まとめ
明日は選挙なので、ここに載っている政党ごとの意見をいろいろ可視化してみました。
政治的な意図は特にないので、とりあえず明日選挙行けよな!!
PCA
とりあえずPCAが気になる。
・ソースコード
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import seaborn as sns
from scipy.stats import pearsonr
from sklearn.decomposition import PCA
plt.rcParams['font.family'] = 'IPAexGothic'
df = pd.read_csv("input.tsv", sep="\t", index_col=0)
df = df.replace({
"賛成": 2,
"やや賛成": 1,
"選択なし": 0, # 若干ニュアンスが違うが、0扱い。
"中立": 0,
"やや反対": -1,
"反対": -2
})
df = df.transpose()
# do pca
pca = PCA(n_components=2)
pca.fit(df.values.T)
explained_variance_ratio = [100.0 * v for v in pca.explained_variance_ratio_]
pc_coord = pca.fit_transform(df.values.T)
arrows = []
for i, feature in enumerate(df.index):
feature_dict = {}
feature_dict['name'] = feature
feature_dict['x'] = pearsonr(df.values[i, :], pc_coord[:, 0])[0]
feature_dict['y'] = pearsonr(df.values[i, :], pc_coord[:, 1])[0]
feature_dict['len'] = np.sqrt(
feature_dict['x']**2 + feature_dict['y']**2)
arrows.append(feature_dict)
plt.scatter(x=pc_coord[:, 0], y=pc_coord[:, 1])
for x, y, text in zip(pc_coord[:, 0], pc_coord[:, 1], df.columns):
plt.text(x, y, text)
for arrow in arrows:
plt.arrow(0, 0, arrow["x"]*3, arrow["y"]*3, fc="red", ec="red", alpha=0.5)
plt.text(arrow["x"]*3, arrow["y"]*3, arrow["name"])
# plt.savefig("pca.png")
・結果
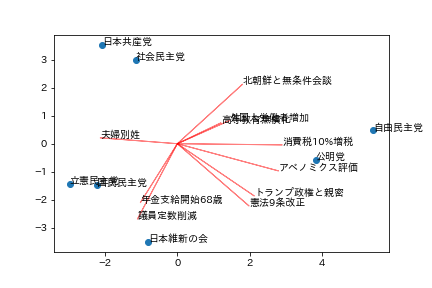
与党が固まっていること、野党は何パターンかある感じが掴み取れます。
clustermap
これだけ単純なデータだったら、ヒートマップですべてが見られるような気もする。
sns.clustermapでheatmap&可視化してみます。
sns.clustermap(df, cmap=sns.color_palette("coolwarm", 5))

アベノミクス、消費税10%、議員定数削減あたりが与野党で温度感が違うことがわかります。
おわり。