このページは、筆者がSQLサーバーとSQL文の基礎について[こちらの文献][ref1]を参考に学んだことについてわかりやすくまとめることを目的としています。より詳しく知りたい方は[文献][ref1]を参考にしてください.また、誤っている部分があればコメント等で指摘していただけると幸いです.
データベースって何?
データベースとは『膨大なデータをひとまとめにしたもの』であり、更にそれらのデータを『何らかのルールや目的に基づいて管理(整理)』したデータの集まりです. 例えば、机の上にたくさんの本や文房具が散らばっていた場合、それらの中から1本のペンを探しだすのは時間がかかります. これをデータベースで何らかのルールで整理されていればすぐに必要なペン(情報)を探し出すことができます. このデータベースを管理するシステムをDBMS(DataBase Management System): データベース管理システム といいます.
データベースの種類
データベースには階層型、ネットワーク(網)型, リレーショナル(関係)型などの種類がありますが、現在最も広く使われているのがリレーショナル型のデータベースです.
リレーショナルデータベースではデータを表形式で表します(Fig.1).表はExcelのように行(row)と列(column)で表されます. この表のことをテーブル(table)とよびます.また、列にはそれぞれユーザーにわかりやすいように列名をつけます.また、リレーショナル(連携)データベースではテーブルどうしが連携(テーブルどうしがつながっているような状態)して動く仕組みを持っています.このようなシステムを**リレーショナルデータベース管理システム(RDBMS)**と呼び、RDBSが管理するシステムのまとまりをリレーショナルデータベース(RDB)といいます.
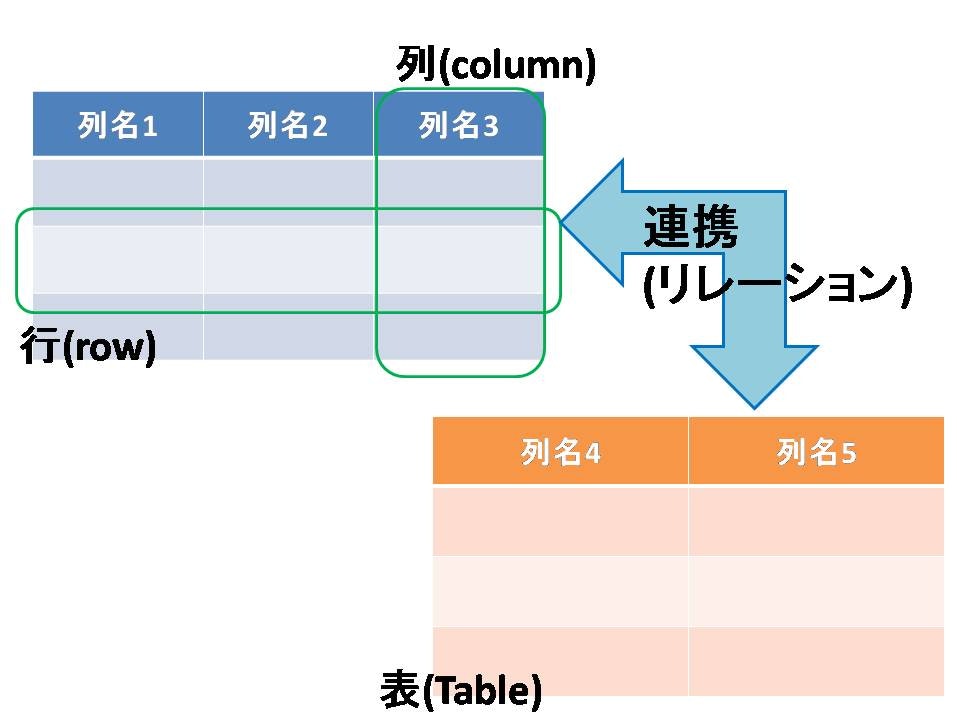
Fig.1 リレーショナルデータベースの構造
SQLって何?
