OpenAIが開発したコード生成AIの「Codex」や、その技術を活用した「GitHub Copilot」が注目を集めています。Qiitaや技術ブログではCopilotを試してみた系の記事も多く公開されており、好意的な反応と共に紹介がされているように感じます。
これらのコード生成AIやツールを開発業務で活用しようと考えた際、どのような効果が見込めるのか、プログラマの心理やパフォーマンスにどのような影響を及ぼすのかが気になったので、CodexやCopilotの実装能力やプログラマに与える影響を調査した研究事例などを調べました。
この記事では、調べた結果を基に、SIerにおける開発業務でCopilotやCodexといったソースコードが生成できるツールやAIを活用するにあたって留意するべきポイントなどを、私の感想を交えながらご紹介します。
本記事で紹介する範囲
本記事では、SIerがCopilotを業務活用する際に検討・留意すべきポイントと、Copilotがプログラマに与える影響について調査した研究事例について紹介します。
上記以外の内容(例えば、Copilotの提案結果を利用することでOSSライセンスを違反してしまう可能性、実際にCopilotを使った検証の結果、など)については本記事では取り扱いません。
Copilot / Codexの実装能力について
Codexは入門レベルの学生よりも実装能力に長けているが、プログラマを完全に代替できるわけではない
Finnie-Ansleyら[1]の研究によれば、Codexは大学1年生のプログラミング試験で、受験者全体の上位24%に相当する成績を達成したとされています。ただし、メソッドやループ処理の利用が制限された問題や、出力フォーマットが厳密な問題では苦戦していたことも報告されており、要件に応じて柔軟に実装をすることはまだまだ苦手としているようです。
以下に、学生とCodexの試験成績を表した散布図(出典元:[1])を示します。縦軸・横軸は2種類の試験のスコアであり、白抜きの丸と赤色のアスタリスクはそれぞれ学生とCodexの試験成績を表しています。
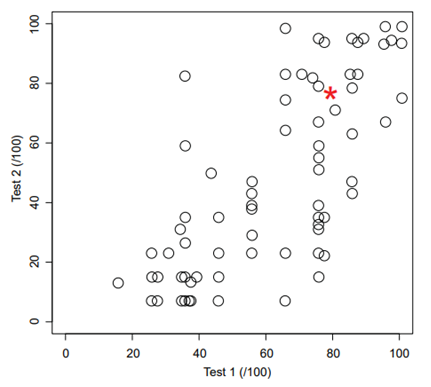
現状、Codexは大学1年生向けの試験ですらトップの成績を収めることができないことからも、コード生成AIが完全にプログラマを代替できるレベルへ至るにはもう少し時間がかかりそうです。
Copilotが提案するコードの可読性は人間のコードと同等
Madi[2]の調査では、GitHub Copilotが提案するソースコードの可読性が、人間が実装したソースコードの可読性と同等であると報告しています。
これは、一般的なコーディング規約に沿って人間が実装したソースコードをAIが学習したことで、生成されるソースコードにもコーディング規約が反映されたことが原因ではないかと思います。
Copilotの実装能力はソースコード中のコメント次第で変化
ここまでCopilot/Codexの実装能力について紹介しましたが、これらはソースコード中のコメントによって大きく影響を受ける点に注意が必要です。例えばPearceら[3]の研究によると、意味が変わらない範囲でコメントを変更するだけでCopilotが脆弱性を含むソースコードを提案する場合があったと報告しており、コメントが少し変わるだけでコードの品質が変化することがうかがえます。
プログラマはCopilotの提案するコードの品質に満足できない場合、ソースコード中のコメントを編集することで品質がより良くなる(悪くなる)可能性があることを念頭に置き、開発に取り組む必要がありそうです。また、プログラマがコメントを記載しやすいように、設計段階で必要な情報を取りまとめておく、といったことも必要となるでしょう。
プログラマに与える影響について
プログラマはCopilotに好意的。一方、コーディング課題を解く実験ではCopilotによる生産性の大幅な向上は見られなかった
GitHubによるアンケート調査[4]によると、88%の回答者がCopilotの利用で生産性が向上すると回答しており、多くのプログラマがCopilotに対して好意的な印象を抱いているようです。また、[4]では退屈で繰り返し行うようなコーディングをCopilotが肩代わりすることで、プログラマの負担が減ったのではないかとも考察しています。
このように、例えばライブラリのメソッドやAPIを呼び出すような単純な実装でも、呼び出すメソッド名や引数をウェブなどから調べなくてはいけないことが多々あるかと思います。このような場面においてCopilotを活用すれば、プログラマは素早く必要な情報を知ることができ、生産性の向上につながるのではないかと考えられます。
その一方で、Vaithilingamら[5]はCopilotを利用することで、コーディング課題を解くまでの時間とその正答率に変化が生じるか実験を行いました。その結果、Copilotを利用したグループは短い時間で課題を解決できたものの、正答率は低かったことが報告されています(※回答時間・正答率のいずれも統計的に有意な差はなかったとのことです)。また、Copilotの提案したコードを読み解き、課題の回答として適切な内容に修正することが困難であったと指摘したプログラマがいたことも述べています。
