Extended Textual Conditioningの論文について内容を読んで考える。
Unetの各層に異なるpromptを与える
拡散モデルであるUnetに層によって異なるpromptを与えた場合、生成内容は層によって異なる。
middle部分に「緑のトカゲ」、down,up部分に「赤の立方体」と与えた場合とmiddle部分に「赤の立方体」、down,up部分に「緑のトカゲ」と与えた場合を比較する
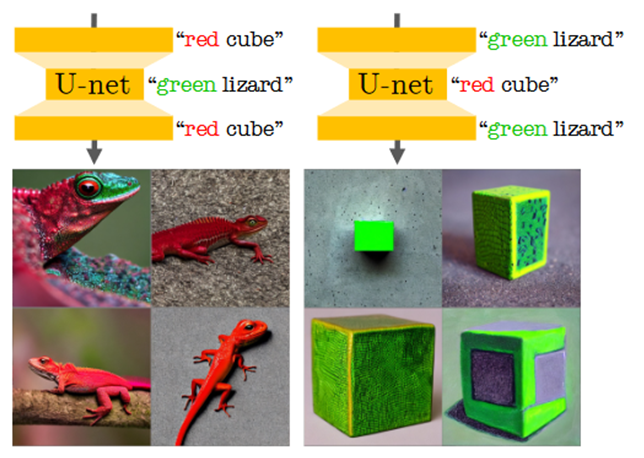
前者では「赤のトカゲ」が生成され、後者では「緑の立方体」が生成される。
つまりmiddle部分に与えた「オブジェクト」はよく反映され、「色」は反映されない。
down,up部分に与えた「オブジェクト」は反映されず、「色」は良く反映される。
「緑の立方体」を見るとトカゲの皮膚が反映されているように見えるのでいわゆるテクスチャもdown,up部分であることが類推される。
つまり担う部分は以下の様な感じである。styleは後述するがオブジェクトと色の中間である。
| middle部分 | down,up部分 |
|---|---|
| オブジェクト | 色 |
| 構図 | テクスチャ |
| (style) | (style) |
さて、Unetの各層に異なるpromptを与える実装はKohya S. 氏の実装がある。
解析
cross-attentionは合計16層あり、down 6層、middle 1層、up 9層である。
一般的なStableDiffusionでは512x512をVAEによって64x64に小さくして、Unetでは64x64を8x8に小さくして64x64に戻す。
解析では64x64と32x32はひとまとめにされ、解像度16のdown 2層、解像度8のdown(middle) 1層、解像度16のup 3層の計六層を一層ずつ増やしていきその傾向を見る。
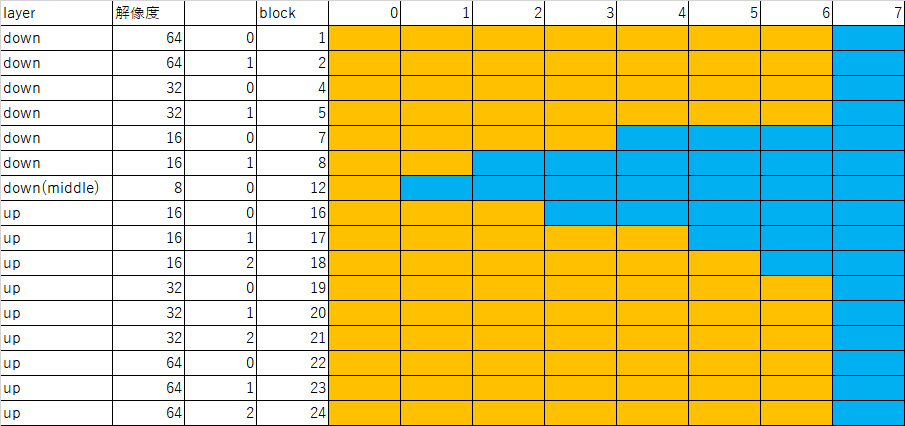

Color object, styleのpromptを与えた場合、これを一層ずつ混合していくと、まずObjectが車=>家に早期に変換され、次にStyleの印象派風=>グラフティ風が徐々に変換され、最後にColorが青=>赤に変換される。

Objectsはほぼ中央付近で、Styleは中間で影響層は幅広く、Colorはほぼ16x16の2層目以降である。ControlNetはdownとmiddle部分を操作するのでObjectsと同じようにmiddleの8x8とdownの16x16層が主要であると思われる。

