ACMのBias on the Web By Ricardo Baeza-Yates の抄訳です
Introduction
人間は、生活の自分が見る・聞く・行うなどすべての側面で潜在的で明白なバイアスを作り出す傾向があります
そのバイアスを改善するためには、まずバイアスが存在すると理解する必要があります。
例えば、発達した社会は、社会的な優遇措置を通じてバイアスを認識できますが、問題を緩和するわけではありません
Web上のバイアスは、自分自身の社会的なバイアスとウェブの内部的なバイアスが反映されています。
この記事では、Web利用とWebコンテンツに存在するバイアスを介して、私たちの潜在的な影響についての認識することを目指しています。
そして人々のニーズを真に対応するWebシステムの設計ではバイアスを考慮する必要があることをおしらせします
Bias on the Web from CACM
Key Insights
- バイアスの対処法は、そのバイアスの認知からスタートします
- Web上のバイアスは、内部ですでに偏っており、画面の表示された時点ですでに人を欺いています
- ユーザーのニーズに対応したWebベースのシステムの設計するにはバイアスを考慮する必要があります
バイアスは文化や歴史に組み込まれ続けてきましたが、デジタルデータの増加に伴いこれまで以上に速く広がり、今まで以上の多くの人々に影響を与えています。
バイアスは近年ビッグデータ内のトレンドや議論を呼ぶトピックです
一部の特別な人たちは、普段の生活の中で現れる内容(たとえば住宅ローンから広告パーソナライゼーション)がアルゴリズムによって支配されたデータバイアスの有害な影響があると感じています
バイアスは私たちの生活すべてに影響を与え、その上私たちが気付いていないほとんどの時間で、(否定的な)判断と行動に影響を与えるいるため、バイアスは重要な障害となっています
今日のWebは最も重要なコミュニケーションチャネルであり、そしてバイアスが集中している場所です。
日々の生活の中にソーシャルメディアが組み込まれ、以前はなかったインフルエンサーに晒されています
これにより、これまで以上にWeb上のバイアスを理解し認識することが必要です。
ここでの私の主な目標は、すべてのWeb上のバイアスの認知レベルを上げることです。
バイアスを認知は、一般的なソフトウェアシステムだけでなく、優れたWebベースのシステムの設計にも役立ちます。
バイアスの測定
バイアスに対処する最初の課題は、バイアスを定義し測定することです
統計的観点からみると、バイアスは不正確な推定又はサンプリングプロセスによって引き起こされるシステムの偏りといえます
さらに、文化的バイアスによって私たちの共通の個人的な信念が偏り、認知バイアスは私たちの行動や判断基準に影響を及ぼします
図1は、Webの成長とその利用にバイアスがどのように影響するかを示しています。
