この記事は下記の記事などを参考にしています。
パラメータ一覧
- Model Weights
- Optimizer States
- Gradients
- Forward Activations
1. Model Weights
モデルの重み。一般にモデルを読み込んだ時点で消費されるメモリ。
FP32ではパラメータ当たり4byteで、FP16ならパラメータ当たり2byte。
Mixed PrecisionならFP32の内、置き換え可能なところはFP16になる。
2. Optimizer States
Optimizerの保持する過去勾配。Optimizerの種類と学習モデルの大きさに依存。
Optimizerの種類で32bitAdamWはパラメータ数×64bit、8bitAdamWはパラメータ数×16bit必要である。
一方で、読み込みモデルに対して学習モデルを小さくする事でもこのパラメータは減らせれる。
ファインチューニングでは読み込みモデル=学習モデルだが、LoRA(差分パスのみ)、転移学習(出力層のみ学習)、CustomDiffusion(CrossAttentionのK,V重みのみ)、TI(TextEncoderのEmbeddingテーブルのみ)ではそれぞれ学習パラメータは読み込みモデルに対して小さい。
また、一時的に低減する手法にPaged Memoryがある。
3. Gradients
勾配。読み込みモデル×4byte(32bit)必要。
Mixed Precisionではこれを削ることは出来ず、読み込みモデル×4byte(32bit)必要なまま。
SDだとfull_bf16のオプションだと勾配も16bitに削ることが出来るらしい。

他、これを削る手法としては
Gradient Checkpointing、flash attentionのRecomputation、QLoRAの4bit Quantizationなどがある。
また、学習モデルを小さくするのもいくらか効果があると思われる。
4. Forward Activations
推論計算時に消費されるメモリ。推論時の使用メモリからモデル重みを引いたもの。
主にbatch_size、LLMの場合はシーケンス長(入力文長さ)、SDの場合は出力解像度に依存するものと思われる。
これを削減する手法にbatch_size、出力解像度を減らす、Gradient Accumulation、flash attention、Mixed Precision Trainingなどがある。
手法一覧
・ Gradient Accumulation
・ Gradient Checkpointing
・ Mixed Precision Training
・ 4bit Quantization(QLoRA)
・ Optimizer 8-bit Quantization(8bit_adam)
・ 小さな学習対象(LoRA, TI等)
・ Paged Memory
・ flash attention, xformers_memory_efficient_attention, PyTorch2.0(SDPA)
・ 差分モデルの特異値分解
・ grads_to_none
Gradient Accumulation
例えばBatch_size=2の場合、
- 重み$W_0$で入力$A,B$に対して勾配$\nabla W_{AB}=\frac{\nabla W_A + \nabla W_B}{2}$を得る。
- 重み$W_0+\eta \nabla W_{AB}$で入力$C, D$に対して勾配$\nabla W_{CD}=\frac{\nabla W_C + \nabla W_D}{2}$を得る。
一方、Batch_size=1の場合、
- 重み$W_0$で入力$A$に対して勾配$\nabla W_{A}$を得る。
- 重み$W_0+\eta \nabla W_{A}$で入力$B$に対して勾配$\nabla W_{B}'$を得る。
- 重み$W_0+\eta (\nabla W_{A}+\nabla W_B')$で入力$C$に対して勾配$\nabla W_{C}'$を得る。
- 重み$W_0+\eta (\nabla W_{A}+\nabla W_B'+\nabla W_C')$で入力$D$に対して勾配$\nabla W_{D}'$を得る。
となり、$\nabla W_{B}$と$\nabla W_{B}'$が等しくない。
