1.最初に
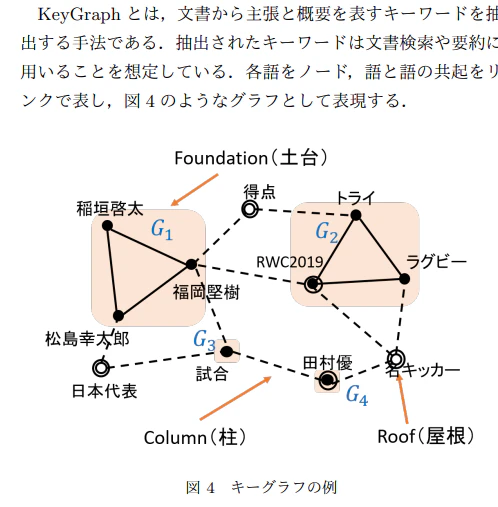
- 特徴語の抽出方法(にも使える方法)で keyGraph®というものを発見。文章中の単語(など)を「土台」と「柱」と「屋根」に分けて、「屋根」に相当する単語(など)をその文章の重要部分(主張)と判定するようだ。
- いろんな土台から強い柱で支えられている屋根は確かに重要な言葉と直感的に感じたのでやってみたい。
(出典:「TopK アルゴリズムを用いた連続 KeyGraph SNS 上のキーワード」)
-
東京大学の大澤・早矢仕研究室が10年ほど前に開発したアルゴリズムだそうで。公開されているツールも発見。登録商標も発見(1、2)
-
現在取り組んでる特許データと有価証券報告書の研究開発部分について、tfidfの補完となるような抽出ができないかコードを組んでみた。
2. さっそくプログラムを作成
- 具体的なソースコード(アルゴリズム)があまり書いてないのだが、下記2つの論文に抽出STEPがあったのでそれを見ながら試行錯誤。論文ではさらに先をいっているようですが。
「連続KeyGraphによるソーシャルネットワーキングサービス上の要約」
「KeyGraph による主張点の極性評価」
20220606:もっと詳しい解説がある論文を発見したのでこちらの方法で書き換え予定
3. コード
論文の説明からコードを組むのが難しかった。最後の屋根とか特に
STEP0:事前準備
#必要なライブラリ入れる
!pip install pyvis
!pip install tinysegmenter
!pip install janome
#吉野データをローカルにダウンロード
!curl -o yoshino.csv https://storage.googleapis.com/yoshino/yoshino.csv
#@title 事前準備
import numpy as np
import pandas as pd
import tinysegmenter
from janome.tokenizer import Tokenizer
from janome.analyzer import Analyzer
from janome.tokenfilter import *
from janome.charfilter import *
def wakati_ts(text):
wakati_list = segmenter.tokenize(text)
rev_wakati_list = [y for y in wakati_list if len(y)]
return '|'.join(rev_wakati_list)
# アナライザーのフィルター
char_filters = [UnicodeNormalizeCharFilter(), RegexReplaceCharFilter(r"[IiⅠi?.*/~=()〝 <>::《°!!!?()-]+", "")]
tokenizer = Tokenizer()
token_filters = [POSKeepFilter(["名詞"]), POSStopFilter(["名詞,非自立", "名詞,数", "名詞,代名詞", "名詞,接尾"]),LowerCaseFilter()]
a = Analyzer(char_filters=char_filters, tokenizer=tokenizer, token_filters=token_filters)
def wakati_janome(text):
stopwords = ["下記","手段","課題","特徴","範囲"]
return "|".join([token.surface for token in a.analyze(text) if not (token.surface in stopwords or len(token.surface)==1)])
segmenter = tinysegmenter.TinySegmenter()
def make_co_occur_df(dataframe,colname,sep):
df_co_occur_network = \
pd.merge(dataframe[colname].str.split(sep,expand=True).stack().reset_index(),
dataframe[colname].str.split(sep,expand=True).stack().reset_index(),
on="level_0",how="outer")\
.pipe(lambda df: df[df["0_x"] != df["0_y"]])\
.groupby(["0_x","0_y"],as_index=False).size()\
.reset_index()\
.rename(columns={"0_x":"source","0_y":"target",0:"weight"})\
.pipe(lambda df:df[pd.DataFrame(np.sort(df[['source','target']].values)).duplicated()])
#20210408最終行追加
#source,target,weight(共起回数)のdfを返す。
return df_co_occur_network
import networkx as nx
import pandas as pd
df = pd.read_csv("yoshino.csv",encoding="cp932")
#df['wakati'] = df['要約'].str.replace("【目的】","").apply(wakati)
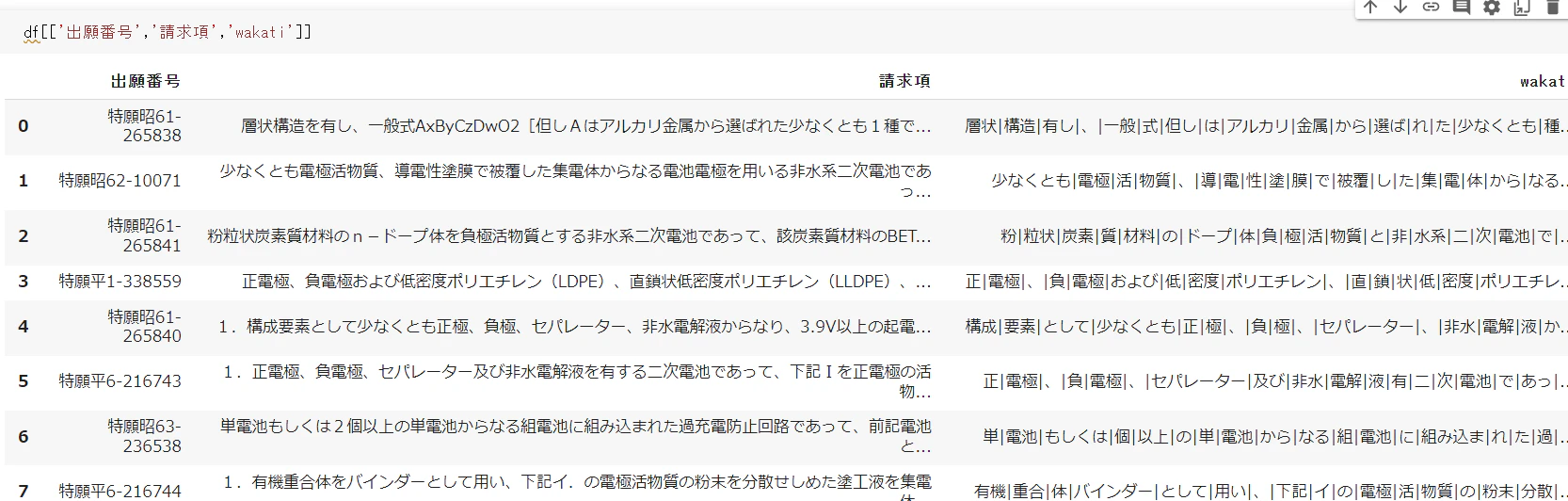
df['wakati'] = df['請求項'].astype(str).apply(wakati_janome)
edges = make_co_occur_df(df,"wakati","|")
- 分かち書き後はこんな感じ
STEP1:土台語の抽出

