chiVeの活用方法シリーズ
- Part 1 「分散表現とは?chiVeとは?」
- Part 2 「chiVeでできること(単語ベクトルの性質)」
- Part 3 「chiVeでできること(単語ベクトルで文書分類)」(本記事)
- Part 4 「chiVeの追加学習」
はじめに
2022年4月末に、WAP NLP Tech Talk#5 にて、「単語分散表現 chiVeの活用方法」というタイトルでお話しをしました。
そのQiita版として、スライド の内容を補足しながら何回かに分けて紹介しています。
chiVe とは、日本語単語分散表現です。分散表現の基本事項や、chiVe の特長については、Part 1 で触れています。
さて、前回は単語のクラスタリングに触れました。今回は、文や文書1の分類に取り組みます。
クラスタリングと分類の違い
クラスタリング(教師なし)は、単にグループ化するだけのタスクです。グループの名前は分かりません。
分類(教師あり)は、予め決められたグループのどこに入るのかを推定するタスクです。
例えば「猫」「柚子」「カボス」「犬」「スダチ」という単語を2グループに分けたいとします。

クラスタリングでは、「Group1: 柚子、カボス、スダチ」「Group2: 猫、犬」と分けられます。
ただし、近いもの同士でグループ化しただけで、それぞれのグループが何を表しているか分かりません。Group1 が「食べ物」なのか「果物」なのか「柑橘」なのか分からないのです。
一方、分類では事前にグループ名(教師ラベル)が与えられています。
「猫(動物)」「犬(動物)」「柚子(果物)」「カボス(果物)」というデータを既に持っている状況で、「スダチ」のラベルが「動物」なのか「果物」なのかを推定します。
テキスト分類
分類タスクの中でも、ここではテキスト分類を扱います2。例えば、ニュース記事のカテゴリ推定や、SNS投稿の感情分類、単語の品詞推定、文書の言語推定など、テキストを扱う分類には様々な応用例があります。
分類タスクを解くには、テキストをベクトルに変換して、分類器に入力します。

ベクトル化
前回の記事により、単語ベクトルは chiVe で得られました。今回は、単語ベクトルを組み合わせて文ベクトルを作ってみます。

例えば「スダチを絞る。」という文は、Sudachi C単位で「スダチ」「を」「絞る」「。」という単語に分割できるので、それぞれの単語ベクトルを要素ごとに平均3すれば、文「スダチを絞る。」のベクトルが得られます4。平均ではなく最大値3を取る方法もあります。
分類器
今回は、分類器として SVM (support-vector machine) を使います。SVMは、分類の境界線を探す手法です。
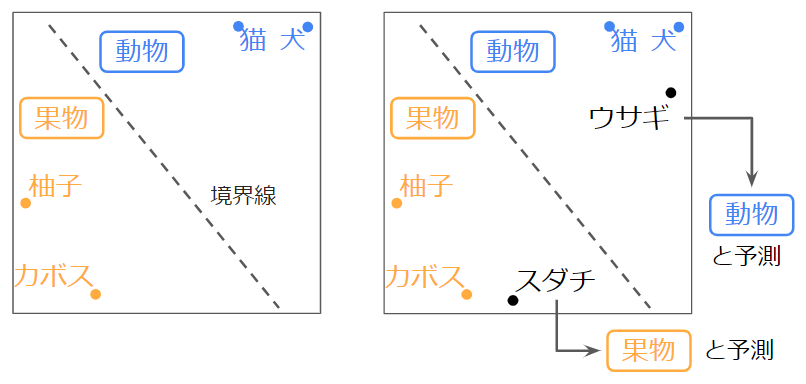
例えば、学習用データ「猫(動物)」「犬(動物)」「柚子(果物)」「カボス(果物)」があるとします。左図のように「果物」と「動物」を分ける境界線の位置を求めます。すると右図のようにラベルが未知のテスト用データ「スダチ」「ウサギ」に対して、それぞれのラベルが「果物」「動物」だと予測できます。
実験
使用するライブラリが無い場合は適宜インストールしてください。
インストールされているライブラリの確認
# インストールされているライブラリの一覧表示
$ pip freeze
インストールコマンド
$ pip install sudachipy sudachidict_core # Sudachi
$ pip install pandas # .tsvファイルを扱う
$ pip install numpy # ベクトルなどを扱う
$ pip install gensim # chiVeを使う際に必要
$ pip install scikit-learn # 分類などの機械学習ライブラリ
データセットの準備
データセットは、livedoor ニュースコーパス を使います。これは、ニュース記事とカテゴリが紐づいたデータセットです。8つのカテゴリ(dokujo-tsushin it-life-hack kaden-channel livedoor-homme movie-enter peachy smax sports-watch topic-news)があり、併せて 7,367記事があります。記事からカテゴリ(ラベル)を予測するタスクに取り組みます。
# ダウンロード
$ wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
# 圧縮されているので展開(解凍)
$ tar xzf ldcc-20140209.tar.gz
