音声合成のFlowtronを使ってJSUTの学習をした場合、結局上手く行きませんでしたが、学習時に詰まった事柄をいくつか書きます。
日本語の学習データで学習させることを考えます。
(JSUTのBASIC5000のfilelist)
Tacotron2,Mellotron,Flowtronの違い
Tacotron2は単一話者のみの音声合成。
Mellotron,Flowtronは複数話者の音声合成が可能。(もしくは同一話者の複数リズム、複数ピッチ)
Flowtronの方がTacotron2よりσ値調整でおおきなばらつきの音声合成が可能。
Flowtronの環境構築
下記をして、あと入ってないライブラリを適当に入れる。(librosa,Unidecodeとか)
git clone https://github.com/NVIDIA/flowtron.git
cd flowtron
git submodule update --init
cd tacotron2
git submodule update --init
JSUTのSJIS変換での不具合
オリジナル学習データをSJIS(cp932)で書いてたのでJSUTもcp932に変換する必要がありました。
JSUTのtranscript_utf8.txtをutf-8からSJISに変換して保存すると以下の文章のように一部文字化けします。
とはいえ、日常で「龐煖」とか使うことはないので自分は気にしませんでした。
同様に「禕」とか「剝」も文字化けします。
気にする場合は、utf-8のままファイルを読み書きすると良いと思います。
utf8
BASIC5000_3593:趙軍襲来時には、飛信隊で第三伍長となるが、野営中に突如として来襲した龐煖によって、殺害された。
cp932
BASIC5000_3593:趙軍襲来時には、飛信隊で第三伍長となるが、野営中に突如として来襲した?煖によって、殺害された。
flowtronのfilelistに変換
cp932に変換したファイルを読み込んでflowtronのfilelist形式に変換しました。
(ファイルパス|テキスト|speaker_ID)
また、ffmpegを使ってJSUTのサンプリングレートを22050,モノラルのwavを出力しました。
import os
import subprocess
filename = './transcript_utf8.txt'
filename2 = './t_filelist.txt'
os.mkdir('basic')
with open(filename, encoding='cp932') as f:
filepaths_and_text = [line.strip().split(':') for line in f]
with open(filename2, encoding='cp932', mode='w') as f:
for i in range(len(filepaths_and_text)):
f.write('basic/%s.wav|%s|0\n' % (filepaths_and_text[i][0], filepaths_and_text[i][1]))
subprocess.run('ffmpeg -y -i "./wav/%s.wav" -ar 22050 -ac 1 "./basic/%s.wav"' % (filepaths_and_text[i][0], filepaths_and_text[i][0]))
japanease_cleaners
以下の様な日本語をローマ字に変換する日本語cleanerをtext/cleaners.pyに追加しました。
自分の場合は、pykakasiを使用しました。
from pykakasi import kakasi
kakasi = kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
kakasi.setMode('E', 'a')
kakasi.setMode('s', True)
conv = kakasi.getConverter()
def japanease_cleaners(text):
text = conv.do(text)
text = lowercase(text)
text = collapse_whitespace(text)
return text
data_config['text_cleaners'] = ['japanease_cleaners']
g2pとは
書記素列(Graphemes)から音素列(Phonemes)へと変換すること。(grapheme to phoneme)
Tacotron2系では英語の場合、単語の発音などは後述の辞書機能で変換している。
自分の場合はpykakasiがこれに相当する。
