こんにちは。楽しいアドベントカレンダーの時間です。この記事は武蔵野アドベントカレンダーの11日目です。
わたくし本日は、公開されたばかりのオープンソースなルーティングエンジンFacebook Open/Rと遊びたいと思います。ひゃっほう。
Github: https://github.com/facebook/openr/
日本語紹介記事: techcrunchへのリンク
なお、Open/Rの内部実装まで踏み込んだ日本語記事として既にこちらの記事があり分かりやすいですが、インストールまで踏み込んだものは見当たらず1、本記事が初かもしれません。もしかしたら誤訳や誤解釈により間違ったことを言っていたりするかもしれませんがどうぞご容赦ください。ツッコミ大歓迎です。
本記事では、まず最初にOpen/Rの概要を語り、そのあとにインストール方法や動作確認方法に触れます。インストール方法を手っ取り早く知りたい方はそこまで飛ばしていただいて大丈夫ですが、OSPFなど既存のルーティングプロトコルに馴染みのない方や、既存のプロトコル/エンジンとの差分に興味のある方はぜひ概要も読んでいってください。
Open/Rってなに?
- Open/Rとは、Facebookが先月(2017年11月)オープンソース化したルーティングエンジンで、既存のプロトコルで言えばOSPFやIS-ISのように動作するものです。独自プロトコルであり、OSPFやIS-ISの基礎知識がまったく無くても動かせます。やったね。
- なお、ニュースリリースでは
Open/Rと表記されていますが、githubではOpenRのように/を抜いていて表記されており、どちらが正式な表記なのかは不明です。
- なお、ニュースリリースでは
- Open/Rの目的は、新しいプロトコルをつくることではなく、あらゆるネットワーク上で動作する分散アプリケーションを実現するためのモジュラーソリューションをつくることが目的であると明言されています。
- なぜOSPFなどの既存プロトコルを使わないのか、と疑問を持つでしょう。それらの既存プロトコルは堅牢だが拡張性が低いという見解が、github上のドキュメントで提示されています。Open/Rは、既存のOSPFなどを用いるルーティングエンジンと比べて、異なるエンジンやバージョンとの相互接続性を重視しない代わりに、カスタマイズ性や運用自動化との相性などを高めていると言えそうです。
- Open/Rの基本設計思想として5つのポイントが述べられています。
- Shared data-bus - その上に分散アプリを追加できるようにする。
- Fast convergence - 100ms以下の時間内でのローカル障害の処理。
- Secure bootstrap - ルーティングにおける不要な参加者の回避。
- Address allocation - プラグアンドプレイでのアドレス割り当て。
- HW/SW Segregation - 異なるハードウェアとの容易な統合。
Open/Rはいくつかのコンポーネントにより構成されている
- Open/Rはthrift/ZMQ(zeroMQ)でコンポーネント同士が結合される構造をとっており、Open/Rルータ間のルーティング情報などのやりとりにもthrift/ZMQ(zeroMQ)が使われます。以下のgithubのページに各モジュールがどう繋がっているかに関する公式の絵があるので、興味のある方は覗いてみましょう。
- ZMQ(ZeroMQ)は軽量なメッセージキューを実現しています。また、thriftはRPCの実装に使われており、やりとりされるメッセージの構造が各コンポーネント毎に定義されています。
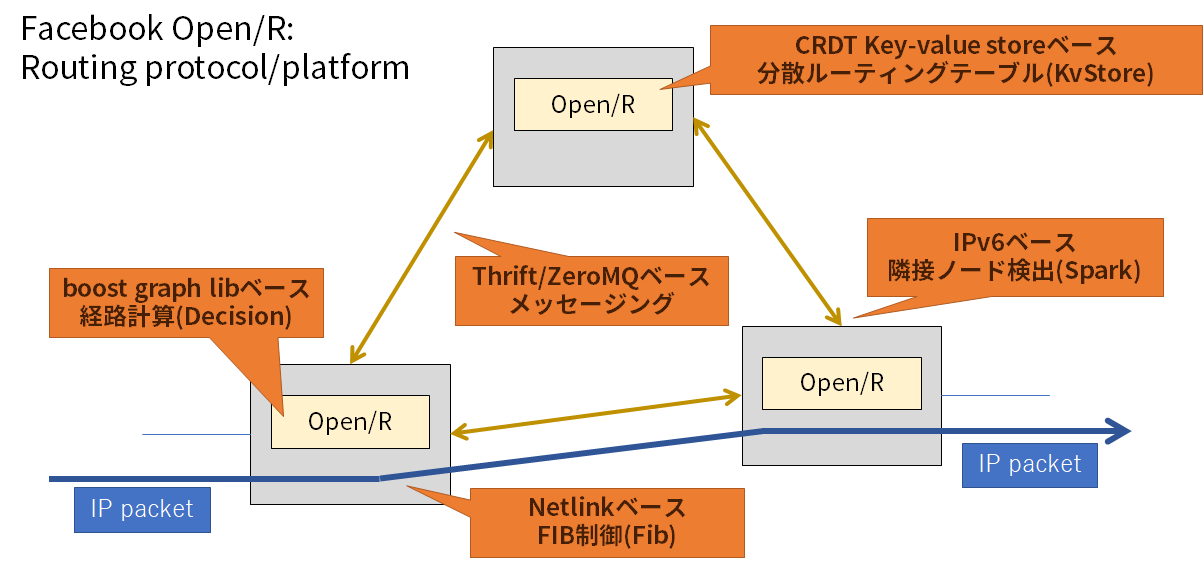
Open/Rを構成するモジュールのうち、ルーティングエンジンの観点から特に重要なコンポーネントとして、各ノードが持つ情報の管理と交換を一手に担う KvStore や、隣接ノードの検出を行う Spark 、経路計算を行うDecision、パケット転送に使うテーブルの管理を行うFib が挙がると思いましたので、それぞれについて少し解説を入れておきます。
コンポーネント紹介その1:分散Key-valueストアでルータ情報をノード間で共有する「KvStore」
