はじめに


「達人に学ぶDB設計」、「SQLアンチパターン
」を読んだのでDB設計をする流れとその過程でのチェックポイントをまとめてみました。
今回は本に載っているものの中でも特に重要そうな部分に絞ってみました。
さらに詳しいことを知りたい方は本を購入してみてください。個人的には達人に学ぶDB設計徹底指南書のほうがおすすめです。こちらだけあれば十分だと思います。
DB設計には大きく分けて論理設計と物理設計の二つがありますが、今回はアプリケーション開発でメインとなる論理設計の部分に焦点をあてて説明をします。
一番最後にチェックポイントだけをまとめた章を用意したので、チェックポイントだけ知りたい方は最後だけ見ていただければと思います。
DB論理設計の流れ
DB論理設計は以下のようなステップで進めていきます。
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
以下では各ステップごとに章を分けて説明をします。
ステップ1: エンティティの抽出
エンティティは日本語では実体と訳し、ある共通項を持ったデータの集合体のことをいいます。
エンティティは物理的実体を含んでいなくてもいいです。
このステップでは、まずはシステムにどのようなエンティティ(=データ)が必要なのかを洗い出します。いわゆる「要件定義」にあたるフェーズです。
例
- (物理的なもの) 顧客、社員、店舗、車、など
- (概念的なもの) 税、売り上げ、注文履歴、など
チェックポイント
- 洗い出したエンティティは開発するシステムの要件を満たせるか
ステップ2: エンティティの定義
このステップでは各エンティティがどのようなデータを保持するかを定義します。
DBにおいてエンティティはテーブルという単位で表現されます。
つまり、エンティティの定義とはテーブルの定義を行うことと同意です。
特に大事なのは以下の二点です。
- キー(特定のデータを取り出すための列の組み合わせのこと)をなににするか
- どのような属性(列)を持たせるか
例
テーブルは以下のような形で表現されます。(青枠、青線は説明の補助のためのものです。)
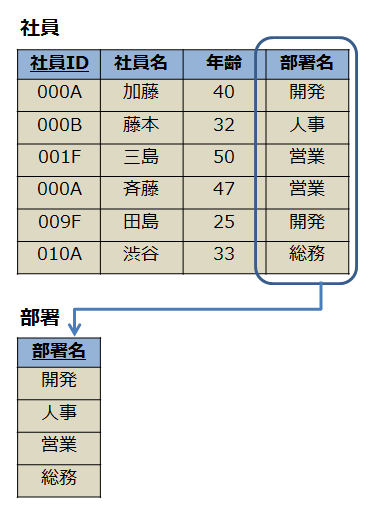
- 下線のある列は主キー(プライマリーキー)を表す
- 主キーとはキーの種類の一つで、テーブルにおいて必ず一つ存在しなければいけないもの
- 二つのテーブルを紐づけている列を外部キーと呼ぶ
- 外部キーとはキーの種類の一つで、テーブルの間の列同士で設定するもの
- 例でいうと「社員」テーブルの「部署名」列が外部キーにあたる。
- 外部キーは人間の親子関係のようなもの。親が存在しなければ子は存在できない。親と子の関係は1:多の関係。例では、「部署」テーブルが親で、「社員」テーブルが子の関係になっている。(部署:社員は1:多の関係。部署テーブルに登録されていない部署名は社員テーブルでは存在できない。)
悪い例
以下のような例はテーブルとして適していない、いわゆるアンチパターンなものです。
単一参照テーブル
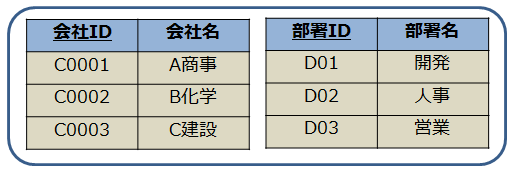
- テーブルの構造が同じだからという理由で複数のテーブルを一つにまとめてしまうパターン
- 例では、両者のテーブルは「ID」と「名前」という同じ構造を持っているが、これをひとまとめのテーブルにしてはいけない
ダブルミーニング