日本語学習の場合、辞書変換はオフにする。
data.pyの下記の部分はp_arpabetの確率でdata/cmudict_dictionaryの内容に変換するという内容である。
#words = re.findall(r'\S*\{.*?\}\S*|\S+', text)
#text = ' '.join([get_arpabet(word, self.cmudict)
# if random.random() < self.p_arpabet else word
# for word in words])
3D TH R IY1 D IY2
例えば3Dと書かれていたら英語では"スリーディー"と発音しなければならないとかそんなところです。
基本的に日本語は英語ほど文字と発音がずれていないので(体育=>たいく:雰囲気=>ふいんき:は=>わ:などはあるが)、基本は気にしなかった。
また、辞書作成を本格的にやる気なら手順的にcleanerでローマ字に変換する前に変換するべきだろう。
ちなみにだが、pykakasiでは「1本」は「1 hon」に変換されるが、「一本」は「ippon」となるので自分は数字を漢数字に置換しました。
変換後の入力の形式
文字列は最終的には以下の様なindex値になる。ここで「半角スペース」が8、「カンマ」が3、「ドット」が4、「a」が75、「b」が76、…「m」が87、…「z」が100である。
このアサインは詳しくはtext/symbols.pyおよびtext/cmudict.pyにある。
text= "水をマレーシアから買わなくてはならないのです。"
text= tensor([[ 87, 83, 100, 95, 8, 97, 89, 8, 87, 75, 92, 79, 79, 93,
82, 83, 75, 8, 85, 75, 92, 75, 8, 85, 75, 97, 75, 8,
88, 75, 85, 95, 94, 79, 82, 75, 88, 75, 92, 75, 88, 75,
83, 88, 89, 78, 79, 93, 95, 4]], device='cuda:0')
lossがNanになってしまう
python train.py -c config.jsonで学習を開始したとき

こんな感じの文章が出てlossがNanになってしまう。
原因はpytorchのバージョンが新しいと発生するようである。pytorchのバージョンを1.0.0にする。
もしくは、flowtron.pyの33行目の.byteの代わりに.boolを使う。
#mask = (ids < lengths.unsqueeze(1)).byte()
mask = (ids < lengths.unsqueeze(1)).bool()
参考:
https://github.com/NVIDIA/flowtron/issues/12
学習データがJSUT時のCUDAメモリーエラー
JSUTのデータで学習したとき、学習途中でCUDAメモリーが確保できないとかで終了する。
実はこれはJSUTの文章が長すぎる場合に発生する。(または音声ファイルが10秒以上のせいかもしれない)。
JSUTをpykakasiで変換した際、一文のアルファベット最長は確か266とかだったが、これはflowtronモデルよりも長い。従って、学習データは変換後のアルファベット長180以上は除くようfilelistを修正する。
(多分、ギリギリは"n_text": 185)
import re
from kanjize import int2kanji
from pykakasi import kakasi
kakasi = kakasi()
kakasi.setMode('H', 'a')
kakasi.setMode('K', 'a')
kakasi.setMode('J', 'a')
kakasi.setMode('E', 'a')
kakasi.setMode('s', True)
conv = kakasi.getConverter()
filename = './t_filelist.txt'
filename2 = './t_filelist2.txt'
with open(filename, encoding='cp932') as f:
filepaths_and_text = [line.strip().split('|') for line in f]
regex = re.compile('\d+')
with open(filename2, encoding='cp932', mode='w') as f:
for i in range(len(filepaths_and_text)):
m = regex.findall(filepaths_and_text[i][1])
