「Vision Transformer」(以下ViT)という非CNNモデルがCNNモデルを上回ったという記事を読んだ。
そもそもBERTとかSelf Attentionとかも一体何のことかよく分かっていないのに、突然そんな事を言われても全く付いていけてないので、理解を深めるためViTのtensorflowのコードを写経してみました。肝心の論文の中身はほとんど読んでいません。
そもそもSelf Attentionって何?
自分自身あまり分かってません。なので間違っているかもしれませんが自分の理解で説明します。
y = W \cdot x
一般的なCNNモデルは全結合だろうが、畳み込みであろうが重みを定義し、その重みを誤差逆伝播で学習します。学習時においてモデル重みはbatch毎に更新され、予測時は重みは定数として固定されます。
従って予測時において、様々な入力が存在するのに対して、その入力の積となる行列の値(モデル重み)は入力によらず予測時において常に定数です。
y = W(x) \cdot x
Self Attentionは要するに入力の積となる**行列の値(モデル重み)が入力によって変化する重みになっています。**これは入力に依存する重みを導出するレイヤーを求め、これに入力を掛ける事で実現します。
察しの良い人ならこれはCNNにおけるSENetの構造であることに気付きます。
(なおSelf AttentionのSelfとは重みを決める入力が自身と等しい事を示します。自身と異なる別の入力によって重みが決定される場合はSource-Target Attentionと呼ばれるようです)
一般的なSENetは特徴量抽出したチャンネルの強弱を決定付けます。
一方、以下の論文の図から推察するとViTにおけるSelf Attentionは空間的な特徴量の強弱を決定付けるように思いました。

Vision Transformer写経
tensorflowのコードを写経してみる。
https://github.com/emla2805/vision-transformer/blob/master/model.py
なるべく写す段階においてKeras風にしたつもりだが、構成上Kerasのみで書くのには無理がある。
Vision Transformer基礎
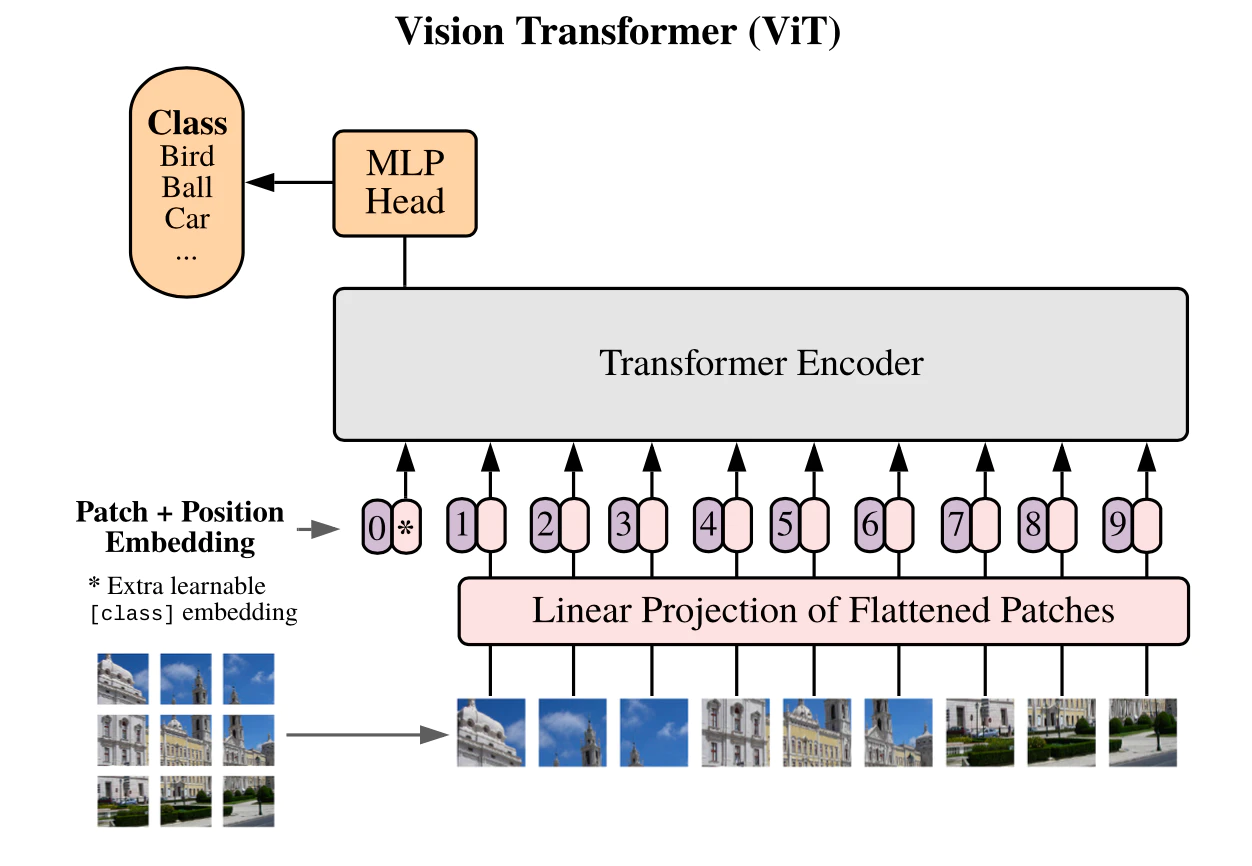
入力が$(batch,32,32,3)$の場合のVision Transformerの概要を示す。
space_to_depthを使うとpatch_size=4の場合、$(batch,32,32,3)=>(batch,8,8,48)$と$48$チャンネル分の$8×8$の画像に変換できる。
この$8×8$の画像をflattenする$(batch,8,8,48)=>(batch,64,48)$。
次に隠れ層の数$D=64$に増やす$(batch,64,48)=>(batch,64,64)$。
次にPatch + PositionのEmbeddingを追加する$(batch,64,64)=>(batch,65,64)$。
次にTransformerBlockを複数回追加する$(batch,65,64)=>(batch,65,64)$
次に出力の一部を取り出し、$(batch,65,64)=>(batch,64)$、
全結合により分類出力を作成する。$(batch,64)=>(batch,128)=>(batch,10)$
def make_ViT(img_size = 32, ch_size = 3, patch_size = 4,
