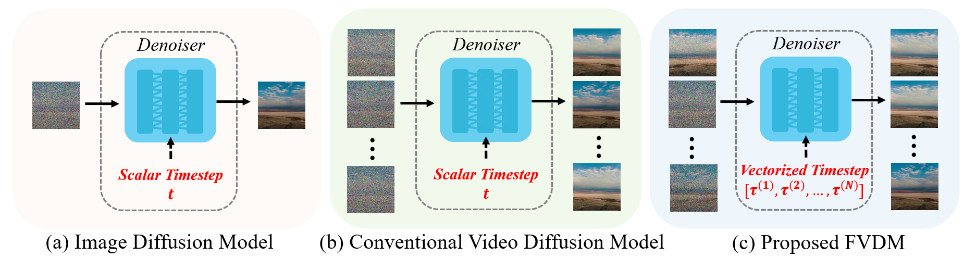
以下の論文でフレーム方向にTimestepを変化させるファインチューニング手法を述べられている。従来技術との比較においてこれらが既存の考え方とどのように違うか図を考えてみる。
Vectorized Timestepは固定されたTimestepではなく、生成フレームごとに異なるノイズレベルを定義して異なるTimestepを与えて生成する。
① T2I→I2V
T2Iを使って1枚の画像を最初に作成し、その後I2Vによって画像に繋がる動画を作成する。
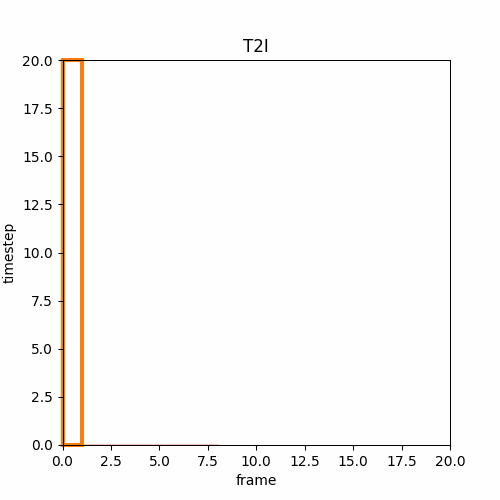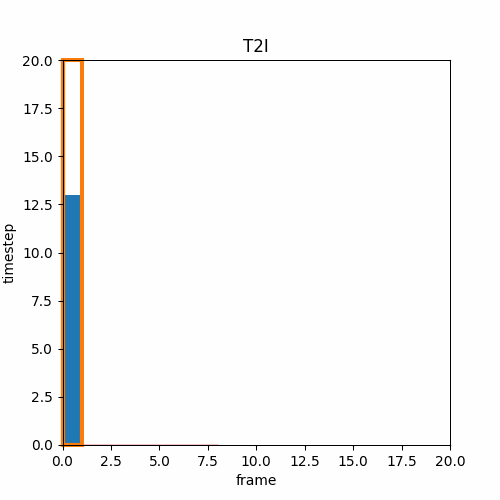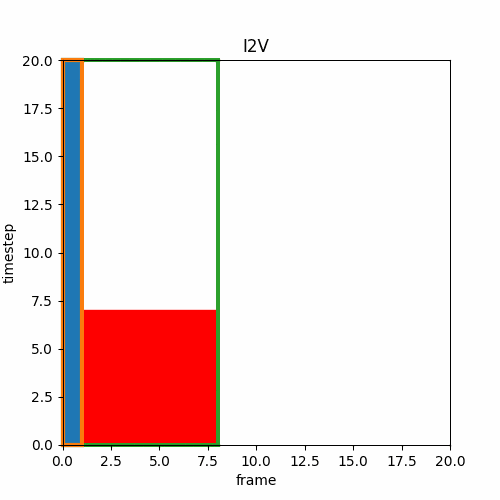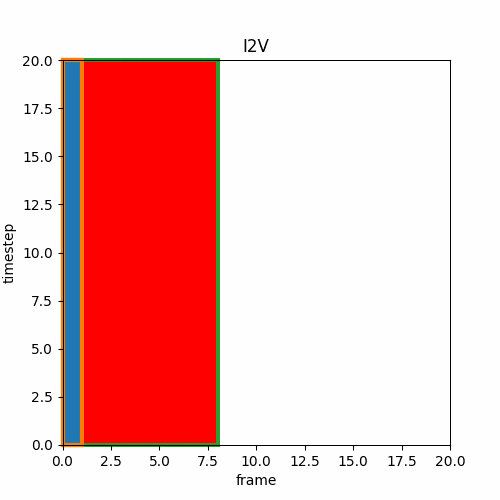
② ラストフレームの画像を使ってI2V