まずはそれぞれのバイアス(赤色)について説明し、種類別に分類します。
人々がウェブをどのように使用するか、インターネットにアクセスできない人々の隠れたバイアスに起因するアクティビティバイアスから始めます
次に、Webデータのバイアスと、それを使用するアルゴリズムにより潜在的に汚染されるかを説明します
そして、ウェブサイトとのやりとりやコンテンツや使用方法がWebベースのシステムがリサイクルされてあらたにバイアスが生み出されます、最後にさまざまなタイプの2次バイアスを作成されます
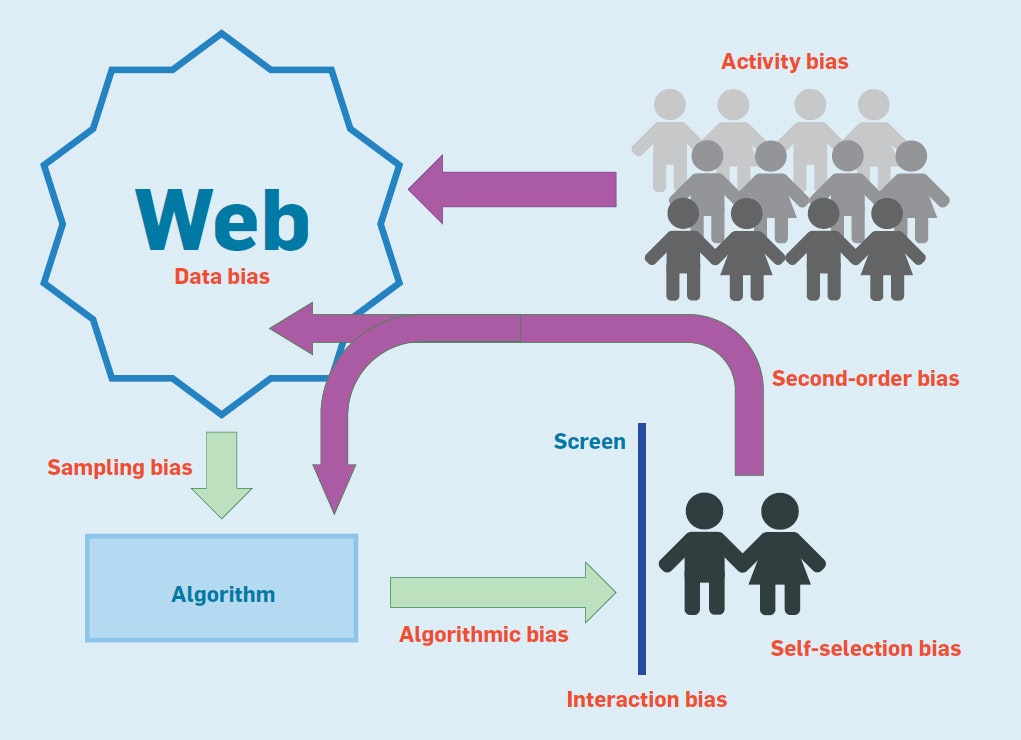
Web上のバイアスに関する調査の次として、調査の方法論的な側面ではなく、特定されたバイアスの重要性に焦点を当てて、個人的に関わった記事(dl.acm.org/citation.cfm?doid=3209581&picked=formats)があります。
アクティビティバイアスまたは少数の知恵
2011年、Wu氏他の調査によると、Twitter上では最も人気のある人々0.05%が全フォローワーのほぼ50%を占めていることが分かりました:つまり、Twitterユーザーデータセットのうち半数は、ほんの一部の選ばれた有名人となります。
質問です:Web上のソーシャルメディアのコンテンツ半分のうちアクティブなWebユーザーが占める割合は何パーセントですか?
(著者は)Webを見るだけの書き込みはしないWebユーザーのサイレントマジョリティを考えませんでした。これも自己選択バイアスの一形態です。
Saez-Trumperと 著者が分析した4つのデータセットの詳細結果は驚くべきものでした
- 2009年からのFacebookのデータセットを調査したところ、上位7%(約4万人)のアクティブユーザーが投稿の50%を占めていました。
- より大きい2013年からのAmazonのレビューのデータセットでは、上位4%アクティブユーザーの投稿で50%となりました
- もっと大きい2011年からtwitterのデータセットでは上位2%(約1,200万人)のアクティブユーザしか必要ありません
- 最後に、最初のバージョンの英語版Wikipediaでは、半分の記事は編集者の約0.04%(約2,000人)に投稿されました。これは、全ユーザーのわずかな割合しかWebに貢献していないことをしめします。このことは集合知は幻想ということを示しています
このような知見に照らして、4%の人だけがAmazonのデータセットの半分のレビューをかいていることにいみはありません。
私は何か他のものが遊んでいることを感じました。
A month after publication of our results, my hunch was confirmed.