batch_size = 400, num_layers = 4, d_model = 64,
num_heads = 4, mlp_dim = 128, num_classes = 10):
num_patches = (img_size // patch_size) ** 2
patch_dim = ch_size * patch_size ** 2
inputs = Input(shape=(32, 32, 3))
x = Rescaling(1./255)(inputs)
x = tf.nn.space_to_depth(x, patch_size)
x = K.reshape(x, (-1, num_patches, patch_dim))
x = Dense(d_model)(x)
x = Add_Embedding_Layer(num_patches, d_model, batch_size)(x)
for _ in range(num_layers):
x = TransformerBlock(x, d_model, num_heads, mlp_dim)
x = Dense(mlp_dim, activation=tfa.activations.gelu)(x[:, 0])
x = Dropout(0.1)(x)
y = Dense(num_classes, activation='softmax')(x)
return Model(inputs=inputs, outputs=y)
model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
__________________________________________________________________________________________________
rescaling (Rescaling) (None, 32, 32, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
tf_op_layer_SpaceToDepth (Tenso [(None, 8, 8, 48)] 0 rescaling[0][0]
__________________________________________________________________________________________________
tf_op_layer_Reshape (TensorFlow [(None, 64, 48)] 0 tf_op_layer_SpaceToDepth[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 64, 64) 3136 tf_op_layer_Reshape[0][0]
__________________________________________________________________________________________________
add__embedding__layer (Add_Embe (400, 65, 64) 4224 dense[0][0]
__________________________________________________________________________________________________
......