これは集計だけなので簡単。
#@title STEP1:文書中の単語の出現頻度を算出し,頻出語上位 M 語を土台語とする
#上位M語の指定
nodeM = 200
edgeM = nodeM-1
#間違え:node_freq_list = pd.concat([edges['source'],edges['target']]).value_counts()
node_freq_list = df['wakati'].str.split("|",expand=True).stack().value_counts()
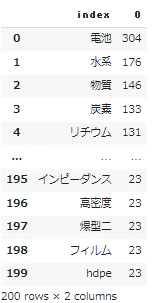
base_words_list = node_freq_list[0:nodeM].index.tolist()
- 上位語。もっと意味なさそうな言葉を削ってもいいかも
STEP2: 土台語のクラスタの生成


※「共起度」についていくつか計算方法があるようだが、こちら(後者)を採用
#@title STEP2 :頻度上位 M 個の単語同士の共起度 Co を測り,共起度の高い順にソートし,M-1 番目までに単語同士に枝を張る.共起度 Co に関しては Jaccard 係数を用いる.
#共起dataframeからjaccard共起度計算
#HighF req 中で文書 D における共起度の高い語の対を、それぞれ枝 (リンク) で結ぶ。ここで語の対の共#起度 co(wi, wj ) は、式 2.3 のように文 s における語の出現回数の積の総和で定義される。
#|x|s は文 s における要素 x の出現回数で、 x が語の場合に |x|s は文 s 中の語 x の出現回数になる。key(w) の対象となる語 w は、文書 D における特徴語となり得る全ての語である。
#すなわち文書 D よりストップワードに含まれる語を除いた全ての語となる。
def calc_C0(dataframe):
and_df = dataframe[["source","target","size"]].rename(columns={"size":"and_sum"})
or_df1 = dataframe.groupby("source",as_index=False).sum().rename(columns={"size":"or1_sum"})
or_df2 = dataframe.groupby("target",as_index=False).sum().rename(columns={"size":"or2_sum"})
jac_df = pd.merge(pd.merge(and_df,or_df1),or_df2,left_on="target",right_on="target")\
.assign(jaccard=lambda df:df["and_sum"]/(df["or1_sum"]+df["or2_sum"]-df["and_sum"]))
return jac_df[["source","target","jaccard"]]
C0_df = edges[(edges['source'].isin(base_words_list))|(edges['target'].isin(base_words_list))]
C0_df = calc_C0(edges)
base_edges = C0_df.sort_values(by="jaccard",ascending=False).head(edgeM)
STEP3:土台の抽出