2015年10月、アマゾンは有料の偽レビューを防止するキャンペーンを開始し、2016年に1,000人ものレビュワーが摘発されました
私たちの分析では、一部の人が参考にしたレビューだけだと2.5%に減少しています。ユーザー別の平均的な有用性とテキスト品質のプロキシとの間に正の相関関係があります
英語ウィキペディアの始まりにある2,000人の人々が、ウィキペディアが今日の広大な百科事典資源となったのを助けた雪だるまの効果をおそらく引き起こしたでしょう。
Zipfの最小労力原則は、ジップの法則とも呼ばれます
多くの人がほんの少しだけ行うのを維持しているが、活動バイアスの大きな部分を説明するのに役立つ人は少ない。
例えば、ジップの法則は、Webサイトごとのページ数やWebページあたりのリンク数など、ほとんどのWeb指標で見ることができます。
図2は、x軸上の英国のWebページにおけるリンクの数およびy軸上のWebページの数をプロットする。
ジップの法則は、より負の傾きを持つ線ではっきりと見えますが、x軸の始めに強い社会的勢力があります。私は「恥の効果」と呼んでいます。
また、ほとんどの人が自分の努力を恥ずかしく感じるのを避けるのに十分な気がしなければ、多くの人が最小限の努力を払うことを好みます。
これらの2つの効果は、Web上の人々の活動の共通の特徴です。
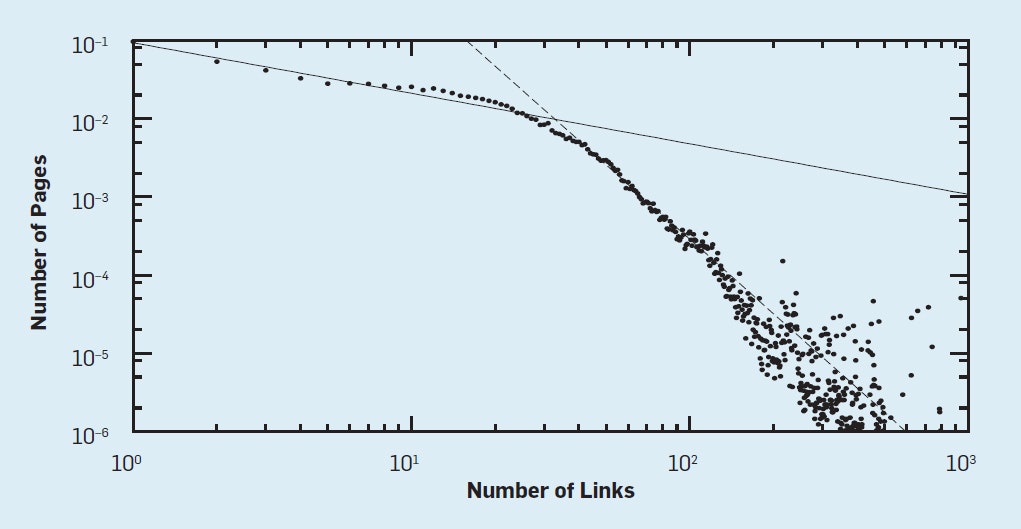
図2.12と13のリンクの交点を持つ、英国のウェブページ上のリンクの数に対する最小の努力(顕著な影響線)と恥の効果(小さい影響線)。
右端のデータは、Webユーザーや開発者ではなく、ソフトウェアによって書き込まれたページが原因と考えられます。
最後に、ノーベル賞受賞者ハーバート・サイモンは、「豊富な情報が注意の貧困を作成します。」と述べました
アクティビティバイアスは、Web上で「デジタル砂漠」を生み出し、誰も見られないWebコンテンツを生み出します。
Saez-Trumperと私が知っているツイートデータのうち、1.1%はフォロワーなしの人が書いて投稿したものです。
ウィキペディアの使用統計を確認すると、2014年5月に追加または変更された記事の31%が6月には決して訪れなかったと伝えられます。
ウェブ上のデジタル砂漠の実際のサイズは、1%から31%の範囲の前半にあると考えられます。
一方、バイアスは必ずしも悪ではありません。
活動の偏りのため、Webキャッシングのすべてのレベルは、最も使用頻度の高いコンテンツをすぐに利用できるようにする上で非常に効果的です。
そして、ウェブサイトや一般的なインターネットネットワークへの負荷は、潜在的に可能であるよりもずっと低くなります。
データバイアス
人々のスキルと同様に、データの品質もある程度は偏っていると予想されます。
情報を扱う政府機関、大学、およびその他の機関で働く人々は高品質で低バイアスのデータを公開していますが、ソーシャルメディアは品質が低くで偏ったデータが多くみられます