# text/ というディレクトリ(フォルダ)に保存される
$ ls text
# >>> CHANGES.txt dokujo-tsushin kaden-channel movie-enter smax topic-news
# README.txt it-life-hack livedoor-homme peachy sports-watch
$ ls text/dokujo-tsushin/ | head -n5
# >>> LICENSE.txt
# dokujo-tsushin-4778030.txt
# dokujo-tsushin-4778031.txt
# dokujo-tsushin-4782522.txt
# dokujo-tsushin-4788357.txt
各ディレクトリ中の記事ファイル(例えば text/dokujo-tsushin/dokujo-tsushin-4778030.txt )は、
- 1行目:記事のURL
- 2行目:記事の日付
- 3行目:記事のタイトル
- 4行目以降:記事の本文
となっています。ディレクトリにはライセンスファイルなども含まれており、そのままでは扱いにくいので、全ての記事を1つのファイルに変換します。
import csv
from pathlib import Path
titles_file = open('livedoor.tsv', 'w')
writer = csv.DictWriter(titles_file, ['label', 'filename', 'title', 'article'],
delimiter='\t')
writer.writeheader()
for file in Path('text').glob('*/*[!LICENSE].txt'):
label = file.parent.name
with open(file) as f:
lines = f.readlines()
writer.writerow({'label': label, 'filename': file.name,
'title': lines[2].rstrip(),
'article': ''.join(lines[3:])})
titles_file.close()
読み込んで確認してみましょう。
import pandas as pd
df = pd.read_csv('livedoor.tsv', sep='\t')
df
Google Colab で動かしている方は次のような表が確認できます。

この後の分類器で利用できるよう、ラベル名(label列)をラベルID(label_id 列)に変換します。
ラベルIDは、ラベル名のアルファベット順に 0, 1, ..., 7 とします。
# ラベル名のリスト
labels = sorted(set(df['label']))
labels
# >>> ['dokujo-tsushin', 'it-life-hack', 'kaden-channel', 'livedoor-homme',
# 'movie-enter', 'peachy', 'smax', 'sports-watch', 'topic-news']
# 新たに label_id 列を挿入
df.insert(1, 'label_id', [labels.index(x) for x in df['label']])
学習データ(パラメータ調整用)とテストデータ(性能の評価用)に分割します。今回は9割を学習データとします。
shuffled_df = df.sample(frac=1, random_state=0) # データをシャッフル
train_len = int(len(shuffled_df) * 0.9) # 9割が何個目かを確認
train_df = shuffled_df[:train_len].reset_index(drop=True) # 前半の9割を学習用に
test_df = shuffled_df[train_len:].reset_index(drop=True) # 後半の1割をテスト用に
train_df
train_dfの中身
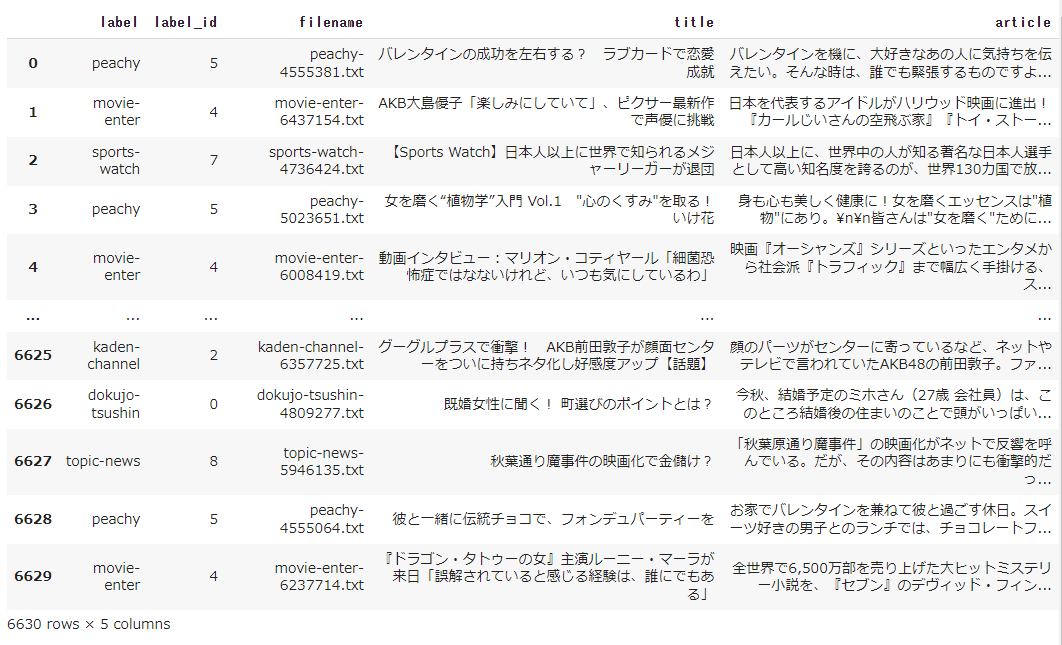
label_id列が追加され、行数が 6,630 (7,367 の約9割)行になっていますね。
test_df も同様のフォーマットで、737行のデータセットになっています。
chiVe を使ってテキストをベクトルに変換
いよいよベクトル化です。
chiVe の収録単語は正規化形ですので、まずは入力テキストを正規化形の単語列に変換するメソッドを作ります。