- CRDTという分散データストア手法を用いて構成されるルーティングエンジンの中核です。各Open/Rノードが持っているアドレス空間の情報や接続関係の情報を全てのノードで共有するように動作します。
- CRDTの特徴として、誤解を恐れずざっくり言えば「情報の追加は簡単だが削除は難しい」という性質があります。Open/Rのルーティングテーブルに関する情報交換もこれに則って「追加」と「上書き」の操作しか許されていません。ただし、各情報にはタイムスタンプ及びTTL(有効期間)が設定され、その有効期間を過ぎると削除されます。有効期間のデフォルト値は5分なので、その情報を削除されたくない場合には、5分経つ前に各ノードはTTLの延長を申請することになります。
- CRDTの思想を守ることで、ルーティングテーブルの管理を容易にしていると言えそうです。CRDTそのものについては、 こちらの記事 がとても分かりやすく、勉強になりました。本当に15分で理解した気持ちになれます。おすすめです。
コンポーネント紹介その2:IPv6リンクローカルマルチキャストで隣接ノード検出を行う「Spark」
- Open/RはOSPFv3(OSPFのIPv6版)と同様に、IPv6リンクローカルアドレスを用いた隣接ノードの検出や隣接ノードとの情報交換を行います。これを担うコンポーネントがSparkです。OSPFv3との違いとしては隣接ノードの検出(hello)にUDPを用いることが挙げられます。
- 起動したノードを100ms以内に他のノードが検出できるFast Discovery機能がついています。が、逆に消滅したノードを検出するためのkeepaliveはデフォルトで3秒間隔、ノードが消滅したかを確定するまでの時間hold timeはデフォルトで30秒であり、即座に故障を検出できるわけではありません。これもOSPFと同様です。もちろん、ローカルに検出可能な故障(リンクダウンなど)であれば高速な検出と切り替えを期待できるでしょう。
コンポーネント紹介その3:経路計算を行う「Decision」
- Open/Rはオープンソースのグラフ計算エンジンboost graph libを用いて、複数存在する経路のなかから最適な経路を計算するコンポーネントです。
- 経路計算にはOSPFでもおなじみのダイクストラ法を用いています。デフォルトだと各リンクのコストは1固定として計算するようですが、RTTをコストとして用いる設定も可能なようです。また、このメトリックは容易に拡張可能であると述べています。
コンポーネント紹介その4:経路情報に従ってパケットの転送を行うFIBを管理する「Fib」
- ネーミングはそのまんまですね。Open/Rルータへの入力パケットの転送先を決定するのに使われるテーブル(FIB2)の制御を行っているのが、Fibコンポーネントです。Netlinkはlinux kernel上のネットワーキング情報を収集・設定するためのインタフェースです(Wikipedia(英語))。
- Open/Rの起動オプションを変更することで組み込まれたFibモジュールではなく独自のFibモジュールを持ち込むことも可能なようで、ホワイトボックススイッチなどをターゲットにする際は別のFibモジュールを使っているのではとも想像しますが、その例はまだ公開されていません。
早速Open/Rをインストール&動作確認したい
- 以上で概要を終え、次にインストールを始めたいと思います。いきなり多数のOpen/Rノードが動作する環境を作ろうとしても辛いでしょうから、まずはふたつのOpen/Rノードを立ち上げて接続し、動作を見てみようと思います。
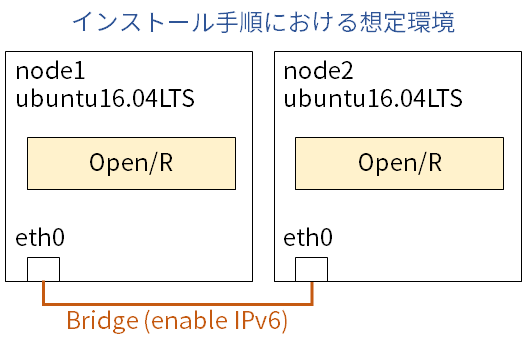
前提条件
- ここでは公式ドキュメントの手順に従い、シェルスクリプトを使ったOne Step Buildでの構築手順を紹介します。
- Dockerでもインストール可能だと思いますが、動作確認はしていません。
- lxcでは動作しました。netnsでは動きませんでした・・・
- 初期はこのOne Step Buildでの構築すら通らない時期もありましたが、迅速な修正により現在は問題なくインストールできるようになりました。