#「強連結」(直接リンクを削除してもつながっているか)の判定関数
def haspath(rows):
source = rows['source']
target = rows['target']
G = nx.from_pandas_edgelist(base_edges, edge_attr=True)
G.remove_edge(source, target)
return nx.has_path(G,source,target)
#Step3: 土台の抽出
#Step2 で張ったリンクのうち,強連結を形成するリンク以外を削除する.
#強連結とは対となるノード wi,wj において wi,wj 間のリンクを削除しても他のノードを経由することによって他方のノードに到達できる場合のことを指す
base_edges["strong_connect"] = base_edges.apply(haspath,axis=1)
strong_base_edges = base_edges[base_edges['strong_connect']==True]
STEP4:柱の抽出

※共起度Basedの計算が怪しいが「共起度」はjaccardとしてる。
#@title STEP4:文書内の全ての単語と土台の単語の共起度を算出する.
#文書内の全ての単語の抽出
node_df = node_freq_list.reset_index()
strong_base_edges_G = nx.from_pandas_edgelist(strong_base_edges)
#土台の単語群抽出
base_node_list = list(strong_base_edges_G.nodes())
#柱(橋)の抽出
bridge_df = C0_df[(C0_df["source"].isin(base_node_list))|(C0_df["target"].isin(strong_base_nodes_list))]
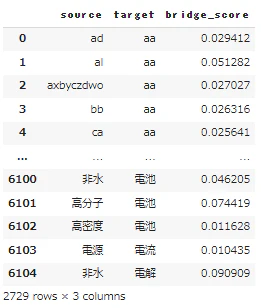
bridge_df.rename(columns={"jaccard":"bridge_score"},inplace=True)
- node_dfの様子(bridge_scoreに、各土台語と単語とのjaccard共起度が入っている)
STEP5:屋根の抽出

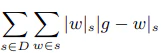
ってどうやって作るのか悩んだ結果、さきほど作成した表の土台語(targetの方)毎にbridge_scoreの合計をとって分母にする処理を加えればいいんじゃないかということで計算。「key」というのが最終的に欲しい数値
#@title STEP5 keyの計算&屋根抽出
#key上位の単語(屋根)の抽出
headR = 50#@param {type:"integer"}
#橋の可視化の基準(0-1)
BRIDGE_SCORE_CRIT = 0.01 #@param {type:"number"}
sum_bridgescore_df = bridge_df.groupby(["target"],as_index=False)["bridge_score"].sum()
keydf = pd.merge(bridge_df,sum_bridgescore_df.rename(columns={"bridge_score":"bridge_scoresum"}))\
.assign(temp_score=lambda df:1-df["bridge_score"]/df["bridge_scoresum"])\
.groupby(["source"],as_index=False)["temp_score"].prod()\
.assign(key=lambda df:1-df["temp_score"])\
.sort_values(by="key",ascending=False)\
.rename(columns={"source":"target"})
#keyに基づく屋根の抽出
roof_node_list = keydf["target"].head(headR).tolist()
bridge_df2 = bridge_df[bridge_df["target"].isin(roof_node_list)]
roofwd_top_df = bridge_df2[bridge_df2["bridge_score"]>=BRIDGE_SCORE_CRIT]
#roofwd_top_df = bridge_df2[bridge_df2["bridge_score"]>=BRIDGE_SCORE_CRIT]
#土台語のdataframeにkey上位の単語(屋根)を含む共起dataframeを連結
alledge_df = pd.concat([
strong_base_edges[["source","target","jaccard"]].rename(columns={"jaccard":"bridge_score"})
,
roofwd_top_df[["source","target","bridge_score"]]#.rename(columns={"score2":"score"})
])
- node_df2