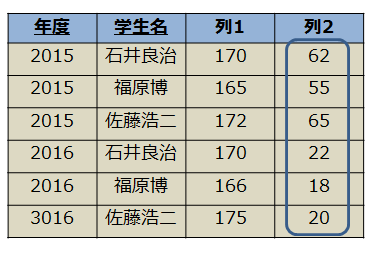
- 列の意味が途中から変わっているテーブルのこと
- 例では、列2が「体重」なのか「年齢」なのかわからなくなっている
チェックポイント
各項目ごとにチェックポイントを整理します。
テーブル
-
テーブル名は英語ならば複数形/複数名詞で書けるか
- そうでなければそのテーブルの定義に間違いがあるので再検討する必要がある
- テーブル名は同じドメイン(スキーマ)の範囲で重複していないか
- 日本語を使っていないか
-
最初はアルファベットになっているか
- 使うのであれば2009_uriageではなく、uriage_2009のようにする
- 複数のテーブルをまとめていないか
列
-
列名はハイフンは使っていないか
- ハイフンは標準SQLで定められていないので、使うのであればアンダーバーを利用するほうがよい
- 日本語を使っていないか
- 最初はアルファベットになっているか
-
全てのテーブルにidという名前を安易につかっていないか
- (主キーのところでも述べるが、)idという列が複数のテーブルで存在するとテーブルを結合するSQLなどを作成するときに混乱のもとになるので避ける
- NOT NULL 制約はなるべくつけているか
- 列の意味は統一されているか
キー全般について
-
値の変わる列を主キーや外部キーに利用していないか
- 例えば「山田」という苗字の場合、結婚などの理由で苗字が変わることがある。このような属性をキーにするのは適していない
-
キーとなる列にはコードやIDなど表記体系の定まった固定長文字列を利用しているか
- 可変長文字列(VARCHAR)の場合、例えば「山田太郎」という社員名をキーにしたとすると、「山田 太郎」のようにスペースが入ったデータも存在する可能性があるので、両者は不一致となって正しくデータを取得できなくなる
主キーについて
-
主キーは定義したか
- もし主キーとして適切な属性が存在しないようであれば代理キー(1,2,3,4など、それ自体に意味はないが一意性を保証するためのキー)を追加する
- 主キーはNULLを含んではいないか
-
主キーにidという名前を利用していないか
- 代理キーなどを主キーにする場合、idという名前をつけがちだが、複数のテーブルでidという名前があると混乱を招く原因になるので避けた方がよい。例えば、order_id のようにするほうがよい
-
主キーは重複してしまう可能性はないか
- 例えば「苗字」「名前」という属性を主キーにした場合、主キーは一意でなければいけないため、同姓同名の人はテーブルに入れることができなくなってしまう
外部キーについて
-
子に対して複数の親が存在していないか
- 存在している場合は設計が間違っている可能性があるので、親子関係などを再考してみる。(ポリモーフィックというアンチパターン)
- 中間テーブル(後述)を作成するなどして解決する
-
参照整合性制約をつけているか
- 制約をつけることで、親に存在しない値は子のテーブルで作成できなくなるので、間違ったデータを入れることを防ぐことができる
- レスポンスの遅さを気にして参照整合性制約をつけないケースが多いが、遅くなる原因にはならない
- もし制約をつけないと列を削除するときに子テーブルも正しく更新できるかなど毎回考慮しないといけなくなる
ステップ3: 正規化