- Dockerでもインストール可能だと思いますが、動作確認はしていません。
- 以降は先ほどの図の条件を想定して設定していきます。VM2つをブリッジで繋ぐだけの単純な構成ですが、VMを繋ぐブリッジでIPv6通信が可能なことが何より重要です。IPv6が疎通しない環境では注意しましょう。
- 図の
eth0は便宜上のインタフェース名なので各環境に合わせて読み替えて下さい。 - メモリは8GB程度の割当を推奨します。メモリが少ないと、ライブラリのコンパイルに失敗します。
- CPUコア数は、2コア程度あれば十分でしょう。多ければインストールが早くなるものではなさそうです。
- 図の
インストール手順
-
公式手順はgithubに記載があります。下記URLの「One Step Build」の手順によりインストール可能です。
-
各VMで下記コマンドを実行し、20~30分ぐらい待つとできあがりです。
sudo apt update
git clone https://github.com/facebook/openr.git
cd openr/build
sudo bash ./build_openr.sh
- 補足
- この後に
sudo make testを実行することで再度テストを実行することができます。 - 今回のインストール確認はコミット59ed96時点のものを利用しています。もし本手順で通らない場合は
git checkout 59ed96で戻ってみてもいいかもしれません。 - buildに時間がかかるのは主要なライブラリをコードからビルドしているからです。ビルド対象となっているのはFacebookが公開しているC++ライブラリの
follyや、先に述べたthriftやzmq(fbthrift/fbzmq)など様々です。
- この後に
実行手順
-
ここではopenrコマンドに直接パラメータを指定して起動します。
- github上のドキュメント(Runbook.md)では
run_openr.shを呼び出す方法が推奨されていますが、残念ながら現状(11月末)版のrun_openr.shは動作しません。(軽微な修正で動作させることは可能です) - なお
openrに--helpは効きませんのでRunbook.mdを見ながらオプションパラメータを設定しましょう。
- github上のドキュメント(Runbook.md)では
-
実行手順は簡単です。
-
VM1でコマンド実行:
sudo openr --ifname_prefix=eth0 --node_name=node1 --enable_netlink_fib_handler=true --dryrun=false
-
VM2でコマンド実行:
sudo openr --ifname_prefix=eth0 --node_name=node2 --enable_netlink_fib_handler=true --dryrun=false
-
これでOpen/Rが起動し、自動的に互いのノードの存在を認識します。
- 起動時にいくらかエラーメッセージのようなもの(下記)が出ますが無視して次のステップに進みましょう。
-
$ sudo openr --ifname_prefix=eth0 --enable_netlink_fib_handler=true --dryrun=false --node_name=node1
openr[2148]: Starting OpenR daemon.
E1203 12:29:04.480279 2148 KnownKeysStore.cpp:24] Failed reading known keys, file might be missing
E1203 12:29:05.501940 2148 LinkMonitor.cpp:1055] Failed to sync LinkDb from NetlinkSystemHandler. Error: apa
che::thrift::transport::TTransportException: Timed Out
openr[2148]: Neighbor node2 is up on interface eth0.