動画を作成してその最終フレームの画像から以下I2Vで動画の続きを作る。これを繰り返せば無限に連続する動画を作れる。ただし、一点問題があり、最初の動画と二番目の動画の動きが一致するとは限らない。例えばボールが移動する動画を作る時、最初の動画ではボールは左から右に動くかもしれないが二番目の動画では上から下に動くかもしれず、ボールの動きは動画の区切りで急激に向きを変える。
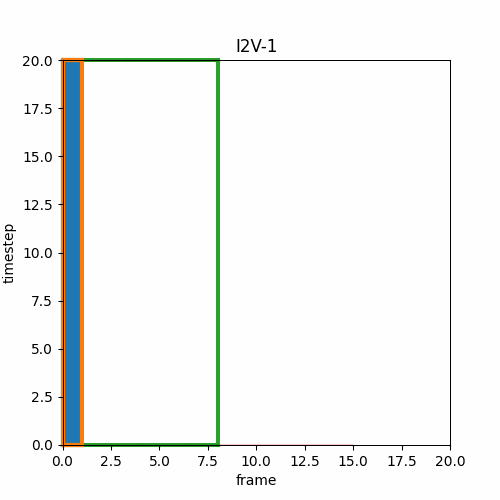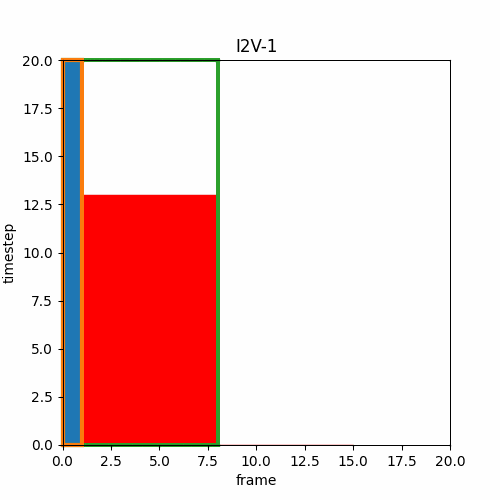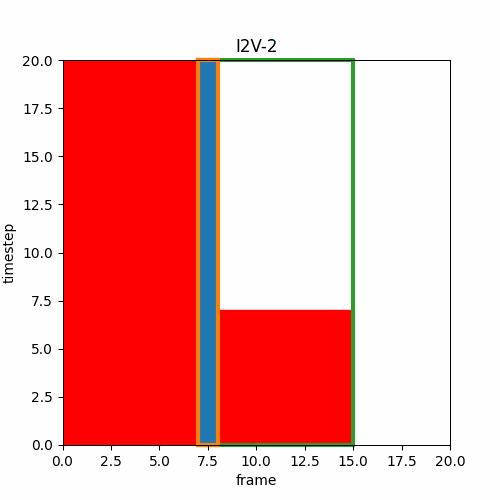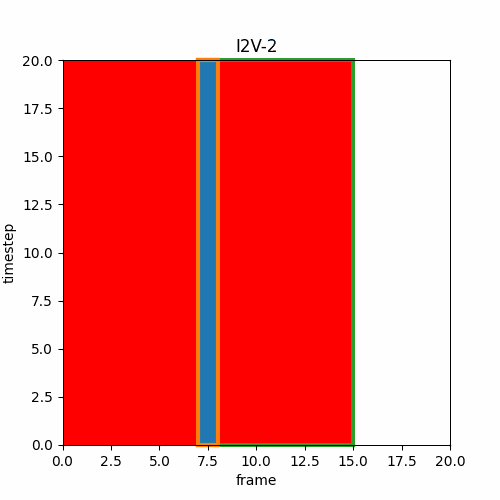
③ Video Interpolation, Loop Video
先頭フレームと終端フレームを指定し、I2Vによって間の動画を生成する。同じ画像を用いれば開始画像と終端画像が同一のループ動画を作成できる。