StyleGANを少し触ってみて思ったことなどを書いてみます。
チュートリアルの実行
StyleGANを動かしてみます。簡単ですね。
git clone https://github.com/NVlabs/stylegan.git
cd stylegan
python pretrained_example.py
python generate_figures.py
モデルファイルのダウンロードが上手く行かない
チュートリアルプログラムを動かしたとき自分の環境だとモデルファイルのダウンロードが上手く行きませんでした。仕方ないのでローカルにpklファイルを保存して直接読み込ませるようにして実行しました。
fpath = './karras2019stylegan-ffhq-1024x1024.pkl'
with open(fpath, mode='rb') as f:
_G, _D, Gs = pickle.load(f)
潜在変数のパラメータ
潜在変数の値を一応確認数すると512次元の正規分布乱数のベクトルです。
# Pick latent vector.
rnd = np.random.RandomState(5)
latents = rnd.randn(1, Gs.input_shape[1])
print(latents)
print(latents.shape)
[[ 0.44122749 -0.33087015 2.43077119 -0.25209213 0.10960984 1.58248112
-0.9092324 -0.59163666 0.18760323 -0.32986996 -1.19276461 -0.20487651
-0.35882895 0.6034716 -1.66478853 -0.70017904 1.15139101 1.85733101
...
0.09123447 1.13441899]]
(1, 512)
じゃあ潜在変数の値が全部1だったらどうなる?もしくは潜在変数の値が全部0.1だったら?とやってみた結果がこちら。
latents = np.ones((1, Gs.input_shape[1])) # 全部1の時
latents = np.ones((1, Gs.input_shape[1])) * 0.1 # 全部0.1の時


うーん、全然変わってない…。細部変わっているように見えるのはrandomize_noise=Trueの影響です。
$latents$(潜在)で設定する潜在変数はベクトル方向だけで中央からの距離の情報は持ってないのかなと最初思ったのですが、単に入力値が大きすぎただけの模様。
latents = np.ones((1, Gs.input_shape[1])) * 0.0002 # 全部0.0002の時
latents = np.ones((1, Gs.input_shape[1])) * 0.0001 # 全部0.0001の時


今度は変化しましたね。
スタイルミキシング
二つの潜在変数があった場合、中間の潜在変数を取れば二つのイメージの合成を出来そうな気がしますが、一部のケースではそうではありません。中間の潜在変数の間に別の特徴量が出現する場合があるようです。
MNISTのAutoEncoderで二次元の潜在変数で端から端に移動するとき中間に別の数字が出現するイメージでしょうか。
そういう意味でいうと中間の潜在変数を取るのはイメージが近ければいいが全く離れているなら宜しくない。そこでスタイルミキシングが出てくるようです。
これは単純に潜在変数の中間を取るのではなく、浅い層に影響する潜在変数と深い層に影響する潜在変数と分けて混ぜる感じに思います。自分のイメージ的にはこんな感じ。
(注:違ってたら教えてください)
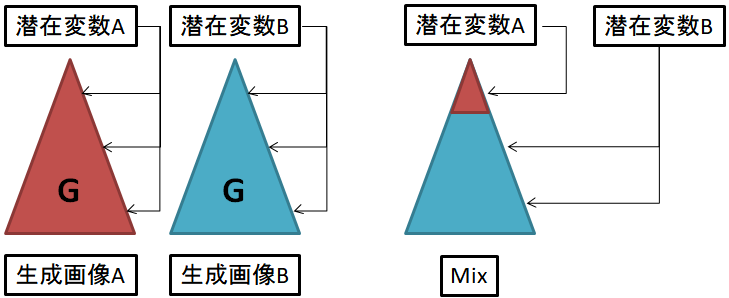
 :論文の図
:論文の図
style_ranges=[range(0,4)]*3+[range(4,8)]*2+[range(8,18)]
def draw_style_mixing_figure(png, Gs, w, h, src_seeds, dst_seeds, style_ranges):
src_dlatents = Gs.components.mapping.run(src_latents, None) # [seed, layer, component]
dst_dlatents = Gs.components.mapping.run(dst_latents, None) # [seed, layer, component]
for row, dst_image in enumerate(list(dst_images)):
row_dlatents = np.stack([dst_dlatents[row]] * len(src_seeds))
row_dlatents[:, style_ranges[row]] = src_dlatents[:, style_ranges[row]]
row_images = Gs.components.synthesis.run(row_dlatents, randomize_noise=False, **synthesis_kwargs)
欲しいもの
実画像=>潜在変数ベクトルに変換するエンコーダーはないのかなぁと思いました。
今はstyleGANの生成画像しか合成できませんよね。
エンコーダーがあれば任意の本物の二枚の実画像を合成したり、絵画の人物を写実化できるのに…。
エンコーダーといってもディスクリミネータDの最後の全結合層を潜在変数の出力として転移学習させれば良いのではと素人考えでは思いつきますが、多分そんなに簡単ではないんでしょう。