他人が書いたコードや自分が過去に書いたコードを理解するのが難しいと感じるのは、多くのプログラマに共通する経験だと思います。コーディング課題のようなアルゴリズムの設計が必要となる処理の実装でCopilotを用いると、同じように提案されたコードの理解に苦労し、その結果、非効率的な実装やバグにつながってしまう可能性もあるのではと感じました。
Copilotを過信してしまうネガティブな影響も示唆されている
Copilotの利用については、AIやコンピュータが出力した結果を優先してしまうオートメーションバイアスの影響も指摘されています。Madi[2]は、アイトラッキング装置を使ってCopilot利用時と、ペアプログラミング時のプログラマの視線の動きを調査しました。結果、Copilot利用時のプログラマの視線がコードに固定される時間が減少したことを報告しており、プログラマがCopilotの提案を正しいと思い込んで注意を払わなくなっていた可能性が示唆されています。
特に開発業務におけるオートメーションバイアスは、レビュー品質の低下や不具合の見過ごしなどにつながる可能性もあります。Copilotのようなツールを導入するにあたっては、AIは間違えるものであり完璧ではない、ということを正しく理解した上でツールを使うことが重要になるでしょう。
開発言語による性能の変化について
開発言語によってはCopilotの恩恵が受けられない可能性がある
開発に用いているプログラミング言語によっては、Copilotの恩恵を受けることができないかもしれません。Copilotはコード生成AIであるCodexの生成結果を基にコードを提案しますが、CodexはGitHub上のソースコードを学習しているため、特にGitHub上でメジャーな言語においてその性能を発揮しやすいと言えます。その一方で、GitHub上でマイナーな言語では性能を発揮しにくいことが考えられます。例として、Pearceら[3]はGitHub上で比較的マイナーなVerilog言語を用いた際、Copilotが構文的に正しいコードを提案することが困難であったことを報告しています。
[6]では、2014年以降GitHubで最も利用されたプログラミング言語トップ10が紹介されています。これらの言語ではCopilotが性能を発揮しやすい可能性が高く、またGitHubもJavaScriptやPythonなどが特にCopilotが得意としている言語であると明言しています[7]。現時点では、Copilotはすべての開発言語に対して有用というものではなさそうです。
開発するシステムの要件について
提案されたコードの検証・修正のためにかえって手間となってしまう可能性も
Pearce[3]らの論文では、脆弱性が生じ得るような処理の実装においてCopilotを利用した際、Copilotが提案したソースコードのうち44%に脆弱性が含まれていたことを報告しています。特に高いセキュリティが要求されるようなシステム開発においてCopilotを利用した場合、プログラマはCopilotが提案したコードに脆弱性が含まれていないか検証する必要がありますし、場合によってはコードを修正したり、イチから書き直したり、といった手間がかえって生じるかもしれません。
ここではセキュリティ要件を例としましたが、Copilotが各開発システムの要件を満たすソースコードを生成・提案できるのかは、開発に導入する前に確認する必要があるかもしれません。
コード生成AIの内製について
学習データの準備が肝
SIerにおいては、GitHub上でメジャーでないプログラミング言語を使った開発案件や、インターネットにつながらない開発環境でも、コード自動生成ツールを使いたいというニーズがあるかもしれません。そのような場合、独自の生成AIを学習し、ツール化する方針も考えられます。
最初にCodexを発表したChenら[8]の論文によると、GitHub上のPythonソースコードから作成された159GB分のデータセット使ってCodexを学習したとのことです。Codexの性能を評価するにあたって、このデータセットを使ってさまざまなパラメータサイズのCodexを学習し、各モデルがk(k=1, 10, 100)種類のコードを生成したときの単体テストの通過率を報告しています。以下はCodexおよびその他のGPT系モデルと、類似したコード生成ツールであるTabnineの単体テスト通過率をまとめた表です(出典元:[8])。
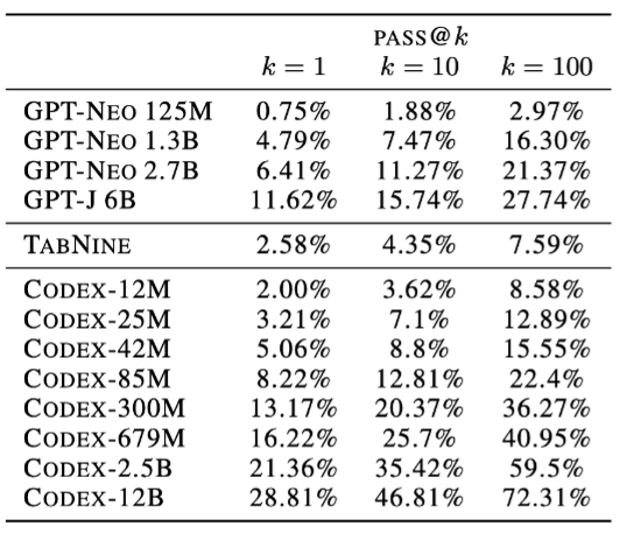
この表から、Codexや各GPTモデルのパラメータサイズが大きいほど、テスト通過率が高まることが分かります。特に、Codex-12B(B: Billion)が最も性能的には優れていますが、これを学習させるには膨大な計算リソースが必要となります。
一方、Codex-300M(M: Million)のような比較的小規模なモデルでも、他のGPTモデルやTabnineよりも高いテスト通過率を達成しています。性能的にはベストではありませんが、この規模のAIを学習させることは十分に可能です。