4.結果
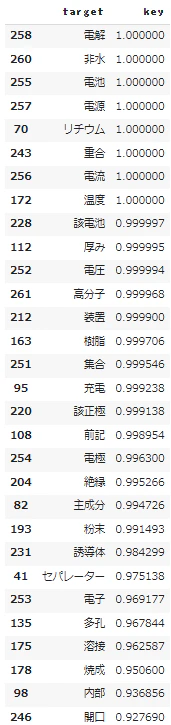
上記のとおり、昔使った吉野特許群の「特許請求の範囲」で「屋根」にあたる単語群を抽出。
う~ん・・・結構一般的な語が出てるので重要語か微妙?
keydf[["target","key"]].head(30)
5. 可視化
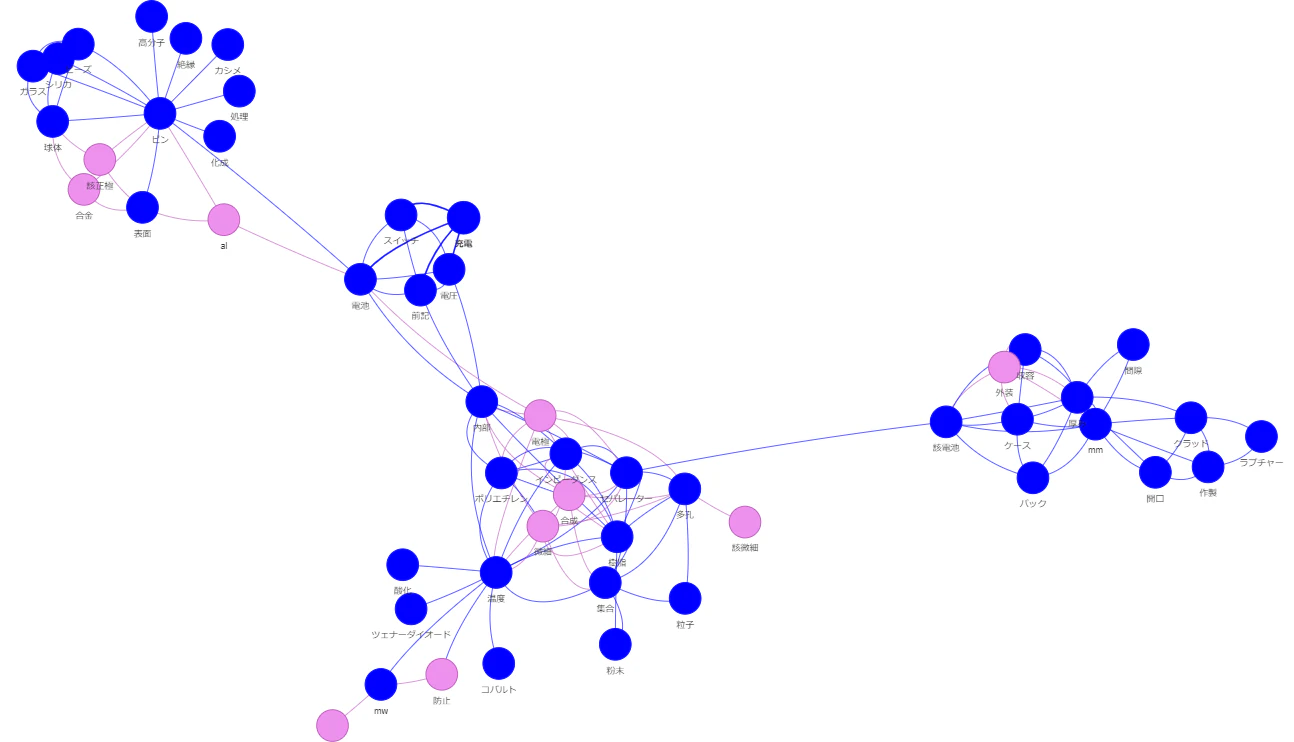
- おなじみpyvisを利用させてもらう。
土台
- 結構よさそう

柱と屋根の追加結果
ピンク色=屋根語、青色=土台語、ピンク線=柱
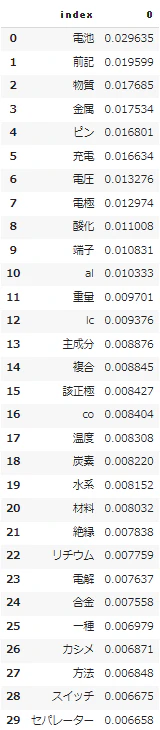
6. tfidfの抽出結果との比較(作成中)
- 結構違う感じに出てきてくれてるので、補完としていいかもしれない。topicmodelなどを追加してみたい
| keygrap | tfidf |
|---|---|
|
 |
|
7. その他
- すでにpythonのコードもあったので要確認。
- networkx2.XXのhas_path関数など便利な機能があるのを発見できてよかった。
- pandasのgroupby後のprodという関数を始めて使った。
- 基本的に文章群の入ったdataframeを投入したら図やデータがかえってくる形に整理したい。
- BigQueryで作りたいけど、現状イメージできない。
- 文章が多くなると、自作のmake_co_occur_dfでクラッシュするので要改善!