__________________________________________________________________________________________________
layer_normalization_7 (LayerNor (400, 65, 64) 128 add_7[0][0]
__________________________________________________________________________________________________
tf_op_layer_strided_slice (Tens [(400, 64)] 0 layer_normalization_7[0][0]
__________________________________________________________________________________________________
dense_25 (Dense) (400, 128) 8320 tf_op_layer_strided_slice[0][0]
__________________________________________________________________________________________________
dropout_8 (Dropout) (400, 128) 0 dense_25[0][0]
__________________________________________________________________________________________________
dense_26 (Dense) (400, 10) 1290 dense_25[0][0]
==================================================================================================
Total params: 150,858
Trainable params: 150,858
Non-trainable params: 0
__________________________________________________________________________________________________
Patch + PositionのEmbedding
patch_embは$(1,1,64)$の重み、pos_embは$(1,65,64)$の重みである。
入力 $(batch,64,64)$にpatch_emb$(batch,1,64)$をaxis=1に結合し、それに更にpos_emb$(batch,65,64)$を足したものを出力$(batch,65,64)$とするレイヤーである。
class Add_Embedding_Layer(tf.keras.layers.Layer):
def __init__(self, num_patches=64, d_model=64, batch_size=16):
super(Add_Embedding_Layer, self).__init__()
self.batch_size = batch_size
self.patch_emb = self.add_weight(shape=[1, 1, d_model], dtype=tf.float32)
self.pos_emb = self.add_weight(shape=[1, num_patches+1, d_model], dtype=tf.float32)
def call(self, input):
patch_emb = K.repeat_elements(self.patch_emb, self.batch_size, axis=0)
pos_emb = K.repeat_elements(self.pos_emb, self.batch_size, axis=0)
return K.concatenate([input, patch_emb], axis=1) + pos_emb
TransformerBlock
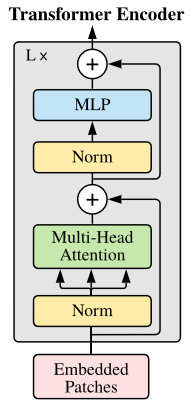
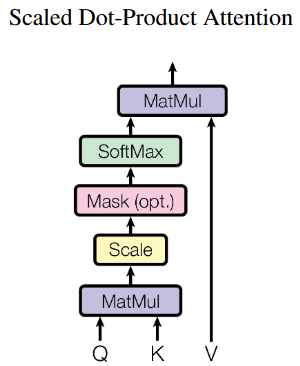
query,key,valueはそれぞれ$(batch,65,64)$のサイズで全結合出力として作られ、num_heads=4の場合、$(batch,65,64)=>(batch,65,4,16)=>(batch,4,65,16)$となる。
次にscore = tf.matmul(query, key, transpose_b=True)でtranspose_b=Trueによってkeyの行列は最後の2軸が入れ替わる。(transpose_a=Trueならqueryの最後の2軸が入れ替わる)
c = tf.matmul(a, b)でaの行列が$(m,n,i,k)$、bの行列が$(m,n,k,j)$の場合、行列積cの行列は$(m,n,i,j)$になる。
従って**queryが$(batch,4,65,16)$、keyが$(batch,4,16,65)$であるからscoreは$(batch,4,65,65)$となる。**これを$\sqrt d$で割って$softmax$を掛ける。
これにvalueを掛けると、scoreが$(batch,4,65,65)$とvalueが$(batch,4,65,16)$であるからattentionは$(batch,4,65,16)$となる。
これを先ほどと逆に変形させ$(batch,4,65,16)=>(batch,65,4,16)=>(batch,65,64)$となり、入力と同じサイズになる。
これはAttentionの良く知られる式
Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d}}) \cdot V
である。
さて、tf.matmul()ではなくてKerasのバックエンドのK.dotでこの演算が出来ないかというと出来ない。K.dotでこの計算をするには不備がある。
参考:https://github.com/keras-team/keras/issues/9779
また、TransformerBlockの論文に載っている図と実装が順番が異なる気がする。
論文の図はNorm→MultiHead_Attention→Residualなのだが、実装はMultiHead_Attention→Residual→Normになってしまっている気がする。
def MultiHead_SelfAttention(inputs, embed_dim, num_heads):