そしてソーシャルメディアに投稿している人の数は、おそらく情報を扱う機関で働く人々の数よりも少なくとも1桁大きいでしょう
どのような品質の定義であっても、高品質のデータを含めすべての人々から得られるより多くのデータがあります
そしてWeb上の多くの偽のコンテンツは、信頼できるコンテンツよりも速く拡散しているようです。
Webと対話する人々に見られる最初の一連のバイアスは、その人口統計によるものです。
インターネットにアクセスして使用することは、教育的、経済的、技術的偏見だけでなく、他の特性と相関し、Webコンテンツやリンクの偏りの波及効果を引き起こします。
例えば、最も人気のあるWebサイトの50%以上が英語ですが、世界のネイティブスピーカーの割合は約5%に過ぎないと推定されます。
これは、Wikipediaによって推定されるように、すべての英語の話者が含まれる場合、13%に増加します。
地理的偏見は、大都市や観光スポットに関連するWebコンテンツにも見られます。
Web上のバイアスのネットワーク効果の例は、ウェブ自体のリンク構造にも見られます
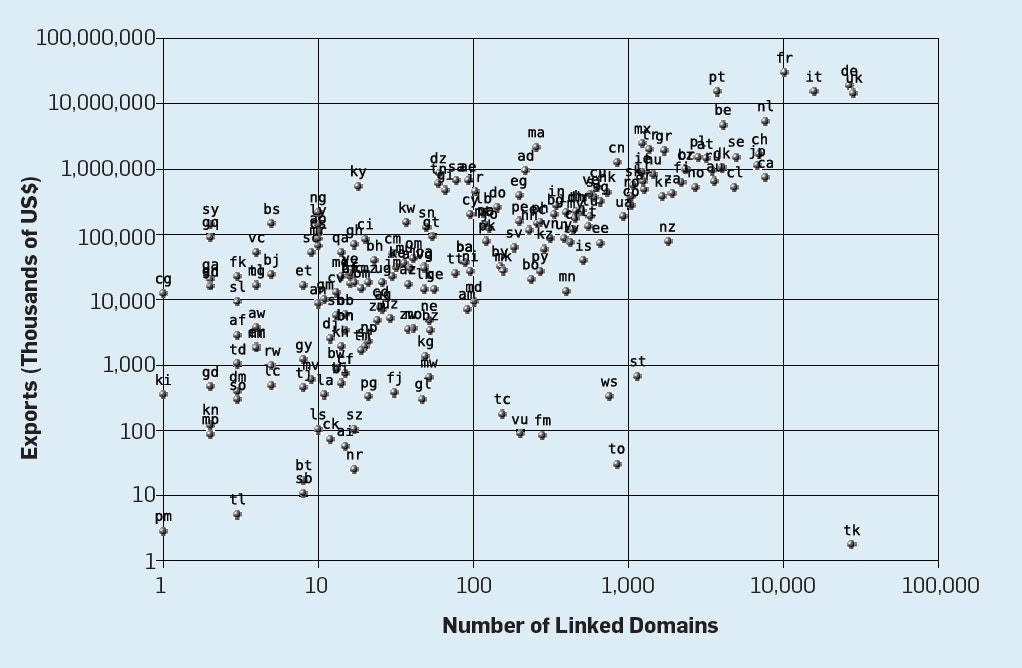
図3は、X軸がスペイン内への他の国へのリンク数をプロットし、Y軸がスペインから他への輸出金額を表しています
右下にある国は、外れ値です。彼ら(例えば.FMhミクロネシア連邦のトップレベルドメインのような)自分のドメインを使用する権利を販売しています
それらを無視して、輸出とリンク数の相関はスペインでは0.8以上です。
実際、国の発展が進んでいるほど大きくなります。例えばブラジルの0.6から英国の0.9までの相関が大きくなります
バイアスの第2のセットは、異なるタイプのバイアス同士の相互作用に起因します
図4を考察すると、Wikipediaの女性の伝記の割合をプロットしたもので、人間の歴史を通したジェンダーバイアスによって説明することができます。
基礎となる要素は、創造プロセスをより詳細に見ると深いバイアスを隠されていることがわかります
伝記のカテゴリでは、ウィキペディアの統計によると、ウィキペディアの編集者の12%未満が女性です。
他のカテゴリでは、ジェンダー偏向はさらに悪化し、地理的には4%に達します。
一方、公表されているウィキペディアの女性編集者の割合は11%に過ぎないため、伝記は実際にはわずかな正のバイアスを示しています。
ウィキペディアの編集者のすべてが性別を特定しているわけではないので、これらの値も偏っていることに注意してください。女性はこのように過小評価されるかもしれません。
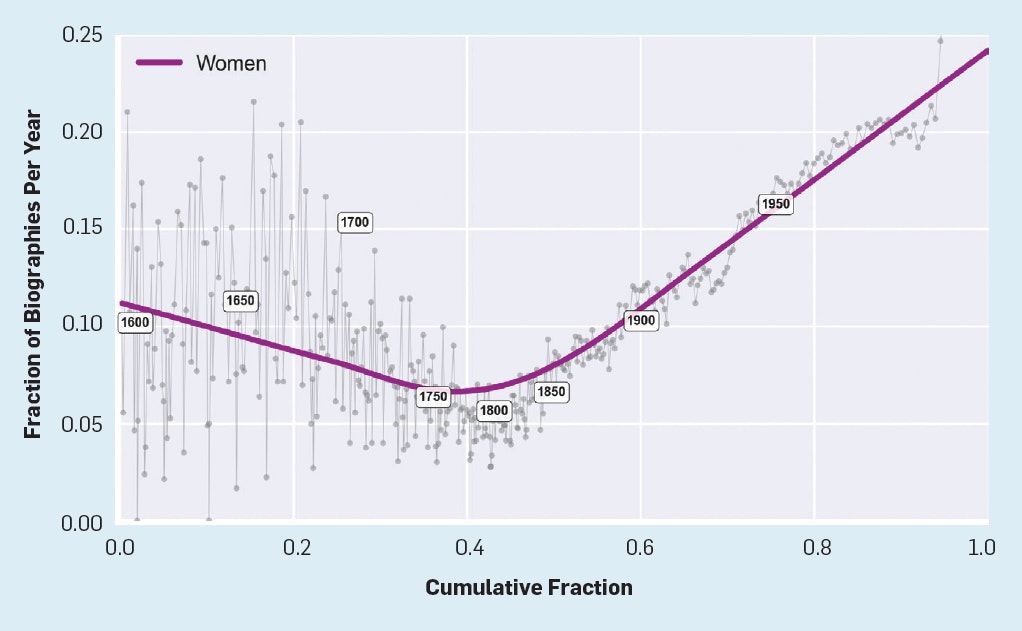
図4.ウィキペディアでの女性の伝記の累積割合