正規化とはざっくりいうとテーブルを分解し、データの冗長性をなくすことです。分解の粒度によって呼び方が変わり第1正規形から第5正規形まで存在します。このステップではテーブルを分解する作業を行います。
一般的には第3正規形まで達成できれば十分なので、第3正規形まで説明をします。
正規化の中で重要なキーワードとして従属というものがあります。XによってYが一意に定まることを「YはXに従属する」と表現し、{X} -> {Y} と書きます。
以下では従属という言葉を用いて説明をします。
第1正規形
ひとつのセルに1つの値が存在しているテーブルのことをいいます。
正規化前
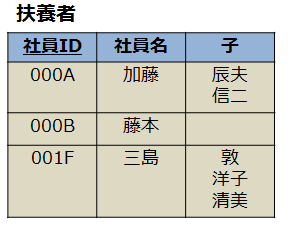
- 例では、カラムに複数の子の名前が入っている箇所があるため、第1正規形になっていないといえる
- カラムに複数データが入ると主キーによって一意にデータを識別できなくなってしまう(=列が主キーに従属でない)
正規化後
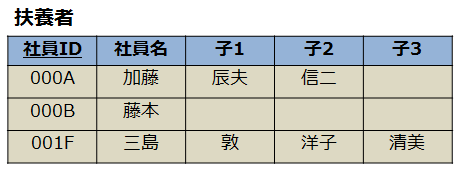
- 1カラム1要素なので、第1正規形の定義を満たしている
- 第1正規形であるが実はこのテーブルは列持ち(マルチカラムアトリビュート)と呼ばれるあまり好ましくない設計の例である
- 列持ちの場合、要素をさらに追加したいときにカラムを増やさないといけないためよくない設計とされている
チェックポイント
-
ひとつのセルに値は1つだけか
- ただし、基本的には列持ちのときのように第1正規化だけでは不十分なことが多いので、さらなる分解を検討する
-
カンマ区切りのフォーマットで格納していないか(一つのカラムに要素を詰め込んでしまうケース)
- 第1正規形ではあるが、カンマ区切りなどで複数のデータを一つのセルにいれることは好ましくない設計なので分解することを検討する
第2正規形
主キーに対して列が従属しているテーブルのことをいいます。
正規化前(第1正規形)
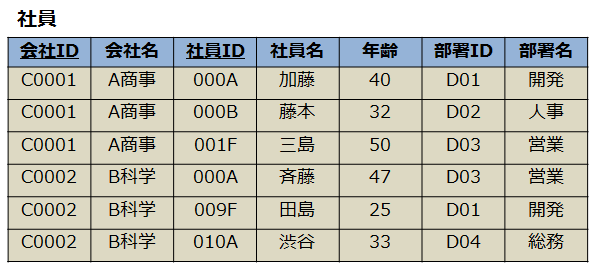
- 会社名は社員ID(主キー)がどのような値であっても会社ID(主キー)によってその値が一意に定まってしまう。このような、主キーの一部だけで列が従属してしまう状態を解消するのが第2正規化
- 社員がいない(社員情報がNULL)会社を登録したい場合、このテーブルに会社を登録できない
- {C0001, A商事}というレコードの他に{C0001, A商社}というレコードを間違えて入れてしまっても防ぐ手段がない
正規化後
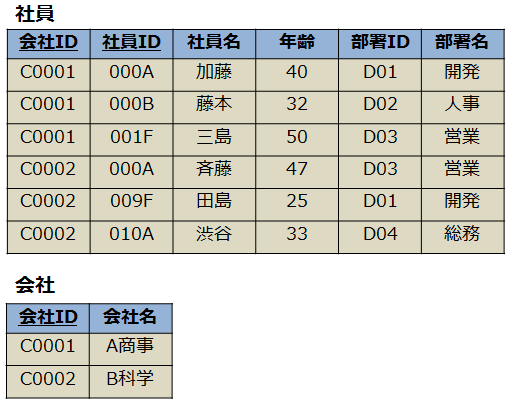
- 主キーの一部と従属だった列を新たなテーブルに切り離すことで第2正規形を作成することができる
チェックポイント
-
主キーの一部だけしか利用していないのに一意に定まる列が存在していないか
- 存在している場合、それは第1正規形になる。主キーの一部と従属している列がある場合、例で説明したデメリットが存在しているため、その列を新たなテーブルとして分解する必要性がある
第3正規形
主キーに対して全ての属性が従属であり、かつ推移的関数従属(後述)も存在していないテーブルのことです。
正規化前(再掲: 第2正規形)
- 主キーに対して全ての属性が従属である
- しかし、{部署ID}は主キー(会社IDと社員IDの組み合わせ)に対して従属であるが、{部署ID} -> {部署名}も従属である。つまり、主キー -> {部署ID} -> {部署名}という関係が成立している。このように、テーブル内部に存在する段階的な従属関係を推移的関数従属と呼び、これを解消するのが第3正規化である