ここで、Batch_size=1、gradient_accumulation_steps=2の場合、
- 重み$W_0$で入力$A$に対して勾配$\nabla W_{A}$を得る。
- 重み$W_0$で入力$B$に対して勾配$\nabla W_{B}$を得る。
- 重み$W_0+\eta (\frac{\nabla W_{A}+\nabla W_B}{2})$で入力$C$に対して勾配$\nabla W_{C}$を得る。
- 重み$W_0+\eta (\frac{\nabla W_{A}+\nabla W_B}{2})$で入力$D$に対して勾配$\nabla W_{D}$を得る。
となりBatch_size=2の処理と等しくなる。
Forward Activationsを節約する反面、中間勾配を余計に保持しないといけないので、削減できるかは場合による。
Batch_size=2とBatch_size=1,gradient_accumulation_steps=2なら前者が小さく、Batch_size=16とBatch_size=1,gradient_accumulation_steps=16なら後者が小さいと思われる。
主に、Batch_size文脈しか出てこないので、画像サイズに対して分割できるかは不明。
SDXLでは画像のクロップ位置情報を持つらしいので、Gradient Accumulationとで上半身と下半身を分けて解像度の小さい画像で学習できるかもしれないが結局、余分な中間勾配が必要なため却って2分割ではメモリ削減できないのではと思われる。
Gradient Checkpointing
これを説明するために例えを考えてみる。
ある長距離走に100か所の休憩地点があるとする。
走者は休憩地点で体温を測ることが出来、その値を持ってるノートにメモとして残せる。ゴールで出迎えてくれた人が男性ならゴールした時の体温を40℃、ゴールで出迎えてくれた人が女性ならゴールした時の体温を36℃になるようにスタートから走りたい。
そのためには一度ゴールした後に逆走し、メモした休憩地点の体温とゴールであった人の性別(以降は一個先の休憩地点の目標体温)から各休憩地点の目標体温を計算する。
このような事を繰り返していると走者の体はこれに慣れていき、不思議なことに体温を36℃でゴールした時、女性が出迎えてくれるようになった。
この時、走者のノートの容量に制限がなければ下記の様な図になる。休憩点が100か所なら100個のメモを残す。ゴール地点が最大でそこから逆走する段階で不要になったメモは消してよい。
Graph 1. Vanilla backprop

一方、走者のノートが1個しか値を保持できない場合、
ゴールの目標体温は決定できるが、そのひとつ前の休憩地点の目標体温を得るには再度スタートから走りなおさないといけない。何度もスタートから走りなおす事でノートの容量が小さくても計算は出来る。
Graph 2. Memory poor backprop

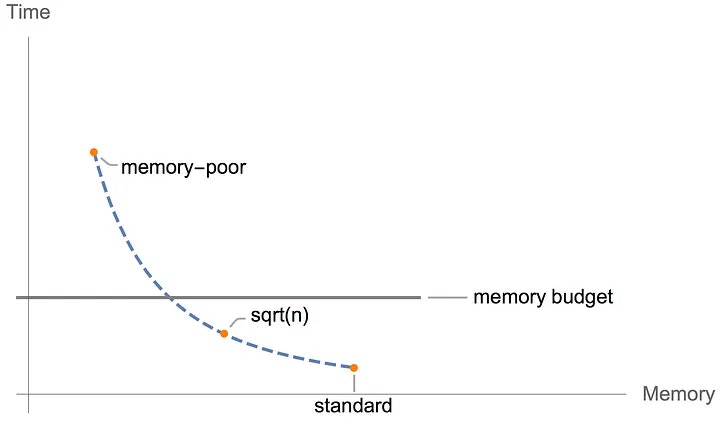
Gradient Checkpointingは残すメモの数を$\sqrt{n}$のオーダーにする。
100か所の休憩地点なら10か所のメモを残す。こうする事でメモを残した休憩地点から走りなおせばよい。
下記では4か所中2か所にメモを残している。
Graph 3. Checkpointed backprop

これはメモリと実行時間のトレードオフで勾配のGPUメモリの使用量が減る反面実行時間が増加する。
例えばモデルが4層で必要step、メモの数は
Vanilla backprop:必要step 4+1+0+1+0+1+0+1=8 ~$O(n)$:メモの数 4~$O(n)$
Memory poor backprop:必要step 4+1+3+1+2+1+1+1=14~$O(n^2)$:メモの数 1~$O(1)$
Checkpointed backprop:必要step 4+1+1+1+0+1+1+1=10~$O(n)$:メモの数 2~$O(\sqrt{n})$
例えばモデルが100層で必要step、メモの数は
Vanilla backprop:必要step 200:メモの数 100
Memory poor backprop:必要step 100+5050=5150:メモの数 1
Checkpointed backprop:必要step 287?290?:メモの数 14?20?