- 補足:各オプションの意味合い
-
--ifname_prefixはOpen/Rが動作するポートを記載するもので、複数ポートでOpen/Rを動かしたい場合はeth.*のように正規表現を用いることで一括して動作ポートを指定可能です。 -
--node_nameはVM1とVM2で別の名前を指定しないとノード名が重複しているというエラーが出てうまく動きません。 -
--dryrun=falseはルーティングテーブルの更新時にFIBへの書き込みを行わないかを指定するオプションで、デフォルトはtrue(書き込みを行わない)です。これをfalse(書き込みを行う)に指定しておかないと、いわゆるpingでの疎通テストが実施できません。 -
--enable_netlink_fib_handler=trueはFIBの制御にもちいるFibコンポーネントとして予め用意されたものを使うか自前で用意するかを選択するオプションで、trueにするとOpen/R内にあるFibコンポーネントを利用してくれます。デフォルトはfalseです。
-
動作確認方法
- Open/Rの操作には
breezeというコマンドを使います。breezeはPython-clickをベースとしたOpen/R操作用CLIインタフェースです。こちらは--helpが効きます。それでは、各VMに対して別のコンソールを開いてください。そしてコマンドを打ち込んでいきましょう。 - ここでは主にKvStoreの中身を見ていくコマンドを中心に試していきます。
動作ポートの確認
-
breeze lm linksを実行すると、どのインタフェースでOpen/Rが動作しているか確認できます。
$ sudo breeze lm links
== Node Overload: NO ==
Interface Status Overloaded Metric Override ifIndex Addresses
----------- -------- ------------ ----------------- --------- ------------------------
eth0 Up 8 10.164.199.123
fe80::216:3eff:fe30:5598
トポロジー図を表示してみる
- どのように各ノードが接続しているかを
breeze kvstore topologyコマンドで図示できます。
$ sudo breeze kvstore topology
AA matplotlib and networkx needed for drawing. Skipping
Saving topology to file => /tmp/openr-topology.png
- 今回は2ノードなので画像を見てもあんまり面白くありませんね。なお、画像出力にはデフォルトのインストール手順に加え
matplotlibを追加でインストールする必要があります。
経路を注入してみる
- 各ノードが持つアドレス空間を編集するには
breeze prefixmgrコマンドを使います。以下の例では、IPv6のアドレス空間2001:db8:aaaa::/48をnode1に注入し、その情報が対向ノードに伝達されているかをnode2でbreeze/ipコマンドにより確認しています。
# 事前にnode 2の経路情報に注入する経路の情報がないことを確認しておく
user@node2:~$ ip -6 route
fd51:c8a5:f3ba:393a::/64 dev eth0 proto kernel metric 256 expires 3103sec pref medium
fe80::/64 dev eth0 proto kernel metric 256 pref medium
default via fe80::5482:9dff:feb1:d467 dev eth0 proto ra metric 1024 expires 1303sec hoplimit 64 pref medium
# node 1にアドレス空間を設定する
user@node1:~$ sudo breeze prefixmgr advertise 2001:db8:aaaa::/48
Advertised 1 prefixes with type BREEZE
# node 2側に経路が設定されたかをbreezeとipの両方で確認する
user@node2:~$ sudo breeze kvstore prefixes --nodes=all
> node1's prefixes
Prefix Type
------------------ ------
2001:db8:aaaa::/48 BREEZE
> node2's prefixes
Prefix Type
-------- ------
user@node2:~$ ip -6 route
2001:db8:aaaa::/48 via fe80::216:3eff:fe45:d0ef dev eth0 proto 99 metric 1024 pref medium
fd51:c8a5:f3ba:393a::/64 dev eth0 proto kernel metric 256 expires 3409sec pref medium
fe80::/64 dev eth0 proto kernel metric 256 pref medium
default via fe80::5482:9dff:feb1:d467 dev eth0 proto ra metric 1024 expires 1609sec hoplimit 64 pref medium
- 無事にnode1で登録したアドレス空間がnode2に伝わっていますね。
- これで
2001:db8:aaaa::/48に含まれるアドレス(例えば2001:db8:aaaa::1)に対してping6をnode2から打つと、node2からpingがeth0を通って発出されるのがtcpdump等で確認できます(このままだと実際の宛先が居ないので返答はありませんが、例えばnode1のeth0に設定を入れておけば(ip a a 2001:db8:aaaa::1 dev eth0)、node2からのping6が帰ってくるようになります。)
