) のセット) |
| レコード (Record) | 単一の時系列のデータポイント |
レコードの考え方
DynamoDBでは1項目に対して複数属性指定可能ですが、Timestreamは1レコード1属性がベースになっているのが特徴です。そのため複数属性扱う場合はテーブルが縦長になります。
なお、マルチメジャーレコードを使用することで1レコードに複数属性保存することが可能です。(ただし、現時点では一部制限があります。)
サポートしているデータ型
サポートしているデータ型はBIGINT, BOOLEAN, DOUBLE, VARCHARです。
インテグレーションの状況
他のAWSサービスとの連携は下記のようになっています。
| サービス | 概要 | リソース |
|---|---|---|
| AWS Lambda | SDKを使ってクエリ実行できる | 未調査 |
| AWS IoT Core | AWS IoT Coreを使用してIoTデバイスからデータを収集し、IoT Coreのルールアクションを通じてAmazon Timestreamにデータをルーティングすることができる。 | 未調査 |
| Amazon Kinesis Data Analytics for Apache flink | Apache Flinkを使って、Amazon Kinesis Data Analytics、Amazon MSK、Apache Kafka、その他のストリーミング技術からAmazon Timestreamに直接時系列データを転送することができる | 未調査 |
| Amazon Kinesis | Amazon Kinesis Data StreamからAmazon Timestreamにデータを送信することができる。 | 未調査 |
| Amazon MSK | Amazon MSKからAmazon Timestreamへデータを送信することができる | 未調査 |
| Amazon QuickSight | データの可視化ができる | Analyzing Data in Amazon Timestream using Amazon QuickSight |
| Amazon SageMaker | クエリ結果を学習データとして使用できる | 未調査 |
| Grafana | Grafanaを使って、時系列データを可視化したり、アラートを作成したりすることができる。 | Visualizing Data in Amazon Timestream using Grafana |
IoT Coreはマルチメジャーレコード機能が使えないので現状はIoT Coreの後にLambdaを挟んでマルチメジャーレコード機能をSDKから実行するのがスタンダードな方法のようです。
結構需要がありそうなんですが、すぐにリリースされる見込みはなさそうです。
また、Timestreamに保存されてからのデータはクエリでの取得が基本になるのでDynamoDBのようにS3にエクスポートしたりデータのCSVをダウンロードするといったことが簡単にできません。
対応リージョン
使用可能なリージョンは次の8つです。
- 米国東部 (バージニア北部)
- 米国東部 (オハイオ)
- 米国東部 (バージニア北部)
- 米国西部 (オレゴン)
- 欧州 (アイルランド)
- 欧州 (フランクフルト)
- アジアパシフィック (シドニー)
- アジアパシフィック (東京) 2022年 8月5日に利用可能になりました!
Timestreamの特徴
データのライフサイクル
データは次のようなライフサイクルをたどります。
まずはメモリストアでデータが保持され、一定期間(たとえば12時間)後にマグネティックストアへデータが移動します。その後、また一定期間(たとえば1日)経ったらデータが削除されます。