正規化後
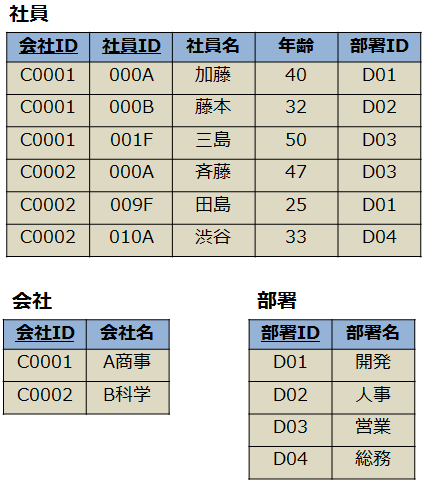
チェックポイント
-
主キー以外の列同士で従属する列は存在していないか
- 例でいうと「部署ID」と「部署名」は従属関係にある。このような列の組み合わせが主キー以外で見つかった場合、推移的関数従属が存在する可能性が高い。推移的関数従属が存在していればテーブルを分解する必要がある
ステップ4: ER図の作成
ER図はEntity-Relationship Diagramの略で、エンティティ(=テーブル)同士の関係を表現する図のことをいいます。
このステップでは上記のステップで作成されたテーブル同士の関係を見抜き紐づける作業を行います。
ER図の作成方法としては、主キーに着目し、他のテーブルの列にそのキーが含まれているかをチェックします。存在している場合、テーブル間に関係があるので線で結びます。
例
正規化の時に例とした使用したテーブルをER図にすると以下のように表現できると思います。
以下のER図をもとに簡単にER図の見方について説明します。
今回は見やすさの観点からER図の中でもIE表記法を採用しています。(ER図の他の表記方法については今回説明を省きます。)
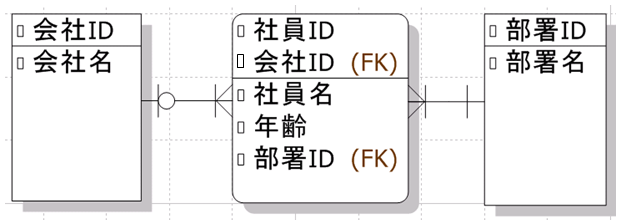
- 列名の左にある小さい四角はNOT NULLを表す
- テーブルが線で上下に分割されている場合、上は主キーを表す
- (FK)は外部キーを表す
- 「会社:社員」は「0以上:多」、「社員:部署」は「多:1以上」を表す
- 角の丸いテーブルは他のテーブルに依存していることを表す
- 社員テーブルのレコードは会社テーブルや部署テーブルに存在する値に依存するため、社員テーブルは丸い角で表現される
- 親子関係でいう子にあたるテーブル
問題のあるER図の例
作成したテーブル同士の関係を結んだ時にこのような関係性が見つかった場合は設計を見直したほうがいいという例を紹介します。
デメリットを理解した上で以下で紹介する関係性をあえて採用するケースもあると思いますが、基本的には採用せずに他の表現方法がないか考えるべきという例です。
1:1の関係
1:1とはつまり主キーが一致しているということです。普通に正規化していればこのような関係は存在しません。1:1の場合はテーブルを結合するのが普通です。
多:多の関係
システムの要件に従ってテーブルを作成すると多:多の関係のテーブルが作成される時があります。しかし、細かい説明は省きますが、両テーブルを結合した情報を得ることができないので好ましくない設計です。以下が多:多の例です。
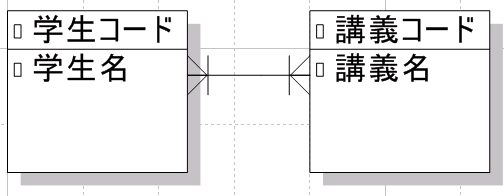
- 大学の授業を想定した場合、学生は複数の講義をとるため、学生1に対して講義は多の関係。一方で講義には複数の学生が出席するため講義1に対して学生多。その結果、「学生:講義」は「多:多」の関係になる
子に対して親が複数ある関係
親が二つあって、子のテーブルにある外部キーがどちらかの親に属しているというようなパターンがこれにあたります。ポリモーフィック関連などと呼ばれるアンチパターンの一種です。子は複数の親を持ちません。複数の親を持つことのデメリットは以下です。
- 参照制約がつかえなくなる