Wan2.1-Fun-Inpが「start and end frame prediction」とあるのでこのようなInterpolationタイプだと思われる。
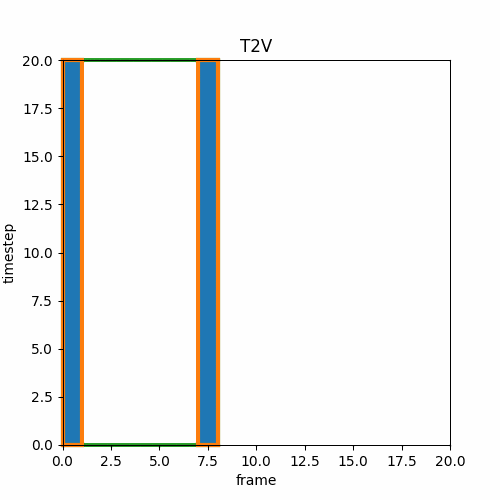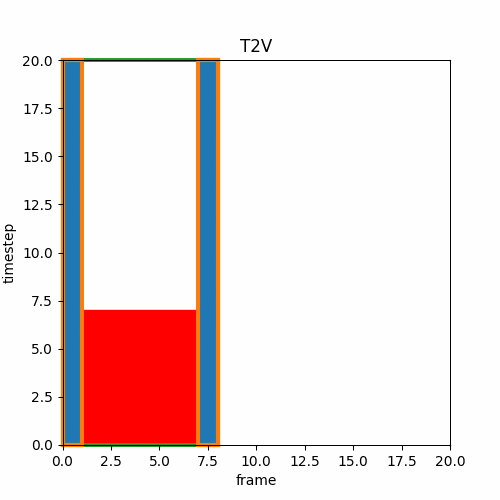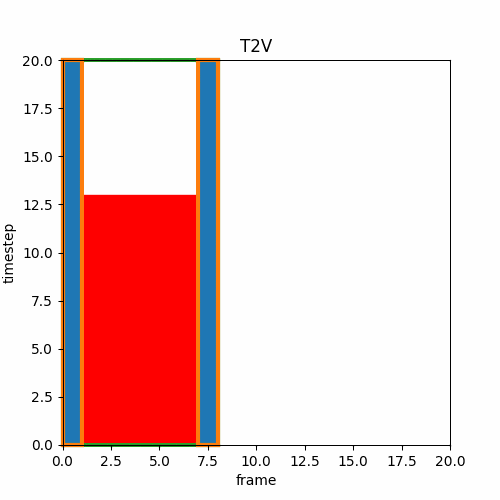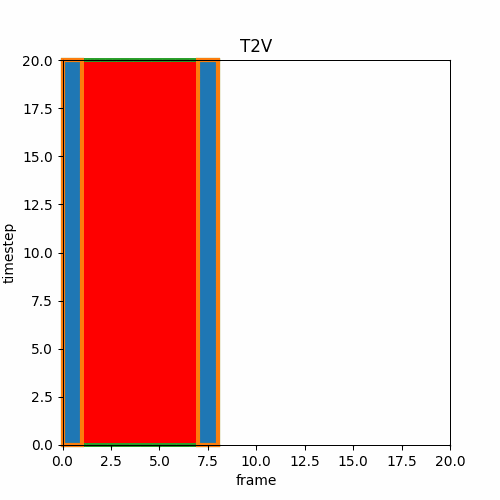
③ V2V
I2IやV2Vでは既存の画像や動画をVAEに通したlatentにノイズを加え途中の推論stepから開始する。これによって時間方向の連続性は維持できないが推論stepを途中から始めて元の動画に似た動きや構図を作成できる。
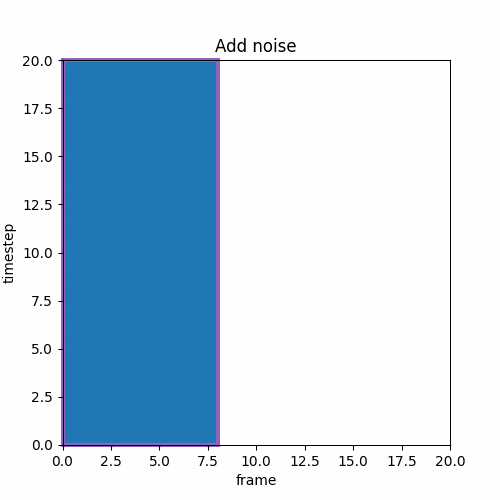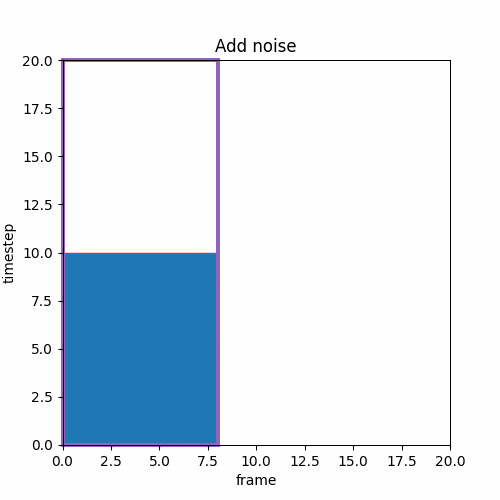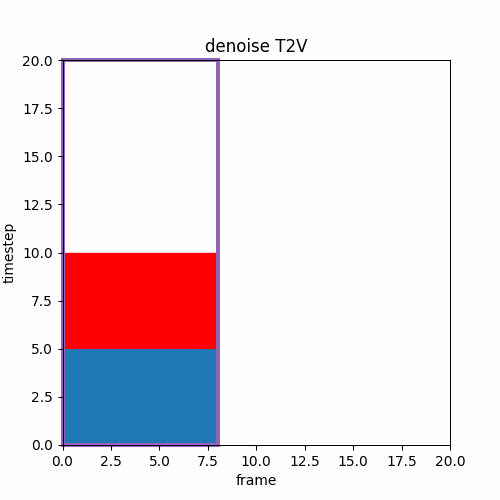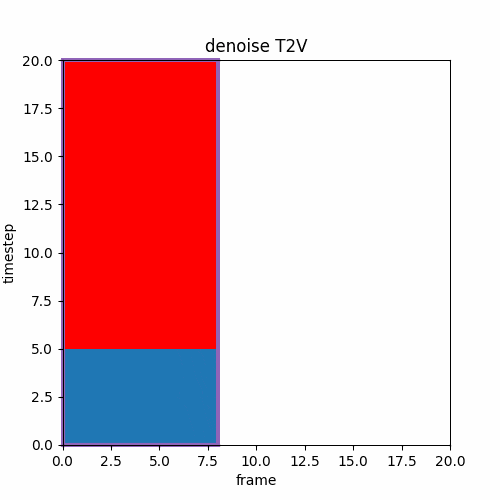