ただし、一般的にAIの性能を向上させるには十分な量と多様性のある学習データが重要であるとされています。この論文では学習データの多様性については述べられていませんでしたが、GitHubから収集された159GB分のデータセットにはある程度の多様性があると考えられ、上表で報告されている各Codexの性能はいずれもこのデータセットを使って達成されたものです。これらと同等の性能を持つコード生成AIを内製するためには、同規模かつ同程度の多様性を持つソースコードの用意とクレンジングなどの前処理を行う工数が必要となり、コード生成AIの内製においては一番の障壁となるでしょう。
おわりに
GitHub Copilotのようなソースコード生成ツールの一番のメリットは、実装例やドキュメントをウェブ上で探し回るといった手間を省くことができる点だと思います。もし、本記事で紹介したような開発環境や要件といった条件が揃う場合、積極的に導入・活用を進めることでこうした手間が省かれ、開発業務の効率化につながると考えられます。
ただし、Copilotは代わりにプログラムをしてくれる魔法のツールではなく、プログラマを支援するツールにすぎません。Copilotを利用するには、プログラマの側にも高い能力が必要とされるでしょう。例えば、提案されたソースコードを検証するための技術力、実装すべき内容を正しく言語化してコメントとして残す能力、Copilotの提案が常に正しいものではないという理解、といった能力・リテラシを身に付けることで、プログラマはCopilotを最大限に活用することができるのではないかと思います。
参考文献
[1] Finnie-Ansley, James et al. “The Robots Are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming.” Australasian Computing Education Conference, Feb. 2022, https://doi.org/10.1145/3511861.3511863.
[2] Madi, Naser Al. “How Readable is Model-generated Code? Examining Readability and Visual Inspection of GitHub Copilot.” In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE '22). Association for Computing Machinery, New York, NY, USA, Article 205, 1–5. Jan. 2023, https://doi.org/10.1145/3551349.3560438.
[3] Pearce, Hammond et al. “Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions.” 2022 IEEE Symposium on Security and Privacy (SP), May 2022, https://doi.org/10.1109/sp46214.2022.9833571.
[4] Kalliamvakou, Eirini. “Research: Quantifying GitHub Copilot’s Impact on Developer Productivity and Happiness.” The GitHub Blog, 17 Mar. 2023, https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness. Accessed 7 Jun. 2023.
[5] Vaithilingam, Priyan et al. “Expectation Vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models.” CHI Conference on Human Factors in Computing Systems Extended Abstracts, Apr. 2022, https://doi.org/10.1145/3491101.3519665.
[6] GitHub, Inc. “The Top Programming Languages.” The State of the Octoverse, https://octoverse.github.com/2022/top-programming-languages. Accessed 7 Jun. 2023.
[7] GitHub, Inc. “Getting started with GitHub Copilot.” GitHub Docs, https://docs.github.com/en/copilot/getting-started-with-github-copilot#seeing-your-first-suggestion. Accessed 7 Jun. 2023.
[8] Chen, Mark et al. “Evaluating Large Language Models Trained on Code.” arXiv.org, 7 July 2021, arXiv:2107.03374. Accessed 7 Jun. 2023.