projection_dim = embed_dim // num_heads
batch_size = K.int_shape(inputs)[0]
query = Dense(embed_dim)(inputs)
key = Dense(embed_dim)(inputs)
value = Dense(embed_dim)(inputs)
query = K.reshape(query, (batch_size, -1, num_heads, projection_dim))
key = K.reshape(key, (batch_size, -1, num_heads, projection_dim))
value = K.reshape(value, (batch_size, -1, num_heads, projection_dim))
query = K.permute_dimensions(query, (0, 2, 1, 3))
key = K.permute_dimensions(key, (0, 2, 1, 3))
value = K.permute_dimensions(value, (0, 2, 1, 3))
score = tf.matmul(query, key, transpose_b=True)
score = score/K.sqrt(K.cast(projection_dim, 'float32'))
weights = Activation('softmax')(score)
attention = tf.matmul(weights, value)
attention = K.permute_dimensions(attention, (0, 2, 1, 3))
attention = K.reshape(attention, (batch_size, -1, embed_dim))
output = Dense(embed_dim)(attention)
return output
def TransformerBlock(inputs, embed_dim, num_heads, ff_dim):
attn_output = MultiHead_SelfAttention(inputs, embed_dim, num_heads)
attn_output = Dropout(0.1)(attn_output)
out1 = LayerNormalization(epsilon=1e-6)(Add()([inputs, attn_output]))
ffn_output = Dense(ff_dim, activation="relu")(out1)
ffn_output = Dense(embed_dim)(ffn_output)
ffn_output = Dropout(0.1)(ffn_output)
return LayerNormalization(epsilon=1e-6)(Add()([out1, ffn_output]))
パラメータ比較

以下のパラメータの数を確認したところ凡そ合っている。
正確にはPatch + PositionのEmbeddingのパラメータ数は画像サイズに依存するし、最後の分類Classの数にも依存する。
ViT_Base = make_ViT(num_layers=12, d_model=768, num_heads=12, mlp_dim=3072, num_classes=10)
ViT_Base.summary()
ViT_Large = make_ViT(num_layers=24, d_model=1024, num_heads=16, mlp_dim=4096, num_classes=10)
ViT_Large.summary()
ViT_Huge = make_ViT(num_layers=32, d_model=1280, num_heads=16, mlp_dim=5120, num_classes=10)
ViT_Huge.summary()
......
========================================================
Total params: 87,535,882
Trainable params: 87,535,882
Non-trainable params: 0
________________________________________________________
========================================================
Total params: 306,666,506
Trainable params: 306,666,506
Non-trainable params: 0
________________________________________________________
========================================================
Total params: 636,435,210
Trainable params: 636,435,210
Non-trainable params: 0
________________________________________________________
これらのパラメータ数の内、TransformerBlockのMultiHead_SelfAttentionのパラメータ数はembed_dim×embed_dim×4で、MLPのパラメータ数はembed_dim×mlp_dim×2であり、TransformerBlockのLayer数だけ掛ければTransformerBlockのパラメータ数は計算できる。
以下はTransformerBlockのパラメータ数である。ViTモデルの内パラメータの98%以上がTransformerBlockであることが分かる。
| TransformerBlock | embed_dim | mlp_dim | num_layer | Param |
|---|---|---|---|---|
| ViT_Base | 768 | 3072 | 12 | 84,934,656 |
| ViT_Large | 1024 | 4096 | 24 | 301,989,888 |
| ViT_Huge | 1280 | 5120 | 32 | 629,145,600 |
その他
・データはbatch_sizeで割り切れないといけない。
データがbatch_sizeで割り切れないと、1epochの最後のbatchでエラーが出る。
・ViT-H/14、ViT-L/16の14とか16とか何?
