Mix-of-ShowのED-LoRAについて調べる。
これについての考察も適当に書いてみる。
各手法の特徴
ED-LoRAと比較するために各手法を軽くまとめる。
Textual Inversion
TokenizerとTextEncoderに新しい単語(例えば<cat-toy>)を追加し、その追加Embeddingを学習する。Dreamboothと異なりUnetは全く学習されない。また、既存Embeddingは学習させず、追加Embeddingのみ学習する。
また、Multi token Textual Inversionではnum_vec_per_tokenを設定してtokenizer.add_tokens(['<cat-toy>_0', '<cat-toy>_1']のように複数のtokenを追加してそれに対して学習もできる。
num_added_tokens = tokenizer.add_tokens(['<cat-toy>'])
text_encoder.resize_token_embeddings(len(tokenizer))
...
# Freeze vae and unet
vae.requires_grad_(False)
unet.requires_grad_(False)
# Freeze all parameters except for the token embeddings in text encoder
text_encoder.text_model.encoder.requires_grad_(False)
text_encoder.text_model.final_layer_norm.requires_grad_(False)
text_encoder.text_model.embeddings.position_embedding.requires_grad_(False)
...
with torch.no_grad():
accelerator.unwrap_model(text_encoder).get_input_embeddings().weight[
index_no_updates
] = orig_embeds_params[index_no_updates]
Dreambooth
一般に学習promptを"a photo of sks cat"として特に使用されないレアトークン(sks)を対象に学習する。また、"cat"のような学習対象のclass_tokenを使用すると学習が安定化する。
この手法の欠点としてレアトークンを使用しない"a photo of cat"の結果が学習データに引っ張られる。
これを解消するにはwith_prior_preservationを有効にしてclass_prompt="a photo of cat"として猫の正則化画像で同時に学習する事で解消される。
また、学習モデルが非常に大きく配布に向かない。
CustomDiffusion
Textual Inversionに追加してUnetの内の$K,V$重みのみを学習して保存している。
$K,V$重みとTI重みのみなのでDreamboothに比べると大分小さい(Unet全体の5%)。また特異値分解で削減もできる。
過去記事で示したようにMulti-Concept Optimizationという別々に学習した二種類のCustomDiffusion重みを一個のモデルにマージする事が出来る。
今回紹介するED-LoRAも各学習データで別々に学習した重みを一つのモデルにマージするのを主眼のひとつとしており、モデルの目的は似ている。
LoRA
$W=W_0+LoRA_{down} \cdot LoRA_{up}$となる変化差分を次元の低い二個の行列で示す。例えば元の行列が$W_0=(768,320)$なら$LoRA_{down}=(768,4)$、$LoRA_{up}=(4,320)$でこれを掛けると$\Delta W=(768,320)$となる。
LoRAには亜種(LyCORIS(LoHa・LoCon), DyLoRA)がありどう違うのかは自分は把握していない。
P+(XTI)
Textual Inversionの発展型で、Unetに渡すEmbedding重みはUnetの16層毎に異なる。
自分のED-LoRAの認識はP+(XTI)にLoRAを採用したものという認識である
手法の違い
大別してTextEncoderのEmbedding重みを学習するembedding tuning(TI,XTI)と主にUnetを学習するjoint embedding-weight tuning(DB,LoRA)に分かれる。
前者はモデルのドメイン内の概念を捕捉し、後者はモデルのドメイン外(スタイル、細かいディティール)の情報を補足するらしい。ED-LoRAはP+(XTI)とLoRAの両方を採用している。
TI+DBの手法はhttps://huggingface.co/blog/dreambooth でも見られる。
| Method | embedding tuning | joint embedding-weight tuning |
|---|---|---|
| ED-LoRA | ◎ | ◎ |
| Textual Inversion | 〇 | × |
| Dreambooth | × | 〇 |
| CustomDiffusion | 〇 | 〇 |
| LoRA | × | ◎ |
| P+(XTI) | ◎ | × |
Multi-Concept Fusion
ED-LoRAの一番の大きな特徴は別々のデータセットで独立に学習したED-LoRAの重みをまとめて一個のモデルに学習させることが可能である。
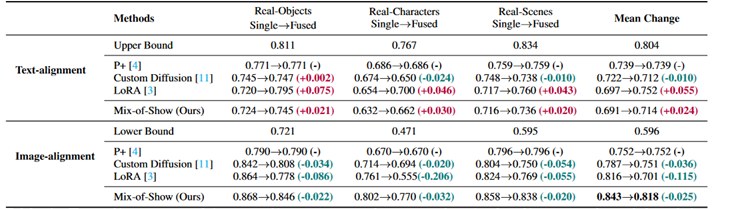
論文の表を示す。
・P+は複数の学習重みを劣化なしに結合できるがImageAlignmentがやや低い。
・CustomDiffusionはP+よりImageAlignmentが高く、複数の重みをまとめて一個のモデルにした時も比較的劣化は小さい。
・LoRAはImageAlignmentが非常に高い一方で、一個のモデルにした時の劣化が激しい。
・ED-LoRAはImageAlignmentもLoRA並みに高く、一個のモデルにした時の劣化もCustomDiffusionのように小さい。一方で複数のLoRAからモデルをまとめると言った使い方を想定しなければLoRAで十分である。
| Method | ImageAlignment | Fused model |