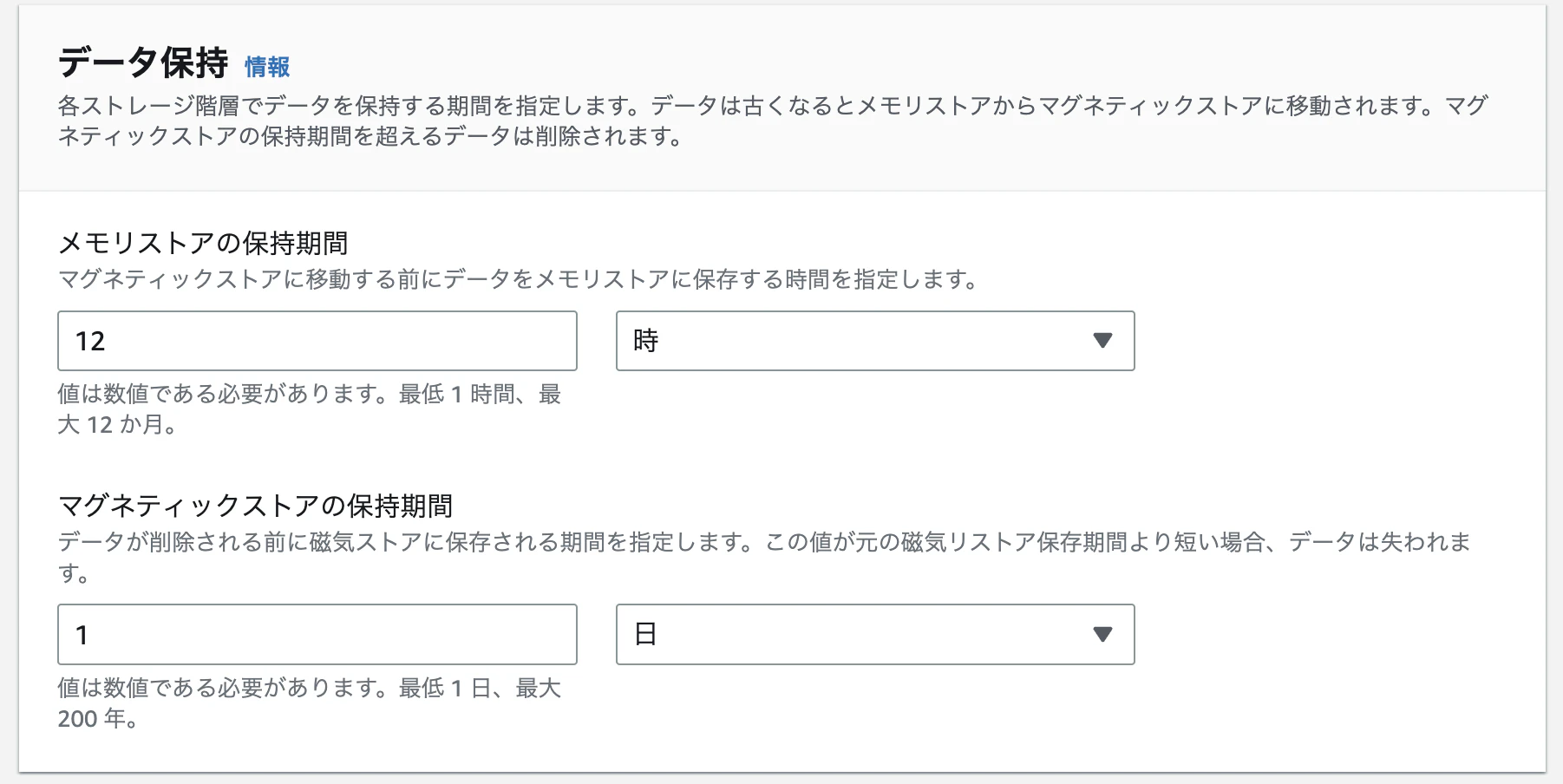
コンソール画面で見るとわかりやすいですね。マグネティックストアの保持期間は最大200年ですので半永久的ではありますが、データ削除が前提です。
マグネティックストアに直接書き込むことも可能です。ただ、これはユーザがマグネティックストアを指定するわけではなくタイムスタンプとメモリストア保持期間を比較してすでに保持期間が過ぎているレコードがマグネティックストアに保持されます。
(Optional) Enable magnetic storage writes: You have the option of allowing magnetic storage writes. With this option checked, late-arriving data, which is data with a timestamp outside the memory storage retention period, will be written directly into the magnetic store.
引用元: https://docs.aws.amazon.com/aws-backup/latest/devguide/timestream-restore.html
なお、この設定は後からコンソール上で変更可能でした。

ハンズオン
公式が用意しているツールを使って実際に触ってみました。
Timestreamへデータを送る(boto3経由)
こちらを参考にさせていただいています。
boto3の場合は次のようにwrite_recordsを使えばデータ書き込みが可能です。
session = boto3.Session(profile_name = profile)
client = session.client(service_name = 'timestream-write',
region_name = region, endpoint_url=endpoint_url, config = config)
# write records to amazon timestream
client.write_records(DatabaseName = databaseName, TableName = tableName,CommonAttributes = (commonAttributes), Records = (records))
ちなみに書き込みデータの中で重複する属性(Dimensions,DimensionValueType, Timeなど)についてはCommonAttributesに書くことで書き込み量が下がりコスト削減になるようです。
スクリプト実行後にコンソール上の[Timestream] > [クエリエディタ]から下記のクエリを実行します。
-- Get the 10 most recently added data points in the past 15 minutes. You can change the time period if you're not continuously ingesting data
SELECT * FROM "sampleDB"."sampleTable" WHERE time between ago(15m) and now() ORDER BY time DESC LIMIT 10
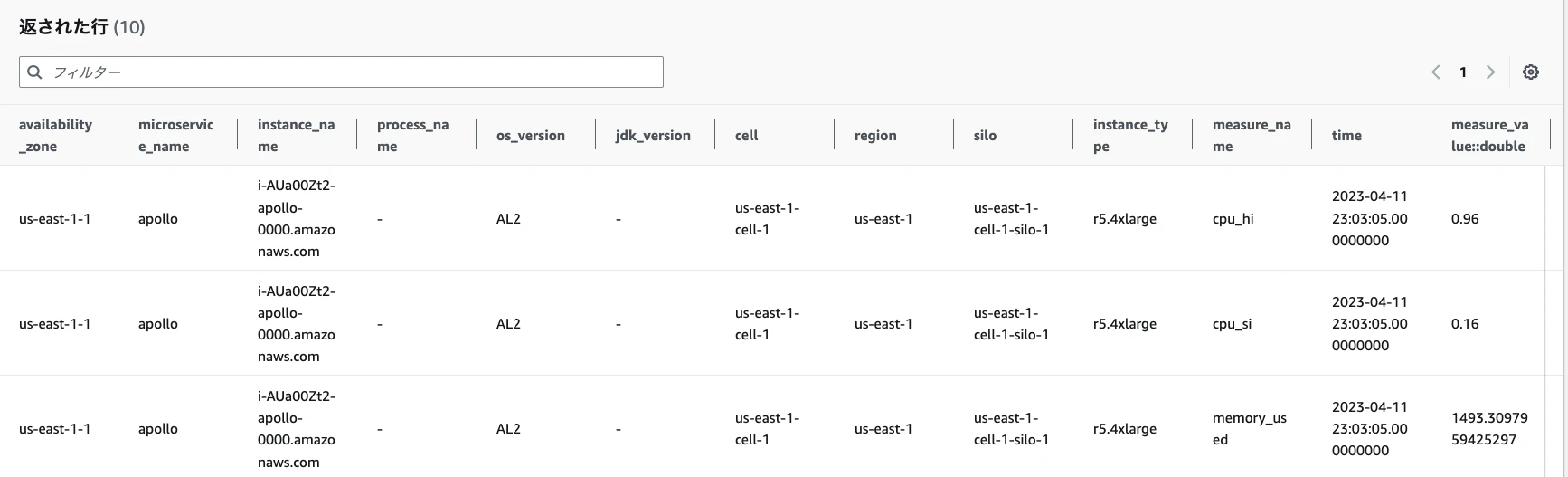
boto3を使うことで簡単にTimestreamにデータ書き込みできました。
最後に
まだ調べきれていない部分が多いので引き続き調べていきます。
参考文献