1パッチ当たりの画像のサイズ。パッチの大きさではない。
入力が224×224の画像で1パッチ当たりの画像のサイズが14×14ならパッチの大きさは16である。
入力が224×224の画像で1パッチ当たりの画像のサイズが16×16ならパッチの大きさは14である。
1パッチ当たりの画像のサイズとパッチの大きさは半比例する。
・事前学習なしの精度
cifar10で学習してみたが、別に精度は良いわけではない。
巨大なデータセットのJFT-300Mで事前学習を行わなければCNN以上の精度は出ないと思われる。
・pytorchでの実装例では非常に簡潔に書かれている。
https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit_pytorch.py
例えば、query、key、valueのそれぞれの全結合を行い、行列をReshapeし、行列軸を入れ替えるというコードが僅か2行で書かれている。行列の変形、行列軸入れ替え、行列分割が一行でできるrearrangeを使えばもっとコードを簡略化出来そうです。その反面、ぱっと見で何をやってるかという理解が若干しづらいのではと思います。
qkv = nn.Linear(dim, dim * 3, bias = False)(x)
q, k, v = rearrange(qkv, 'b n (qkv h d) -> qkv b h n d', qkv = 3, h = h)
上記コードは下記コードと等価。
query = Dense(embed_dim)(inputs)
key = Dense(embed_dim)(inputs)
value = Dense(embed_dim)(inputs)
query = K.reshape(query, (batch_size, -1, num_heads, projection_dim))
key = K.reshape(key, (batch_size, -1, num_heads, projection_dim))
value = K.reshape(value, (batch_size, -1, num_heads, projection_dim))
query = K.permute_dimensions(query, (0, 2, 1, 3))
key = K.permute_dimensions(key, (0, 2, 1, 3))
value = K.permute_dimensions(value, (0, 2, 1, 3))
全コード
cifar10用の学習コード。100行程度で書けた。
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow.keras.layers import Dense, Dropout, LayerNormalization, Add, Activation, Input
from tensorflow.keras.layers.experimental.preprocessing import Rescaling
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
def MultiHead_SelfAttention(inputs, embed_dim, num_heads):
projection_dim = embed_dim // num_heads
batch_size = K.int_shape(inputs)[0]
query = Dense(embed_dim)(inputs)
key = Dense(embed_dim)(inputs)
value = Dense(embed_dim)(inputs)
query = K.reshape(query, (batch_size, -1, num_heads, projection_dim))
key = K.reshape(key, (batch_size, -1, num_heads, projection_dim))
value = K.reshape(value, (batch_size, -1, num_heads, projection_dim))
query = K.permute_dimensions(query, (0, 2, 1, 3))
key = K.permute_dimensions(key, (0, 2, 1, 3))
value = K.permute_dimensions(value, (0, 2, 1, 3))
score = tf.matmul(query, key, transpose_b=True)
score = score/K.sqrt(K.cast(projection_dim, 'float32'))
weights = Activation('softmax')(score)
attention = tf.matmul(weights, value)
attention = K.permute_dimensions(attention, (0, 2, 1, 3))
attention = K.reshape(attention, (batch_size, -1, embed_dim))
output = Dense(embed_dim)(attention)
return output
def TransformerBlock(inputs, embed_dim, num_heads, ff_dim):
attn_output = MultiHead_SelfAttention(inputs, embed_dim, num_heads)
attn_output = Dropout(0.1)(attn_output)
out1 = LayerNormalization(epsilon=1e-6)(Add()([inputs, attn_output]))
ffn_output = Dense(ff_dim, activation="relu")(out1)
ffn_output = Dense(embed_dim)(ffn_output)
ffn_output = Dropout(0.1)(ffn_output)
return LayerNormalization(epsilon=1e-6)(Add()([out1, ffn_output]))
class Add_Embedding_Layer(tf.keras.layers.Layer):
def __init__(self, num_patches=64, d_model=64, batch_size=16):
super(Add_Embedding_Layer, self).__init__()
self.batch_size = batch_size
self.patch_emb = self.add_weight(shape=[1, 1, d_model], dtype=tf.float32)
self.pos_emb = self.add_weight(shape=[1, num_patches+1, d_model], dtype=tf.float32)
def call(self, input):
patch_emb = K.repeat_elements(self.patch_emb, self.batch_size, axis=0)
pos_emb = K.repeat_elements(self.pos_emb, self.batch_size, axis=0)
return K.concatenate([input, patch_emb], axis=1) + pos_emb
epochs = 30
batch_size = 400
def make_ViT(img_size = 32, ch_size = 3, patch_size = 4,
batch_size = 400, num_layers = 4, d_model = 64,
num_heads = 4, mlp_dim = 128, num_classes = 10):
num_patches = (img_size // patch_size) ** 2
patch_dim = ch_size * patch_size ** 2
inputs = Input(shape=(32, 32, 3))
x = Rescaling(1./255)(inputs)
x = tf.nn.space_to_depth(x, patch_size)
x = K.reshape(x, (-1, num_patches, patch_dim))
x = Dense(d_model)(x)
x = Add_Embedding_Layer(num_patches, d_model, batch_size)(x)
for _ in range(num_layers):
x = TransformerBlock(x, d_model, num_heads, mlp_dim)
x = Dense(mlp_dim, activation=tfa.activations.gelu)(x[:, 0])
x = Dropout(0.1)(x)
y = Dense(num_classes, activation='softmax')(x)
return Model(inputs=inputs, outputs=y)
model = make_ViT()
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), verbose=1)