for j in range(len(m)):
filepaths_and_text[i][1] = re.sub(m[j], int2kanji(int(m[j])), filepaths_and_text[i][1], 1)
if len(conv.do(filepaths_and_text[i][1])) < 180:
f.write('%s|%s|0\n' % (filepaths_and_text[i][0], filepaths_and_text[i][1]))
CUDAメモリーエラー2
そもそもGPUのメモリが4GBの場合、JSUTの文章を減らしても同じようにエラーが出る。
(1050Tiだとダメだった)
GPUの性能不足でも学習させたい場合はcudnn.enabled = FalseにするとCPUで学習する。この場合、学習はかなり遅くなる。実際この速度で学習させるのは正直、現実的でない。
#torch.backends.cudnn.enabled = True
torch.backends.cudnn.enabled = False
一方、推論(音声合成)はinference.pyでcudnn.enabled = Falseしても出来ない。
コードの修正が必要だがよく分からない。
参考:https://github.com/NVIDIA/tacotron2/issues/242
事前学習
論文に書いてあることだがflowtronはLJSpeechデータセット(少数話者で大量データ(20時間,10時間))で学習した後、 LibriTTSデータセット(話者の数は123と膨大だが一人では平均25分しかない)で学習している。
いきなり、LibriTTSデータ(多数話者の少数データ)ではしていない。おそらく、LJSpeechデータ(単一話者)でテキストと発音の関係性を学んだあと、LibriTTSデータ(複数話者)で話者の特徴を学習するのだろう。
単にこの手順に従った方が学習が早くなるだけなのか、それとも最初からLibriTTSデータでやると学習がどこかでこけるのかは分からない。
自分で集めた日本語データでやる場合もこの手順から類推すると、オリジナルの少数データで始めるよりも、日本語の単一話者の大量データ(JSUTデータセットとか)で学習した後、自身の少数データを混ぜた複数話者データで学習すると良いのかもしれない。
n_flows=2から始めて失敗する
下記issuesにn_flows=1で始め、n_flows=2はn_flows=1の学習重みを使ってwarmstartを使って学習を開始するとある。Progressive Growing of GANsのように。
よく分かってないが、n_flowsはflowtronのモデルの層の深さの定義なのだろうか。
flowtronのn_flows=2でいきなりゼロから始めた場合、音声合成のattention layerが平らになってしまう。
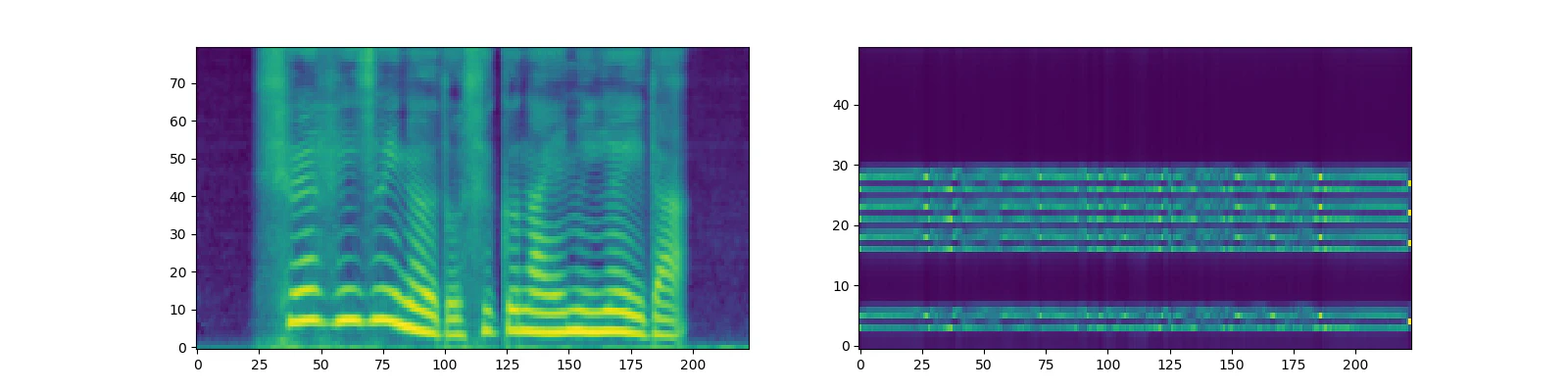
参考:https://github.com/NVIDIA/flowtron/issues/20
参考:https://github.com/NVIDIA/flowtron/issues/32
従って予想される学習手順は
1.(単一speaker, n_flows=1)をゼロから学習する。
2.(単一speaker, n_flows=2)を1.の重みを使って学習する。
3.(複数speaker, n_flows=2)を2.の重みを使って学習する。
のようになるだろうか。
Tacotron2の学習済みモデル(n_flows=1に相当)がある場合はその重みを使って2.から始めてよい。
学習途中からの開始時
この時、JSUT単体で学習した学習モデルをmodel_50000とすると
python train.py -c config.json -p train_config.ignore_layers=["speaker_embedding.weight"] train_config.checkpoint_path="outdir/model_50000"
とするとよい。
また、warmstart_checkpoint_pathで指定して始めても同じように学習途中の重みを読み込む効果はあったがepochはゼロからになる。(checkpoint_pathではepochは途中から)
学習速度
flowtronでn_flows=2でGPUは1070Tiのfp16で1分で135文くらい。CPUは1分で11文くらいである。(batch_size=1)
この事からcudnn.enabledはGPUが問題ないならTrueの方が良い。
論文著者は英語のLJSpeechデータセット(12442文)をV100を8基のGPUでepoch1000回やったとある。