私たちの第3のデータバイアス源は、Webスパムです。これは、人間が作り出したよく知られた悪意のあるバイアスで、特徴づけが難しいものです。
2003年には、複製されたWebサイトなどのコンテンツ(ほぼ)複製にも同じことが適用され、静的なWebコンテンツの約20%を占めるようになりました
ほとんどすべてのバイアスを測定することは困難であるため、機械学習を使用した予測アルゴリズムへの影響を理解することも困難です。
Webデータは、そもそも人口の偏ったサンプルを表しているように、ソーシャルメディアに基づいた研究では、我々が均一に分布されていないことを確認することができず、エラーがかなりの量を有することがわかります
同じ理由で、そのような研究の結果を他の人口に外挿することはできません。
オンライン世論調査は、ライブ世論調査よりも良い結果を予測しても、例えば2016年米国大統領選挙における投票の誤差を思い出してください
他のエラーの原因には、データサンプル(選択バイアスによるものなど)によるバイアスや分析手法によるものがあります。
アルゴリズムバイアスと公平性
アルゴリズムバイアスはアルゴリズム自体によって追加され、入力データには存在しません。
入力データが実際にバイアスされている場合、メソッドの出力は同じバイアスを反映している可能性があります。
しかし、すべての可能なバイアスが検出された場合でも、アルゴリズムが進むべき方法を定義することは、人々があらゆる論争の問題に公正なソリューションです何かの上に反対するのと同じ方法で、一般的に困難です。
出力に実際にバイアスが含まれているかどうかを検出するのを助けるために、人間の専門家に電話する必要があります。
彼女-彼はワード埋め込みを通じてアナロジー学ぶために米国のニュースのコーパスを使用2016研究活動では、結果のほとんどは、クイーンとキングの代わりに看護師と外科医または歌姫とスーパースターして利用されていると報告しました。
Web検索は、米国ジャーナリズムの学校では男女の比率が逆転しているにもかかわらず、米国で影響力のあるジャーナリストの約70%が男性であることが示されました。
したがって、ニュース記事から学ぶアルゴリズムは、実証的かつ全身的なジェンダー偏見を伴うテキストから学習しています
しかし、他の研究は、他の文化的および認知バイアスの存在を確認しています
一方、一部のWeb開発者はバイアスを制限することができました。
ジェンダーバイアス問題の「バイアス」は、ジェンダー部分空間を自動的に分解することによって対処することができます。
ニュースの地理的バイアスに関しては、大都市や政治中心地が確実に多くのニュースを生成する。
標準的な推薦アルゴリズムが使用される場合、一般市民は、彼らが住んでいる場所からではなく、首都からのニュースを読む可能性が高い。
ダイバーシティとユーザーの位置を考慮すると、Webデザイナーは、地域のニュースも表示する、一元化されていないビューを提供するWebサイトを作成することができます。