④ T2V→Upscale→V2V
低解像度で動画を作り、それを解像度を高解像度にアップスケールし、ノイズを加えV2Vで途中のstepから推論する。SDXLのrefinerのように前半と後半の推論でモデルが異なるケースもある。
ここでのUpscaleは生成した画像を単純に縦横の倍率を2倍にするパターンが多い。またはVAEを通す前の途中のlatentをUpscaleすることもある。
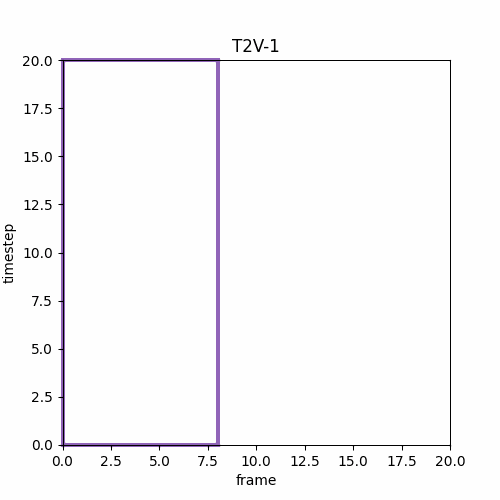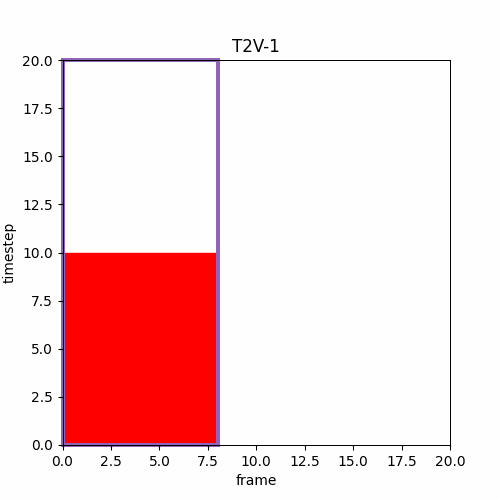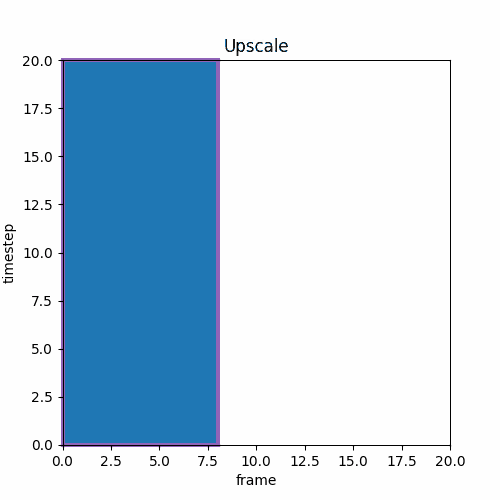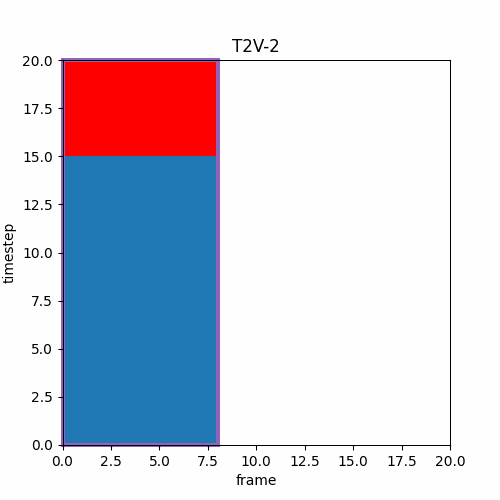
⑤ Long Video Generation
