1.はじめに
- 最近使えるようになったBigQuery Data Framesを試し。
- 後ろではBigQueryが処理を行ってくれているので、レコード数が多くてもサクッと処理してもらえる。
- MLやPaLM2との連携が簡単なので、今までBigQueryとpandas(polars)で連携してやってきた処理が代替できそう。
2.参考情報
- 下記のように、概要からMLまではすでに紹介されているので、自前のデータでPaLM2との連携部分を試してみた。
公式
BigQuery DataFramesを使ってみる
Google launches BigQuery Data Frames
3. PaLM2による固有表現抽出
- 使ったのは、蓄積しているテクノロジー系のニュース。
!pip3 install --upgrade bigframes
import bigframes.pandas as bpd
bpd.reset_session()
bpd.options.bigquery.project = "****"
df1 = bpd.read_gbq("****.techchurchnews.dailynews3")
df1
こんな感じで確かにpandasの処理に似てて楽です。
- ここから公式ページなどを見て実行していく。
import bigframes.ml.llm as llm
palm2generator = llm.PaLM2TextGenerator(
connection_name="****",
)
とやると、エラーが出てしまう。公式ではproject-idを指定すればいいような書きっぷりだったけど。。
ValueError: connection_name must be of the format <PROJECT_NUMBER/PROJECT_ID>.<LOCATION>.<CONNECTION_ID>, got ****.
<CONNECTION_ID>ってなんだ?となって、調べた結果、ここを参考しつつ下記のように発見。
from google.cloud import bigquery_connection_v1 as bq_connection
def main(
project_id: str = "your-project-id", location: str = "US", transport: str = "grpc"
) -> None:
"""Prints details and summary information about connections for a given admin project and location"""
client = bq_connection.ConnectionServiceClient(transport=transport)
print(f"List of connections in project {project_id} in location {location}")
req = bq_connection.ListConnectionsRequest(
parent=client.common_location_path(project_id, location)
)
for connection in client.list_connections(request=req):
print(f"\tConnection {connection.friendly_name} ({connection.name})")
main(project_id="****",location="US")
main(project_id="****",location="US")
List of connections in project **** in location US
Connection (projects/**/locations/us/connections/{~~})
この~~の部分をconnectionに設定すればいいと判明して使う。
import bigframes.ml.llm as llm
palm2_text_generator = llm.PaLM2TextGenerator(
connection_name="****.US.~~",
)
これでpalm2_text_generatorができるので、ここを参照しつつprompt列を作成。
df1["prompt"] = "Please extract the named entity:" + df1["title"]
df1["prompt"]
palm2_text_generator.predict(df1[["prompt"]])
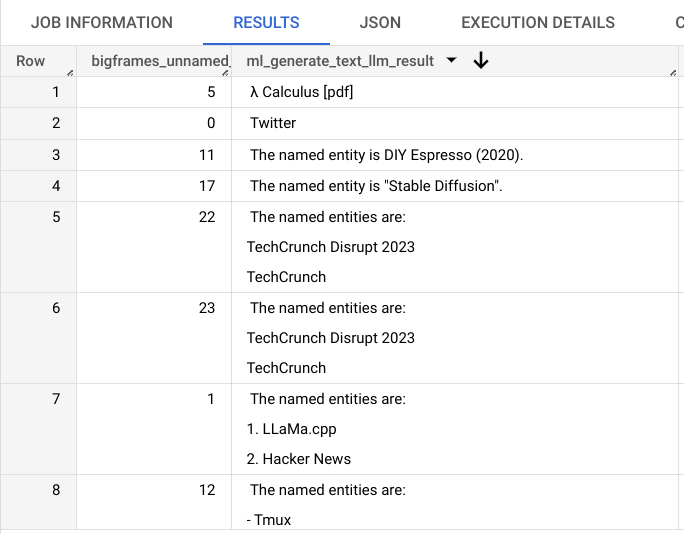
実行結果のjobを開くとこのような感じ(ml_generate_text_llm_result部分)。一部言うことを聞いてくれてない様子だけど、promptの工夫でどうにかできるのではないかと検討中。
4.その他
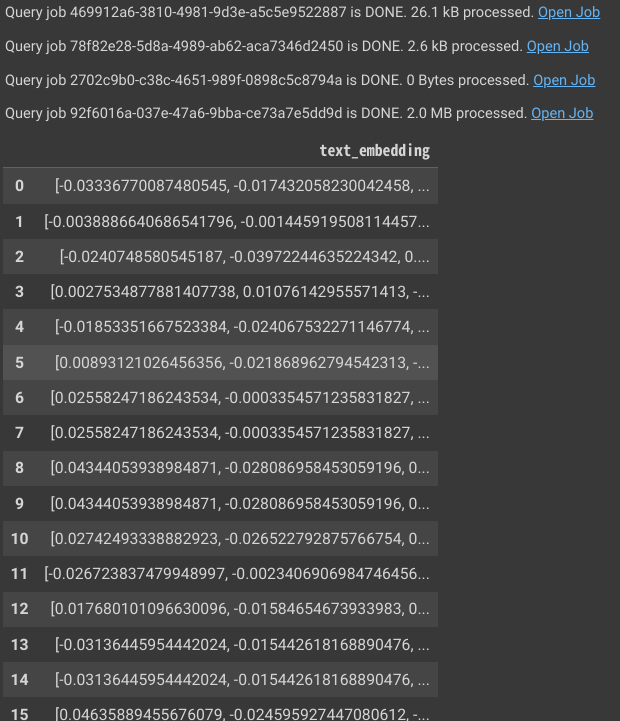
- なお、PalM2のembedding表現を取得したい場合は
palm2embedder = llm.PaLM2TextEmbeddingGenerator(
connection_name="****.US.~~",
)
で
palm2embedder.predict(df1["title"])
と実行すればOK。こちらも1分間の実行制限に注意しつつ使えば、便利。