データベースとの対話に用いる言語はデータベース言語と呼びます. その中でもSQL(Structured English Query Language)は「リレーショナルデータベース管理システム(RDBMS)と対話するための言語」です. データベースに対して「〇〇というデータをください」「△△というデータを挿入してください」などの要求を呼びかける際に使われます。このデータベースに要求を出すことをクエリ(問い合わせ)といいます.クエリの中身であるSQL文はユーザーが作成する場合と、ユーザーは簡単な操作を行うだけでソフトウェアが作成してくれる場合があります.
現在ではSQLにプログラミング機能が加わりました. それによって単なる対話の手段としてだけでなく、データベース管理システム上にソースコードを置いておくことで一連の作業をプログラムとして呼び出して実行することができます. このような仕組みで動くプログラムはストアドプロシージャといいます.
リレーショナルデータベース管理システムにはMycrosoft SQL Server, MSDE, Oracle, MySQL, PostgreSQL,DB2/UDBなどがあります.これらは全てSQLに対応しています. このことからSQLは「データベース界の標準語」とも言われています. しかし、RDBによって独自のローカルルールが存在する場合があるので注意が必要です.
主キー(Primary Key)
**主キー(Primary Key)**とはテーブルの中で行を特定するための列です.例えば、学生名簿を作る場合、同姓同名の人がいると名前だけでは個人を特定できません(Fig.2の緑色の枠線で囲んだ部分). そこで主キーとして学生番号を振ります. 主キーに設定された列では値が重複できないため、同姓同名であっても特定することが出来ます.また、テーブルに主キーを設定することでテーブル同士を連携しやすくします.例えば、あるテーブルには名前と苗字を、別のテーブルに成績と学年を入れておいても主キーが同じであればそれらを簡単に連携させることが出来るようになります. ただし、主キーは各テーブルに1つしか設定することが出来ません.
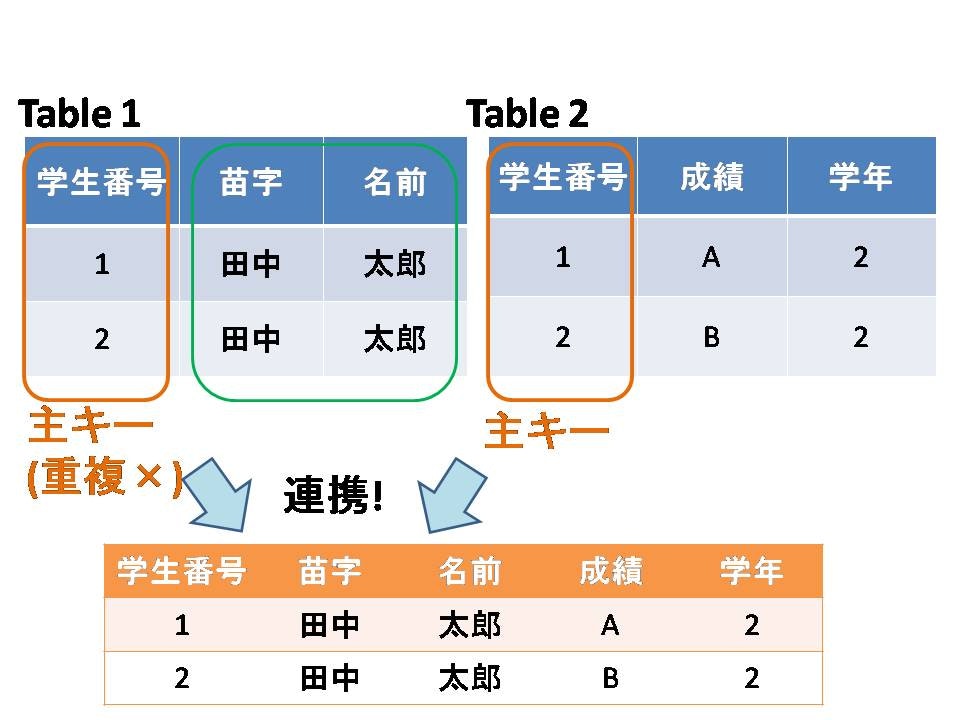
Fig.2 主キーと連携
連結キー
主キーは1つのテーブルに1つしか設定することができません.しかし、複数の列を組み合わせて1つのキーとすることもできます. これを連結キー(複合キー)といいます. 例えば、住所のテーブルを作成する際に『〇〇県, △△市』をそれぞれ『県』と『市』の列で登録したとします. しかし、〇〇県だけでキー登録してしまうと一つの地域を特定することができません. そこで、『県』と『市』の列を連結キーとして設定しておくことでデータを特定することができるようになります.