インタラクションデザイナーによって導入されたインタラクションのバイアスに加えて、ユーザーの自己選択バイアスがあります。
インタラクションデザイナーによって導入されたバイアスに加えて、ユーザーには独自の自己選択バイアスがあります。
インタラクション上のバイアス
バイアスの重要な原因の1つは、Webだけでなく、2つの注目すべきソースからのユーザー対話です。ユーザーインターフェイスとユーザー自身が選択したバイアスされた対話です。
最初のものは「プレゼンテーションバイアス」であり、ユーザーが見たものすべてがクリックを得ることができ、それ以外はすべてクリックが得られません。これは特に推奨システムでの関連です。
潜在的に提供される可能性のある数百万に比べて数が非常に少ないにもかかわらず、ユーザーが閲覧できる何百もの推奨事項を有するビデオストリーミングサービスを考えてみる。
このバイアスは、ユーザーが見たことのない新しいアイテムやアイテムに直接影響を与えます。そのための使用データがないためです。
最も一般的な解決策は、Webに適用される古典的な例を学んだAgarwalらのように、「探索と悪用」と呼ばれています。
これは、ユーザートラフィックの一部を新しいアイテムに公開し、探索するために推奨される最高のものをランダムに混在させ、選択された場合は、使用データを利用して真の相対価値を明らかにする。
そのような解決策のパラドックスは、探査が既に知られている情報を利用するための損失または機会費用を意味する可能性があるということです。
場合によっては、収益の損失(デジタル広告など)もあります。
しかし、(新しい)良品を学び発見する唯一の方法は探検です。
ポジションバイアスは、最初に画面の左上隅に向かって見て、より多くの目とクリックを引き付けるように促します
上位ランクの結果は他のランキングよりも魅力的なクリックになります ランク付けのバイアスを避けるために、ウェブ開発者は、クリックデータを使用してランク付けアルゴリズムを改善し評価できるように、クリック分布をバイアス解除する必要があります。そうしないと、人気の高いページがさらに人気を集めます。
ユーザインタラクションの他の偏りには、ユーザインタラクションデザインに関連するバイアスが含まれる。例えば、ユーザがスクロールして追加のコンテンツを見ることが必要なウェブページは、プレゼンテーションバイアスのようなバイアスを反映する。図5は、ユニバーサル検索(複数のタイプの回答)が導入され、非テキストコンテンツが結果ページの位置バイアスに反した後の、視線追跡研究の例を示している。右はさらなる注意を引くだろう。
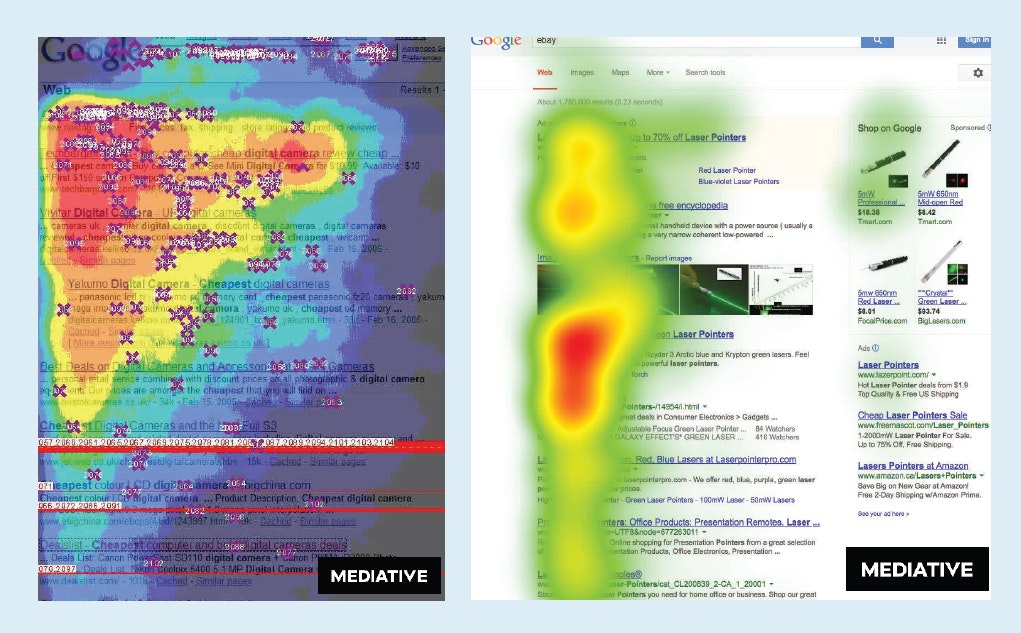
図5. 2005年(左)から2014年(右)までのWeb検索結果ページ上の視線追跡分析ヒートマップ.