|---|---|---|
| ED-LoRA | ◎ | 〇 |
| P+(XTI) | △ | ◎(劣化無し) |
| CustomDiffusion | 〇 | 〇 |
| LoRA | ◎ | ×(劣化激しい) |
Gradient_Fusion
CustomDiffusionでは下記の式を満たす$W$を求めていた。$C$は$K,V$の入力、$W$は$K,V$の全結合重みである。
W=argmin|WC_{reg}-W_0C_{reg}|\\
W=argmin|WC_{i}-W_iC_{i}|
ED-LoRAのGradient_Fusionでは以下である。
W=argmin|WC_{i}-(W_0+ΔW_i)C_{i}|^2
すなわち、CustomDiffusionの式と近いように思えるが、CustomDiffusionはLU分解等を使って$W$を解いていたのに対して、Gradient_FusionではMSE_lossを使って$W$を求めている。最初$\frac{∂L}{∂W}=0$となる方程式を解くのかと思ったのだが違うようだ。
Loss=(WC_{i}-(W_0+ΔW_i)C_{i})^2\\
\frac{∂L}{∂W}=2(WC_{i}-(W_0+ΔW_i)C_{i})C_i^T
参考までに$Ax=B$を解くのに$A^TAx=A^TB$とする方法を最小二乗法の正規方程式という。$A^TA$が正方行列になるため容易なガウスジョルダン法でも方程式が解ける。
難しい事を考えず$Ax=B$を解くのはdgelss関数とかが有名。
また、マージモデル$W$ではなくマージLoRA$\Delta W=(W-W_0)$を作成したいなら以下の様にすればよいのではと思った。
Loss=((W-W_0)C_{i}-(ΔW_i)C_{i})^2
def update_quasi_newton(K_target, V_target, W, iters, device):
...
if len(W.shape) == 4:
loss = F.mse_loss(F.conv2d(K_target.to(device), W), V_target.to(device))
else:
loss = chunk_compute_mse(K_target, V_target, W, device)
...
loss.backward()
regionally controllable sampling
ED-LoRAのもう一つの目的が複数のキャラを並べて書くことが出来る。
しかし、ControlNetやT2I-Adaptorの知見がないので詳しくは不明。
書き出す範囲とOpenposeの画像を予め与える事でキャラクタを並べて書くようである。各描写領域は領域が重複しなければいくらでも書けるようである。
randomly initialized token
<hina1>はランダムに初期化され、<hina2>はclass_tokenで初期化される。
Dreamboothにおける"sks girl"と等しいと思われる。
network_g:
new_concept_token: <hina1>+<hina2> # Concept new token, use "+" to connect
initializer_token: <rand-0.013>+girl
# Init token, only need to revise the later one based on the semantic category of given concept
0.013の数値は初期正規分布の大きさの様である。
if init_token_layer.startswith('<rand'):
sigma_val = float(re.findall(r'<rand-(.*)>', init_token_layer)[0])
token_embeds[token_id] = torch.randn_like(token_embeds[0]) * sigma_val
logger.info(f'{token_id} is random initialized by: {init_token_layer}')
モデル重みのチェック
実装が公開されているのでhttps://github.com/TencentARC/Mix-of-Show/tree/research_branch から
edlora_hina.pthの中身を確認する。このedloraのファイルサイズは4482KB。
中身は['new_concept_embedding', 'text_encoder', 'unet']であり、中身はP+(XTI) embedding、TextEncoder_LoRA、Unet_LoRAである。
import torch
path = './edlora_hina.pth'
state_dict = torch.load(path, map_location="cpu")
print(state_dict['params'].keys())
print(state_dict['params']['new_concept_embedding'].keys())
print(state_dict['params']['new_concept_embedding']['<hina1>'].shape)
print(state_dict['params']['new_concept_embedding']['<hina2>'].shape)
--------------------------------------------------------------------------------
dict_keys(['new_concept_embedding', 'text_encoder', 'unet'])
dict_keys(['<hina1>', '<hina2>'])
torch.Size([16, 768])
torch.Size([16, 768])
DropLoRA
設定パラメータを見ているとunet_kv_dropというよく分からない値を見た。
論文中にあるDropLoRAという概念と関係あるだろうか。
unet_kv_drop_rate: 0.0
まとめ
ED-LoRAの論文を少し読んだ。
ED-LoRAはP+(XTI)とLoRA両方実行するもので、利点としてCustomDiffusionのように独立で学習した重みを一個のモデルにマージする事が可能であるらしい。