制約
登録するデータを常に正しい状態に保つために制約という条件をつけることが出来ます.制約を設けることでデータの登録時に制限をかけることが出来ます.制約には、単一の列に設定する列制約と複数の列にまとめて設定するテーブル制約があります. 連結キーはテーブル制約にあたります.また、ひとつの列に対して複数の制約を設けることも出来ます.
制約には主に次のようなものがあります.
| 制約 | 意味 |
|---|---|
| PRIMARY KEY(主キー) | ・データの重複を禁止 ・NULL値(値が入っていない状態)を禁止 |
| UNIQUE | ・データに[一意性][ref2]をもたせる. |
| CHECK(条件式) | ・条件に合わないデータを禁止 |
| NOT NULL | ・NULL値を禁止 |
| DEFAULT=値 | ・あらかじめ指定した値を初期値として登録. |
SQLの基礎
ここではデータを挿入する(INSERT文)、データを取り出す(SELECT文, FROM文)とSELECT文のオプション(ORDER BY,GROUP BY, DISTINCT, AS)とその基本的な扱い方について説明します.ただし、データベース・テーブルの作成方法については触れません. また、クエリ文のみの説明となります.
INSERT文のより詳しい使い方や他の文(WHERE, LIKE演算子など)についてはこちらのページをご覧ください(更新予定).
データを登録
テーブルにデータを登録する際はINSERT INTOを使います.
INSERT INTO Table1 (列名A, 列名B, 列名C) VALUES (dataA, dataB, dataC)
この文ではTable1というテーブルに値を挿入します.
列名AとdataA, 列名BとdataB, 列名CとdataCがそれぞれ対応しています.
これを実行すると以下のような表になります.
| 列名A | 列名B | 列名C |
|---|---|---|
| dataA | dataB | dataC |
データを取り出す
作成したテーブルから必要なデータを取り出す方法について説明します.例として次のようなテーブルからデータを取り出すことを考えます.
テーブル名: Table1
| 学生番号 | 名前 | 身長 |
|---|---|---|
| 1 | 田中 | 172.0 |
| 2 | 鈴木 | 160.0 |
| 3 | 佐藤 | 165.2 |
| 4 | 小林 | 160.0 |
全てのデータを取り出す
テーブルに登録しているデータを取り出すには, SELECT文を使います.取り出したデータはテーブルから削除されません、ただ取り出して見ることができます. どの列から取り出すかはFROM文を使って指定します. 例としてTable1の全ての列を取り出す方法について書きます.
SELECT * FROM Table1;
全部の列を取り出す場合は「*(アスタリスク)」で表します.
出力
| 学生番号 | 名前 | 身長 |
|---|---|---|
| 1 | 田中 | 172.0 |
| 2 | 鈴木 | 160.0 |
| 3 | 佐藤 | 165.2 |
| 4 | 小林 | 160.0 |
1列だけ、あるいは複数の列を取り出す.
テーブルから指定した1列だけを取り出すこともできます.その場合はSELECTの後のアスタリスクの代わりに列名を入れます.
SELECT 名前 FROM Table1;
複数の列をまとめて取り出す場合には、列名をカンマで区切って入力します.