社会的なバイアスは、他の人からのコンテンツは、当社の判断にどのように影響するかを定義します。
協調的評価を伴う例を考えてみましょう:私たちは、低得点でアイテムを評価するとし、ほとんどの人はすでにそれを高得点を与えていることがわかります。
私たちはおそらく私たちがあまりにも厳しいと思っているだけで、スコアを上げるかもしれません。
そのようなバイアスは、Amazonのレビューデータの文脈で探求されており、しばしば「社会適合性」または「放牧(ハーディング)効果」と呼ばれている。
最後に、ユーザーがあらゆるタイプのデバイスと対話する方法は特有のものです。ユーザーの中にはクリックしたくなる人もいれば、マウスを見た目に移動させるユーザーもいます。
マウスの動きは、注視の注意のための部分プロキシであり、したがって、計算上安価な視線追跡の置換である。
私たちの中には、スクロールバーに気づかない人もいれば、細かく読む人もいれば、スキムを好む人もいます。
インタラクションデザイナーによって導入されたバイアスに加えて、ユーザーには独自の自己選択バイアスがあります。
Whiteは、文化バイアスおよび認知バイアスがWeb検索エンジンにどのように影響するかを示す良い例を探求し、ユーザーが既存の信念に沿った回答を選択する傾向があることを示しています。
バイアスがないどんな試みもすでに私たちの文化および認知によって偏っているかもしれないので、最初のステップはバイアスを知ることです。
バイアスは複雑なことに相互作用を介してシステムをカスケードするためにWeb開発者がバイアスを分離しようとすることは非常に困難になります。
図6は、バイアスがどのようにカスケードし互いに依存するかの例を説明しており、Web開発者は常にその組み合わせ効果を見ていることを意味しています。
同様に、スクロールするのを好むユーザーは、マウスの移動方法や、画面のどの要素をクリックするかにも影響します。
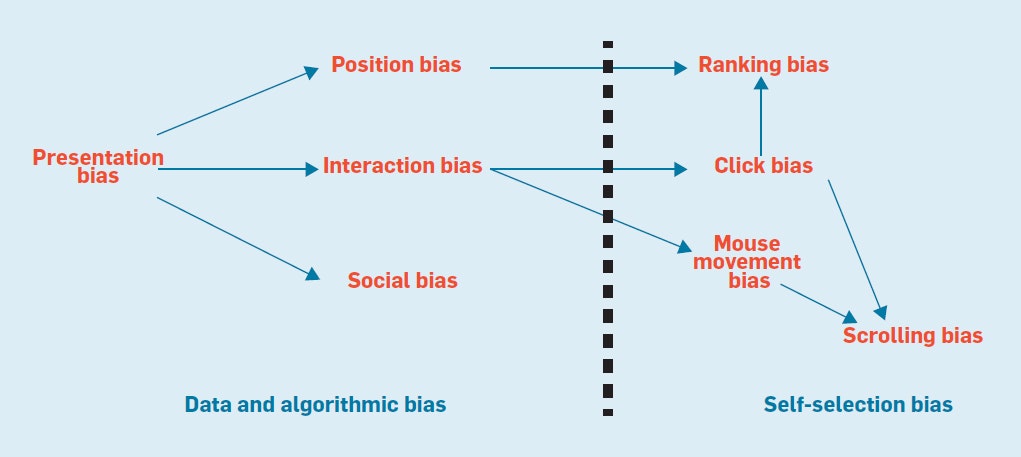
図6.ユーザーの相互作用に影響するバイアスの依存グラフ
インタラクション上のバイアスは、暗黙的なユーザフィードバックによって最適化されているWebシステムが多いため、Webサイトの全体的なパフォーマンスだけでなく、ユーザエクスペリエンスの分析にも不可欠です。
最適化されたシステムは、機械学習に基づいているため、システムの外部リンクによるバイアスや、バイアスを強化するなソリューションにより予言の自己実現を生み出すことを学びます。
これらのシステムは、逆相関した最適化機能を使用する別のものの劣化から1つの改善が生じるように、それら自体の間で競合する。
クラシックな例としては、ユーザーエクスペリエンスの向上と収益の増加(広告の比例数が一般にユーザーエクスペリエンスを低下させる方法など)の間の逆相関があります。
バイアスによる悪循環
バイアスはバイアスを生み出します。
私たちが次のブログ記事を企画しているブロガーであると想像してみましょう。
次に、私たちに関係があると思われるいくつかの情報源を選択します。
私たちはこれらの情報源からいくつかの引用を選択します。
私たちは新しいコンテンツを書いて、適切な場所に引用を入れてリンクを貼ります。
最後に、新しいエントリをWebに公開します。
このコンテンツ作成プロセスは、ブログだけでなく、レビュー、コメント、ソーシャルネットワークの投稿などに使用されるコンテンツにも当てはまります。
メッセージを流出させる問題は、使用されている検索エンジンが関連しているものに基づいてコンテンツのサブセットが選択された場合に発生します。
したがって、検索エンジンのランキングアルゴリズムは、Web上の特定のトピックの成長を偏らせます
私の同僚と私が2008年に行った調査によると、チリのウェブ上のコンテンツの約35%が複製されており、それらのページの部分的(意味的)な複製の系譜を追跡することができました。
今日では、意味論的複製の効果は、さらに広範かつ誤解を招く可能性があります。
このプロセスでは、二次的なバイアスの悪循環が生まれます。一部のコンテンツプロバイダーがランキングを上げてクリック数を増やす、つまり金持ちがより豊かになるからです。
さらに、コンテンツの複製は、不良ページと良品ページを区別する問題を複雑化するだけである。
次に、Webスパマーは、良いページのコンテンツを品質の高いコンテンツとして使用し、問題のあるコンテンツを追加します。
すべてのバイアスを考慮しない限り、検索エンジンは悪くなっていきます