Extended Textual Inversion
従来のTextual Inversionはある追加1Token(追加1単語)の重みを学習する。これは<new word>の追加embedding重みを一般的に学習する。
Custom Diffusionでは複数のtokenを追加できる。--modifier_token "<new1>+<new2>"では"+"で単語を分割し、 "<new1>"と"<new2>"を追加できMulti-Concept学習に向く。これらの追加tokenはsksなどのレアトークンの代替かと思われる。
一方、Textual Inversionの拡張機能(たとえばこれ)で--num_vectors_per_token=4のオプションがある場合がある。これは<new word>,<new word>1,<new word>2,<new word>3のように複数tokenを追加しTextual Inversionの表現力が増す。2番目以降の各追加tokenには暗黙的に自動で末尾に数値が付き区別されるが使用ユーザーは<new word>とnum_vectors_per_token以外は意識しない。これ自体は同時にMulti-Concept学習は出来ない。
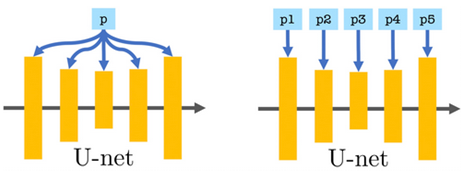
一方、Extended Textual Inversion(XTI) はUnetに与えるtokenを変える。
例えば従来のTIで学習promptが"A photograph of <teapot>"ならUnet各層に異なる追加tokenに基づくpromptを与える。例えば、cross-attentionは合計16層あるから"A photograph of <teapot 0>"、"A photograph of <teapot 1>"~"A photograph of <teapot 15>"とか。これによってUnet各層ごとに異なるembedding重みを学習する。
従来のnum_vectors_per_tokenは"A photograph of <teapot> <teapot>1 <teapot>2 <teapot>3"となるだけなのでXTIとは異なる。
評価
DreamBooth、CustomDiffusion、FineTuneなどは事前学習の重みを破壊する事がある(catastrophic forgetting)。一方、Textual InversionやLoRA、ControlNetはこれらの事前学習重みに一切手を付けることなく別の追加重みを学習する事が可能である。この為、事前学習が破壊されないので一般にTIやLoRAでは高い学習率を用いることができる。しかし、学習可能なパラメーターが本来のUnetよりも少ないのでDreamBoothと比べるとTIやLoRAは再現度で劣る(こともある)。
XTIはTIと同じく事前学習が破壊されなく、高い学習率を用いる。一方でパラメータ数はTIよりは大きく、それでいてLoRAよりは100倍以上少ない。
TIとDreamboothとの比較ではXTIは両者の中間に位置する。
ただし、オブジェクトの再現性とTextの編集性はトレードオフの間柄で過学習気味なら再現性が高く、編集性が低い。学習が少なめであれば再現性が低く、編集性が高い。個人的にだがこのトレードオフは学習するトークン強度と関係があり、学習しすぎるとトークンを何重も( )で囲った時の挙動に近いのではないかと思っている。これはCFGスケールが大きすぎる時の挙動(StepやSampling methodにも影響する)とも似るのかもしれない。
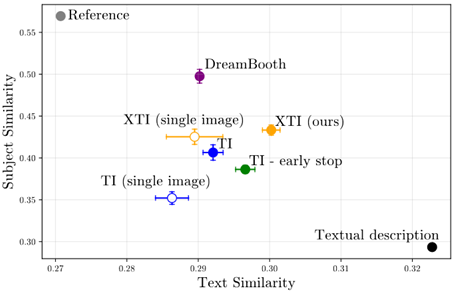
TIのnum_vectors_per_tokenも表現力を増すための修正であるが、XTIのUnet各層への適用の表現力増加とどれだけ違うのかについては論文中では明らかではない。Unet各層に違う重みを定義するという意味ではLoRAと近い部分があるのかもしれない。
KDE
再現性(表現力)を上げるために行ったことは前述の通りUnet各層に異なるtokenを使用し、パラメータを増やすことである。
一方、編集性を上げるために行ったことはまた別である。
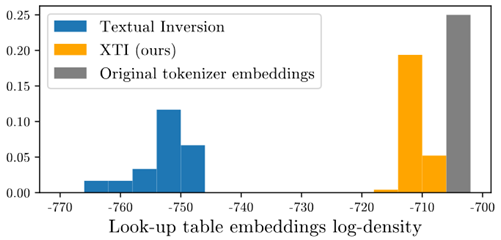
新たにkernel-based density estimation (KDE)という損失関数を追加しており、自分的にはこれはEmbedding層の重みをガウス分布を維持して学習することだと思われる。例えば以下の図でオリジナルembedding重みはガウス分布だがTIの学習重みは学習によって元のガウス分布からずれてしまう。XTIでは追加の損失関数によってなるべくガウス分布を維持している。
これによって高い編集性を保持しているのだと思われる。
参考:
Style Mixing
異なるXTIをUnetの異なる層に適用するとオブジェクトとスタイルを合成したような画像が得られる。
個人的にはStyleGANのstyle mixingと似てるように感じられる。適用範囲を変えることもできる。

個人的な疑問
query Qとkey Kで適用されるtokenはXTIでも同じだが、もしLoRAを目指すならQとKでも別tokenを適用するようにしなければいけないのではと思った。
まとめ
XTIについて読んでみた。TIよりは表現力性能は上だが、num_vectors_per_token使用より表現力が上がるのか、LoRAとの性能差については不明だった。
勝手な想像であるが表現力は多分LoRA以下なのではないかと思われる。
また実装コードが(23/03/20時点で)なく、どのように実装すればよいのか不明である。