SELECT 名前, 身長 FROM Table1;
出力
複数列取り出した場合
| 名前 | 身長 |
|---|---|
| 田中 | 172.0 |
| 鈴木 | 160.0 |
| 佐藤 | 165.2 |
| 小林 | 160.0 |
データの並び替え
SELECT文には指定した列を基準にデータを並び替えるORDER BY句というオプションがあります。
身長で昇順に並び替えるには以下のように記述します.
SELECT * FROM Table1 ORDER BY 身長 ASC;
ASCはASCENDの略で昇順の意味です. また、ASCは省略することができます.
降順に並び替えるには以下のように記述します.
SELECT * FROM Table1 ORDER BY 身長 DESC;
DESCはDESCENDの略で降順の意味です.
詳細な並び替え
並べ替えの基準となる列はカンマ区切りで複数指定できます.
SELECT * FROM Table1 ORDER BY 身長, ID;
上のSQL文ではまず身長を基準に昇順で並び替えを行い、身長が等しかった場合はIDを基準に並び替えを行います.
結果
身長を基準に昇順で並び替えを行った場合
| 学生番号 | 名前 | 身長 |
|---|---|---|
| 1 | 田中 | 172.0 |
| 3 | 佐藤 | 165.2 |
| 4 | 小林 | 160.0 |
| 2 | 鈴木 | 160.0 |
| あるいは |
| 学生番号 | 名前 | 身長 |
|---|---|---|
| 1 | 田中 | 172.0 |
| 3 | 佐藤 | 165.2 |
| 2 | 鈴木 | 160.0 |
| 4 | 小林 | 160.0 |
身長を基準に昇順で並び替えを行った後、身長が同じだった行に対してIDを基準に並び替えを行った場合
| 学生番号 | 名前 | 身長 |
|---|---|---|
| 1 | 田中 | 172.0 |
| 3 | 佐藤 | 165.2 |
| 2 | 鈴木 | 160.0 |
| 4 | 小林 | 160.0 |
その他のオプション
SELECT文の他のオプションを紹介します.
重複したデータを除去して表示する
指定した列にある重複したデータを除去して表示させる方法として DESTINCT句があります.複数の列をカンマ区切りで指定することもできます.
SELECT DISTINCT 身長 FROM Table1;
結果
| 身長 |
|---|
| 172.0 |
| 165.2 |
| 160.0 |
列名を変えて表示する
AS演算子を使うことでTableに保存されている列の名前を別の表示にすることができます.ただし、AS演算子は一時的に表示する名前を変えるだけで、元の列名を変えるわけではありません.
SELECT 身長 AS height FROM Table1
結果
| height |
|---|
| 172.0 |
| 165.2 |
| 160.0 |
データをグループ化する
指定した列のデータが同じ場合にはそれらの行をひとつにまとめるGROUP BY句があります.これは集約関数(追記予定)と一緒に使用します.
SELECT 身長, COUNT(名前) FROM Table1 GROUP BY 身長;
上の文では身長が同じ(身長の列に同じ数字がある)データをひとまとめにし、集約関数のCOUNT関数を使っていくつのデータをひとまとめにしたかを数えることができます.
参考文献
- [SQLの絵本 データベースがみるみるわかる9つの扉][ref1], 株式会社アンク, 佐々木 幹夫, 株式会社 翔泳社, 2010年4月5日,pp.1-50
- [一意性制約][ref2], Wikipedia
[ref1]: http://www.amazon.co.jp/SQL%E3%81%AE%E7%B5%B5%E6%9C%AC%E2%80%95%E3%83%87%E3%83%BC%E3%82%BF%E3%83%99%E3%83%BC%E3%82%B9%E3%81%8C%E3%81%BF%E3%82%8B%E3%81%BF%E3%82%8B%E3%82%8F%E3%81%8B%E3%82%8B9%E3%81%A4%E3%81%AE%E6%89%89-%E3%82%A2%E3%83%B3%E3%82%AF/dp/4798106690
[ref2]:https://ja.wikipedia.org/wiki/%E4%B8%80%E6%84%8F%E6%80%A7%E5%88%B6%E7%B4%84