import sudachipy
import sudachidict_core
tokenizer = sudachipy.Dictionary().create()
# テキストを単語に分割するメソッド
def tokenize(sent: str) -> list[str]:
morphs = tokenizer.tokenize(sent.strip())
norms = [m.normalized_form() for m in morphs]
return norms
# 動作確認
tokenize('スダチ生産量の日本一は徳島県です。')
# >>> ['酢橘', '生産量', 'の', '日本一', 'は', '徳島県', 'です', '。']
chiVeを使って、テキストをベクトルに変換するメソッドを作ります。
chiVeモデルもここで読み込んでおきます。まだ chiVe をダウンロードできていない場合は、先に前回の記事を参照してください。
import gensim
import numpy as np
# ダウンロードしたchiVeを読み込み
chive = gensim.models.KeyedVectors.load('data/chive-1.2-mc90_gensim/chive-1.2-mc90.kv')
# テキストをベクトルに変換するメソッド
def text2vec(text: str, vectorizer=chive):
norms = tokenize(text)
word_vecs = np.array([vectorizer[n] for n in norms if n in vectorizer])
text_vec = np.average(word_vecs, axis=0)
return text_vec
# 動作確認
text2vec('スダチ生産量の日本一は徳島県です。')
# >>> array([-6.04522303e-02, 1.01010062e-01, 5.90633340e-02, -9.41304192e-02,
# 9.91320759e-02, -4.76069711e-02, 5.32414578e-02, 1.00305766e-01,
# 7.15337843e-02, -1.27613544e-01, 4.27431688e-02, 9.10347551e-02,
# (長いので中略)
# -3.49916052e-04, -9.88880172e-04, 1.10380435e-02, 6.19136691e-02],
# dtype=float32)
データセットをベクトルに変換します。
# train_df["article"] を1行ずつ読み込んでベクトル化
train_x = np.array([text2vec(article) for article in train_df["article"]])
# ラベルIDはベクトル化せずそのまま
train_y = np.array(train_df["label_id"])
# テストデータも同様
test_x = np.array([text2vec(article) for article in test_df["article"]])
test_y = np.array(test_df["label_id"])
分類器で学習
作ったベクトルを使ってSVM(※コード中の名前はSVC)を学習します。
SVM のハイパーパラメータ C や gamma は好きな数値を選べます5。今回は、C=[1, 10, 100, 1000] gamma=[1e-4, 5e-4, 1e-3] として、5交差検定とグリッドサーチでベストのパラメータを探索します。
グリッドサーチとは
ハイパーパラメータの全ての組み合わせを試して、一番良いものを選びます。 今回の例では、$C\in\{1,\ 10,\ 100,\ 1000\}$ と $\gamma\in\{0.0001,\ 0.0005,\ 0.001\}$ としていますから、そのすべての組み合わせ $(C,\ \gamma)\in$ $\{(1, 0.0001),$ $(1, 0.0005),$ $(1, 0.001),$ $(10, 0.0001),$ $(10, 0.0005),$ $(10, 0.001),$ $(100, 0.0001),$ $(100, 0.0005),$ $(100, 0.001),$ $(1000, 0.0001),$ $(1000, 0.0005),$ $(1000, 0.001)\}$ の12通りを試します。交差検定とは