(その後、LibriTTSデータセット(19934文)を500回。)
JSUTは5000文で、これを1000epoch学習するとすると1070Tiでも600時間かかる計算になる。
論文著者はLJSpeechの学習を12時間でやってるらしいのでGPU性能の差を実感します。
音声合成を試そうとするとエラー
音声合成のデモは例えば以下である。
python inference.py -c config.json -f outdir/model_225000 -w models/waveglow_256channels_universal_v5.pt -t "水をマレーシアから買わなくてはならないのです。" -i 0
しかし、これは配布されているflowtron_ljs.ptとかなら問題ないが、上記のflowtronの学習モデルを読もうとした場合**KeyError: 'state_dict'**が出る。
これを読み込めるようにするにはinference.pyのstate_dictを下記のようにする。
#state_dict = torch.load(flowtron_path, map_location='cpu')['state_dict']
state_dict = torch.load(flowtron_path, map_location='cpu')["model"].state_dict()
参考:https://github.com/NVIDIA/flowtron/issues/37
音声合成時も学習時のfilelistを読み込む
speaker_IDの辞書型リストを得るために推論時も学習時とおなじfilelistを読み込む必要があります。
学習時と関係ないからと異なるfilelistを読み込んでしまうとspeaker_IDの設定が上手く行かなくなる。
def create_speaker_lookup_table(self, audiopaths_and_text):
speaker_ids = np.sort(np.unique([x[2] for x in audiopaths_and_text]))
d = {int(speaker_ids[i]): i for i in range(len(speaker_ids))}
print("Number of speakers :", len(d))
return d
参考:https://github.com/NVIDIA/flowtron/issues/7
fp16での学習
半精度の学習は上記のようにすれば良いです。
train_config['fp16_run'] = True
apexインストール出来ていない場合は、下記でインストールします。
学習速度は上がりますが、1070Tiだと何倍も飛躍的に速くなるわけではありません。
cd apex
pip install -v --no-cache-dir ./
n_flows=1でも上手く行かなかった
結局、flowtronのn_flows=1で始めた場合もattention layerが上手く変換されなかった。
従って残念ながら自分はここで諦めました。
flowtronを学習するためのコツがあればだれか記事を書いてください。
まとめ
flowtron学習時に詰まったところ、気付いたところをまとめた。
残念ながらJSUTの学習の段階で挫折し、オリジナルデータの学習まで行きませんでした。
Flowtron Parallelが次に出るらしいです。
追記
その後、JSUTの学習自体は可能だったのでメモしておきます。
重要だったのは「flowtron_ljs.pt」の学習済みモデルの重みから開始する事でした。
LJSpeechデータセットは英文のデータセットであり、JSUTは日本語のデータセットですが、この英語データの学習重みを使用することで上手く学習できます。なおこの際、n_flows=2から開始して問題ありません。
上記でJSUTを学習するとloss=-1.2くらいでよい音声になり、学習データセットに含まれない文章でも読み上げ出来ました。
一方で、その次に200文くらいのオリジナルデータを用意してJSUTにまぜて学習を行いましたが、オリジナルデータの学習は上手く行きませんでした。学習データセットに含まれる文章ならたまに読み上げ可能でしたが、学習データセットに含まれない文章に関しては難しかったです。
LibriTTSデータセットは複数話者を含みますが、複数話者の学習にJSUTデータセットとオリジナルデータセットという異なるデータセットを混ぜて使用するのは良くないのかもしれません。
(というか自分のオリジナルデータセットの質の問題ですが)。
また、オリジナルデータセット単体の学習もJSUTの結果に比べ良くありませんでした。オリジナルデータをJSUTと同程度(5000文)用意すれば良くなるのかもしれません。