二次バイアスの別の例は、Webコンテンツに影響を与えず、ユーザーに公開されるコンテンツに影響するパーソナライゼーションアルゴリズム(フィルターバブル効果など)に由来します。
パーソナライゼーションアルゴリズムが私たちのインタラクションデータだけを使用する場合、私たちは見たいものだけを見て、私たちが実際に好きかもしれない新しいアイテムに閉じ込められた閉じた世界に私たちを保ち、コンテンツを自分たちの選択バイアスに偏らせます。
この問題は、コラボレーションフィルタリングやタスクのコンテキスト化、多様性、新規性、偶然性、さらには要求された場合でも、私たちに他の側面を与えることによって打ち消されなければなりません。
このような技術を組み込むことによって、より少ない個人情報が必要となるため、これはオンラインプライバシーにプラスの効果をもたらします。
| Bias Type | Statistical | Cultural | Cognitive |
|---|---|---|---|
| Algorithmic | ● | ? | ? |
| Presentation | ● | ||
| Position | ● | ||
| Sampling | ● | ||
| Data | ● | ● | ● |
| Second-order | ● | ● | ● |
| Activitiy | ● | ● | |
| User Interaction | ● | ● | |
| Ranking | ● | ● | |
| Social | ● | ● | |
| Self-Selection | ● |
表 統計、文化および認知バイアスの組み合わせ
Conclusion
バイアスの問題は、私がここで概説したよりもはるかに複雑で、ここでは一部だけを取り上げています。
確かに、この基盤は私たちの個人的なバイアスのすべてに関係しています。
これとは対照的に、ここで説明されているバイアスの多くは、Webエコシステム(モバイルデバイスやIOTなど)以外にも顕在化しています。
ここの表は、前述した3つのタイプのバイアスに対してすべての主なバイアスを分類することを目指しています。
- 最上位はアルゴリズムバイアス
- アクティビティバイアス、ユーザ操作バイアス、
- 自己選択バイアス - 人から来たものを含む。また、中間の一次バイアスと2次バイアスには、両方が含まれます。
最初の行の疑問符は、各プログラムが作成者の文化バイアスおよび認知バイアスをエンコードしている可能性があることを示しています。
この主張を支持する1つは、世界的な群集調達の課題にある29のチームが人種差別に関する問題の統計分析を実施した興味深いデータ分析実験です。
2017年初頭に、US-ACMは透明性とアカウンタビリティを達成するために達成すべき7つの特性アルゴリズムを発表しました。
- 認識
- アクセスと救済
- 説明責任
- 説明
- データ
- 監査能力、検証
- テスト
この記事は、認識と最も密接に関連しています。
さらに、IEEEコンピュータ協会は2017年にもこの分野の標準を定義するためのプロジェクトを開始し、2018年2月に少なくとも2つの新しい会議が開催されました。
私の同僚たちと私は、アルゴリズムに関する公平な尺度(http://fairness-measures.org/)のリソースを持つウェブサイトにも取り組んでいますが、 アルゴリズムの、特に機械学習に関する取り組みが他にあります。
バイアスのかからないどんな試みもすでに私たち自身の文化バイアスおよび認知バイアスによって偏っているかもしれないので、最初のステップはバイアスを知ることです。
Webデザイナーや開発者がバイアスの存在を知っていれば、対処でき、修正することもできます。
さもなければ、私たちの未来は、多様性、目新しさ、そして意外なことさえも私たちを救うことができない偏った認識に基づいた架空の世界になるかもしれません。
Acknowledgments
割愛
References
割愛
Author
Ricardo Baeza-Yates (rbaeza@acm.org) is Chief Technology Officer of NTENT, a search technology company based in Carlsbad, CA, USA, and Director of Computer Science Programs at Northeastern University, Silicon Valley campus, San Jose, CA, USA.