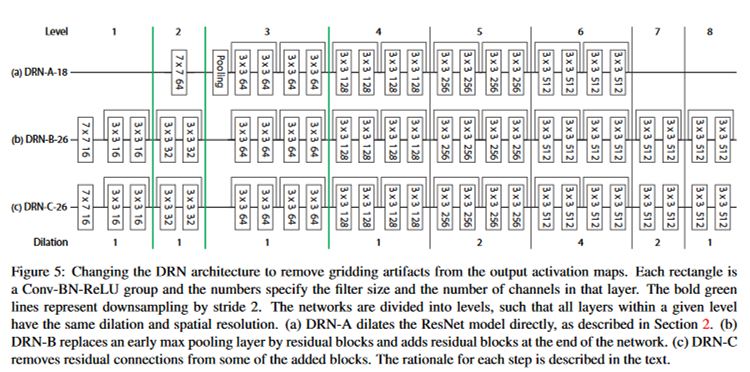
はじめに
Grad-CAMはモデルがどの場所を見て判別してるかというのを可視化をするのに良い手法です。
ただ、個人的な不満として画像サイズ(224,224)に対しGrad-CAMは(14,14)と解像度が低い事が挙げられます。
このようにGrad-CAMの解像度が低い理由はVGG16モデルにpoolingが計4回入ってるせいです。かといってpooling層を除けば画像の短距離の特徴量しか抽出できず長距離の特徴量を抽出できません。
dilated convolutionを使えば高解像度のGrad-CAMを得られないかなと思ったのでdilated convolutionを使うVGG16の等価モデルを作成して実験してみました。
結果としてはGrad-CAMの解像度は上がりましたが、元の高解像度にはなりませんでした。


左:通常のGrad-CAM、右:dilated convolutionを使ったGrad-CAM
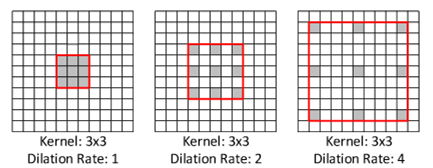
dilated convolutionとは
下記の図で示すように隙間の空いた歯抜けのフィルタを畳み込む手法です。
dilation_rateを大きくしていけばpoolingを使わずとも、小さなフィルターサイズで長距離の畳み込みができます。これを使えばpoolingを使わないため画像サイズが小さくなりません。
モデル
下記のKerasで書いたモデルを作成しました。このモデルを便宜上dilated_VGG16モデルと名付けます。
これはdilation_rateを調節することでサイズが(224,224)のまま長距離の畳み込みを計算できます。
このため、全結合前の解像度が(14,14)ではなく(224,224)の解像度を持ちます。
のちのGrad-CAMのため最終の畳み込み層の名前を'block5_conv3'としています。
VGG16モデルとdilated_VGG16モデルのパラメーター数が同じであることに注目してください。
inputs = Input(shape=(224,224,3))
x = Conv2D( 64, (3, 3), padding='same', activation='relu', dilation_rate=1)(inputs)
x = Conv2D( 64, (3, 3), padding='same', activation='relu', dilation_rate=1)(x)
x = Conv2D(128, (3, 3), padding='same', activation='relu', dilation_rate=2)(x)
x = Conv2D(128, (3, 3), padding='same', activation='relu', dilation_rate=2)(x)
x = Conv2D(256, (3, 3), padding='same', activation='relu', dilation_rate=4)(x)
x = Conv2D(256, (3, 3), padding='same', activation='relu', dilation_rate=4)(x)
x = Conv2D(256, (3, 3), padding='same', activation='relu', dilation_rate=4)(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', dilation_rate=8)(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', dilation_rate=8)(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', dilation_rate=8)(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', dilation_rate=16)(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', dilation_rate=16)(x)
x = Conv2D(512, (3, 3), padding='same', activation='relu', dilation_rate=16, name='block5_conv3')(x)
x = MaxPooling2D(pool_size=32)(x)
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dense(4096, activation='relu')(x)
y = Dense(1000, activation='softmax')(x)
model = Model(inputs=inputs, outputs=y)
dilated_VGG16
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
conv2d_2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
conv2d_3 (Conv2D) (None, 224, 224, 128) 73856
_________________________________________________________________
conv2d_4 (Conv2D) (None, 224, 224, 128) 147584
_________________________________________________________________
conv2d_5 (Conv2D) (None, 224, 224, 256) 295168
_________________________________________________________________
conv2d_6 (Conv2D) (None, 224, 224, 256) 590080
_________________________________________________________________
conv2d_7 (Conv2D) (None, 224, 224, 256) 590080
_________________________________________________________________
conv2d_8 (Conv2D) (None, 224, 224, 512) 1180160
_________________________________________________________________
conv2d_9 (Conv2D) (None, 224, 224, 512) 2359808
_________________________________________________________________
conv2d_10 (Conv2D) (None, 224, 224, 512) 2359808
_________________________________________________________________
conv2d_11 (Conv2D) (None, 224, 224, 512) 2359808
_________________________________________________________________
conv2d_12 (Conv2D) (None, 224, 224, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 224, 224, 512) 2359808
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 25088) 0
_________________________________________________________________
dense_1 (Dense) (None, 4096) 102764544
_________________________________________________________________
dense_2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_3 (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
参考:VGG16
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
VGG16重みの流用
dilated_VGG16のモデルの問題としてpoolingを使わないため画像サイズが大きく学習に非常に時間がかかることが挙げられます。深い層の畳み込み時間は画像比率からVGG16の16*16=256倍もかかるのでこのモデルで学習を行うのはおそらく現実的ではないように考えられます。
下記のように書いてVGG16の重みをdilated_VGG16に流用しました。
これはVGG16とdilated_VGG16のパラメータ数が等しいので可能です。
model1 = build_dilated_model()
model2 = VGG16(include_top=True, weights='imagenet')
model1.set_weights(model2.get_weights())
分類精度
VGG16重みを使ったdilated_VGG16でいつもの画像の分類予測を行いました。
分類精度はdilated_VGG16で非常に劣化してましたが、多少は有効のようです。

VGG16重みを使ったdilated_VGG16での予測
Model prediction:
Saint_Bernard (247) with probability 0.029
boxer (242) with probability 0.026
whippet (172) with probability 0.020
tiger_cat (282) with probability 0.019
vacuum (882) with probability 0.017
参考:VGG16での予測
Model prediction:
boxer (242) with probability 0.420
bull_mastiff (243) with probability 0.282
tiger_cat (282) with probability 0.053
tiger (292) with probability 0.050
Great_Dane (246) with probability 0.050
Grad-CAM結果
boxer予測の場合のGrad-CAM結果を書かせました。
通常のVGG16のGrad-CAMマップは(14,14)の解像度しかないですが、dilated_VGG16では(224,224)の解像度を持ちました。しかし、グリッド状パターンが出現し高解像度にはなりませんでした。
左:通常のGrad-CAM、右:dilated convolutionを使ったGrad-CAM
まとめ
dilated convolutionをやって高解像度のGrad-CAMを得られないかと目論んだが上手くは行かなかった。
検索するとdilated convolutionのグリッド状のパターンの解決策はあるようで下記の論文が見つかった。
https://www.cs.princeton.edu/~funk/drn.pdf
(中身は読んでいません…)