ハイパーパラメータを探索するため、学習データを、(探索用の)学習データと検証データに分けます。今回の例では、4:1に分割します。
交差検定しない場合
この(探索用の)学習データで、上記グリッドサーチと組み合わせてハイパーパラメータが異なる12個の分類器を作り、この検証データで評価します。最も評価が高いハイパーパラメータをベストのパラメータとします。
交差検定する場合
さらに、検証データを変えて複数回試します。今回の例では検証データを5分の1としているので、5回試して評価結果を平均します。すなわち、上記のグリッドサーチと組み合わせて60個(12パラメータx5回)の分類器を作り、最も良いパラメータを探索します。

from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# SVMで学習・評価を行うメソッド
def classify(train_x, train_y, test_x, test_y):
#探索するパラメータ
param_grid = {
'svc__C': [1, 10, 100, 1000],
'svc__gamma': [1e-4, 5e-4, 1e-3],
}
# StarndardScaler()でベクトルの標準化してから、SVCに入力する分類器
clf = make_pipeline(StandardScaler(), SVC(random_state=0))
# グリッドサーチ(verbose=1にするとログ出力を減らせます)
search = GridSearchCV(clf, param_grid, verbose=3)
search.fit(train_x, train_y)
best_model = search.best_estimator_
# 検証データでベストだったモデルでテスト
predicted = best_model.predict(test_x)
# 正解率
accuracy = accuracy_score(test_y, predicted)
print('accuracy = {:.4f}'.format(accuracy))
実行してみましょう。60個の分類器を作るので少し時間がかかります。
classify(train_x, train_y, test_x, test_y)
# >>> Fitting 5 folds for each of 12 candidates, totalling 60 fits
# [CV 1/5] END .......svc__C=1, svc__gamma=0.0001;, score=0.826 total time= 6.3s
# [CV 2/5] END .......svc__C=1, svc__gamma=0.0001;, score=0.824 total time= 6.2s
# [CV 3/5] END .......svc__C=1, svc__gamma=0.0001;, score=0.796 total time= 6.2s
# (長いので中略)
# [CV 5/5] END .....svc__C=1000, svc__gamma=0.001;, score=0.908 total time= 2.5s
#
# accuracy = 0.9132
正解率(Accuracy)は 91.32% でした。上手く学習できてそうです。
まとめ
今回は、chiVe を使って文書分類を行いました。
ベクトル化は chiVe の平均、分類器は SVM、データセットは Livedoor ニュースコーパスを使いました。それぞれ他にも色々な手法がありますので、興味があれば調べてみてください。
次回は、chiVe の追加学習について紹介します。
-
今回は文も文書も単語列として扱うため、ここでお話しする内容はどちらに対しても適用できます。 ↩
-
「分類」は、テキスト分類の他にも様々なところで使われています。例えば画像分類などがあります。 ↩
-
単語分散表現の平均や最大値から文のベクトルを作る手法は、SWEM (Shen et al., ACL-2018) で紹介されています。 ↩ ↩2
-
ここで紹介している方法は、単語の順序を考慮できません。「犬が猫を追う。」も「猫が犬を追う。」も同じ文ベクトルになります。 ↩
-
パラメータ
Cやgammaによって、どのくらい学習データに合わせた境界を引くのかを決められます。なるべく学習データに沿うようにしたいわけですが、やりすぎると学習データに特化しすぎてテストデータで上手くいかないことがあります。詳しくはSVMの仕組みを検索してみてください。 ↩