卵問題によればこの内、最適なメモを残す休憩地点は14,27,39,50,60,77,84,90,95,99,100になる。
95~99の場合、14,27,39,50,60,77,84,90,95を残して95からの休憩地点からの再スタート中に95から99のメモを残す。
27~39の場合、14と27を残して27からの休憩地点からの再スタート中に27から39のメモを残す。
この時、前半と後半のメモの合計の上限は14である。
こんな変てこな事をやってなく等間隔に保持するなら20であろう。(10,20,30,...90と91~99の1刻み)
いずれにしてもこの場合の実行時間には大差なくforward 2回(メモ保存地点のみ1回)、backward 1回である。
卵が3つならもっとメモの数は減るがforward 3回、backward 1回と実行時間が増えて行くだろう。100層ならメモの数は9個で済むらしい。
Mixed Precision Training
これはFP32とFP16の混合精度である。
これは一般にforward(の一部)を16bitにし、backwardは32bitのままである。
SDのfull_bf16ではforward、backward共に16bitになるらしい。
によればForward Activations(batch_sizeに依存する)が減らせている。
ファインチューニングの時、AMP(Auto Mixed Precision)によってForward Activationsが約3/4になっている。LoRAの時、AMPにForward Activationsが約2/3になっている。
一方、full_bf16では両方1/2になっている。
4bit Quantization(QLoRA)
個人的にはQLoRAはLLM 4bit量子化+LoRAでforward 4bit+16bit、backward 16bitなのが勾配の精度を失わなくて良いのではと思う。
最近LLMではAutoGPTQによって4bit量子化がなされている。
SDXLでも以下の様な記事はある。
Optimizer 8-bit Quantization(8bit_adam)
AdamWは二個の過去勾配を保持する必要があり、学習モデル×8byte(64bit)必要。
RMSprop、Adagrad、Adafactorは一個の過去勾配でよいので、学習モデル×4byte(32bit)必要。
8bitAdamWは保持するパラメータの精度が8bitでいいので学習モデル×2byte(16bit)必要。
8bitRMSprop、Adagrad、Adafactorなどは学習モデル×1byte(8bit)必要。
また、これは学習モデルの大きさに依存する。
このため学習モデルが十分小さい場合、8bitAdamWを採用しても削減量は小さい。
小さな学習対象(LoRA, TI等)
Optimizer Statesを削減できるほか、Gradient Checkpointingで説明したメモも減らせると思われる。
Paged Memory
Optimizer StateのGPUメモリを一時的にCPUメモリに退避させて最大メモリ消費を抑える。
ひとつはDeepSpeedなどがこれをやっており、もうひとつはPagedAdamW8bitなどのOptimizerを使う手法と思われる。しかし、LoRAなどにおいてそもそも学習対象が小さいので効果は小さいと思われる。
flash attention, xformers_memory_efficient_attention, PyTorch2.0(SDPA)
これらは原理的には同じような物として認識しているが正しいかは知らない。
flash attention2
flash attentionより30%ほど早い。
ハードウェア的な的要件があった。
差分モデルの特異値分解
学習元モデルとファインチューニングモデルからこの差分重みを特異値分解すれば差分重みをLoRA重みに変換できる。これを逆にすればLoRA重みを元モデルにマージしてファインチューニングモデルを作成できる。
しかし、一般に複数のLoRA重みを学習元モデルにマージしても干渉して上手く行かない。
Mix-of-ShowによるMulti-Concept Fusionなら複数ED-LoRAを一個のモデルに上手くマージできるので、LoRA学習を実質ファインチューニングと見なせるのではと思った。
grads_to_none
勾配がゼロの所をNoneに置換する。