key-valueストアの内容を確認する
- どのような情報がkvstoreにより管理されているかを
breeze kvstore keysで確認できます。先述の通りこのkey-valueストアはCRDTで動作しています。情報の各情報にはバージョン番号が付与されており、以前より大きなバージョン番号で情報を上書きすることでストアの内容が更新されます。
$ sudo breeze kvstore keys
== Available keys in KvStore ==
Key OriginatorId Version Hash
--------------- -------------- --------- --------------------
adj:node1 node1 9 -277215442141534929
adj:node2 node2 12 -4592434436111011156
intf:node1 node1 1 -7656543817840970122
intf:node2 node2 1 5531137946877083783
nodeLabel:1 node1 1 3006937260350826953
nodeLabel:31888 node2 1 3006937257985701041
prefix:node1 node1 3 853851589555339087
prefix:node2 node2 2 1559336138416713029
各key-valueの詳細を参照する
上記keysのうちvalueを見たいものがあれば、breeze kvstore keyvals [key名]で閲覧できます。
$ breeze kvstore keyvals adj:node1
== Dump key-value pairs in KvStore ==
> key: adj:node1
version: 14
originatorId: node1
ttl: 300000
ttlVersion: 1
value:
AdjacencyDatabase(
thisNodeName='node1',
isOverloaded=False,
adjacencies=[Adjacency(
otherNodeName='node2',
ifName='eth0',
nextHopV6=BinaryAddress(
addr='\xfe\x80\x00\x00\x00\x00\x00\x00\x02\x16>\xff\xfe0U\x98',
port=0,
ifName=None),
[以下略]
KvStoreのアップデート状況を覗き見する
- CRDTによって更新されつづけるKey-valueストアの更新模様を眺めるには、
breeze kvstore snoopコマンドを使います。更新のたびに情報のバージョン番号が増加し続けていく様子がわかります。なお隣接関係の維持(hello/keepalive)では毎回RTTを測定して都度KvStoreで測定されたRTTが共有されています。
$ sudo breeze kvstore snoop
Timestamp: 2017-12-03 13:54:09.871
> node1's adjacencies
version: 51 --> 52
ttlVersion: --> 0
ttl: --> 300000
NEIGHBOR_UPDATE: node2 via eth0
--- --- --- ---
rtt 249 --> 228
--- --- --- ---
Timestamp: 2017-12-03 13:54:19.786
> node1's prefixes
version: 5 --> 6
ttlVersion: --> 0
ttl: --> 300000
+ 2001:db8:a::/24
動作時Tips
- ログは
/tmp直下に保存されます。INFOレベルのログを見たい場合にはこちらを参照しましょう。
動かしてみた感想
- おもったよりもちゃんと動作したぞ楽しいぞ、という感想です。一部の手順がうまく動かず修正が入ったりしている状況であることは事実で、いまOpen/Rはオープンソース化作業のまっただ中に居ると考えられます。しかし、それでも既に、Open/Rの中核にある思想やそれを実現するための実装(CRDTやThrift/ZMQの活用)を理解するには十分なコードがそこにあります。
- OSPFのように標準化されたプロトコルではないために、wiresharkなどが持つ既存のパーサでは解析できず、不満に思うネットワークエンジニアも居るかもしれません。逆に考えれば、コントロールプロトコルに対してはパケットベースでの分析を期待せず、アプリケーションログやAPIを用いたレイヤでの分析に一任させる設計思想であると言えるかもしれません。
- 拡張性を抜きに考えれば今のOpen/Rでできることは機能的には殆ど既存のOSPFで実現可能なことであり、今後のロードマップに期待したいと思います。また、信頼性や安定性についてはCRDTをベースにした構成を取っていることで何らかの恩恵があるのだろうと類推されるものの、それが何なのかは少し触っただけではわかりませんでした。
おわりに
- Open/Rは、CRDTや各種ライブラリなど既存の技術の組み合わせで動いていることに加え、Thriftベースなのでどんな情報がコンポーネント間でやりとりされているか追いやすく、動かして理解しやすいプラットフォームだと思います。VMやLXC上でさくっと動きますので、ビルド時間(約30分)を許容できる方はぜひ試してみましょう。
-
2017年11月末調べ。ありましたらこの記事でも紹介したいのでお知らせいただけたら幸いです。 ↩
-
Forwarding Information Baseの略。Wikipediaの記事は英語版ならありますが、日本語版はありません。日本語だと、ルーティングテーブルの項に少しFIBの説明があります。 ↩