- 結合すると片方の親はNULLになる
改善例
「多:多」や「子に対して親が複数存在する」場合は中間テーブルというテーブルを作成することが問題解決に有効な手段となります。
ここでは中間テーブルについて説明をします。
中間テーブルの作成
**中間テーブルとは、多:多の関係を解消するために、それらのテーブル間に作成する新たなテーブルのことを言います。**中間テーブルは関連実体などとも呼ばれます。
中間テーブルは多:多の問題を解決するために作られたテーブルであるため、そのエンティティは要件定義で出てくるようなエンティティとは違い、あくまで人工的に作られたものとなります。

- 例では、受講という中間テーブルを作成して学生と講義に存在する多:多の関係を解消している
チェックポイント
- あるテーブルの主キーが他のテーブルに列として存在している場合、それらのテーブルは関連性が作成されているか(線で結ばれているか)
-
1:1という関係のテーブルが存在しないか
- 存在していたら結合する
-
多:多という関係のテーブルが存在しないか
- なっているなら中間テーブルを作成し、多:多にならないようにする
-
子に対して親が複数存在していないか
- 中間テーブルを作成することで解決できるか検討する
- 本来の関連が逆になっている可能性があるので参照を逆にしてみる
チェックリスト
今回の各ステップにおけるチェックポイントを以下にまとめました。
DB論理設計をするときはこのリストを参考にして設計に問題がないか確認をしてみるといいかもしれません。
ステップ1: エンティティの抽出
- 洗い出したエンティティは開発するシステムの要件を満たせるか
ステップ2: エンティティの定義
- テーブル名は英語ならば複数形/複数名詞で書けるか
- テーブル名は同じドメイン(スキーマ)の範囲で重複していないか
- 日本語を使っていないか
- 最初はアルファベットになっているか
- 複数のテーブルをまとめていないか
- 列名はハイフンは使っていないか
- 日本語を使っていないか
- 最初はアルファベットになっているか
- 全てのテーブルにidという名前を安易につかっていないか
- NOT NULL 制約はなるべくつけているか
- 列の意味は統一されているか
- 値の変わる列を主キーや外部キーに利用していないか
- キーとなる列にはコードやIDなど表記体系の定まった固定長文字列を利用しているか
- 主キーは定義したか
- 主キーはNULLを含んではいないか
- 主キーにidという名前を利用していないか
- 主キーは重複してしまう可能性はないか
- 子に対して複数の親が存在していないか
- 参照整合性制約をつけているか
ステップ3: 正規化
- ひとつのセルに値は1つだけか
- カンマ区切りのフォーマットで格納していないか(一つのカラムに要素を詰め込んでしまうケース)
- 主キーの一部だけしか利用していないのに一意に定まる列が存在していないか
- 主キー以外の列同士で従属する列は存在していないか
ステップ4: ER図の作成
- あるテーブルの主キーが他のテーブルに列として存在している場合、それらのテーブルは関連性が作成されているか(線で結ばれているか)
- 1:1という関係のテーブルが存在しないか
- 多:多という関係のテーブルが存在しないか
- 子に対して親が複数存在していないか
さいごに
ツイッター(@nishina555)やってます。フォローしてもらえるとうれしいです!