論文の図によると最後のMフレーム、次の動画のMフレームが他のlatentと異なるtimestepを設定できるなら以下のようになる。I2Vは先頭1フレームしか利用しないが論文の図は先頭Mフレームを利用するように見える。
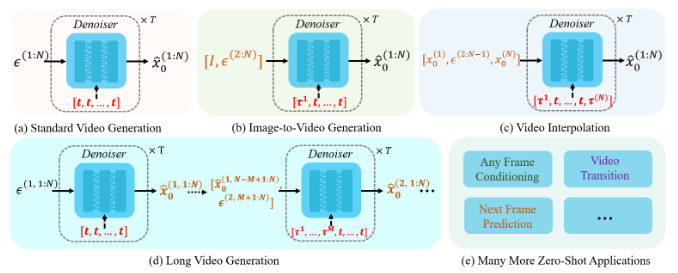
一般的な動画生成モデルであればこのようにフレームごとに複雑な生成方針を持つとき、生成ガイドにテキストや画像ガイドの他に動画のMASK構造を与えてファインチューニングモデルを作り、これを推論させるのが一般的である。これは画像生成モデルにおけるInpaintモデルである。
もっともこの論文ではMASK情報ではなく生成フレームごとに異なるTimestepを与えることでLong Video GenerationをはじめI2VやLoop Videoなど様々なタスクに応用が利くことを述べられている。
⑥ フレームごとに異なるTimeStepで推論できるなら
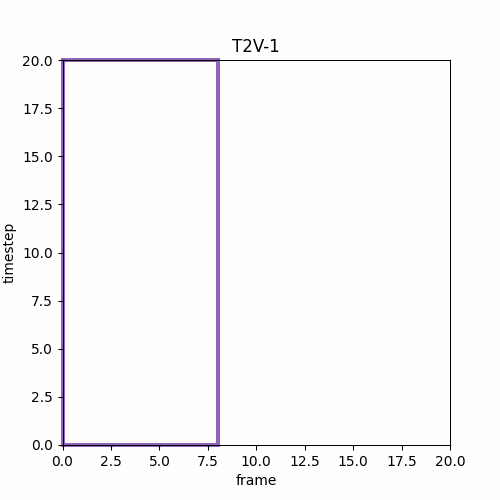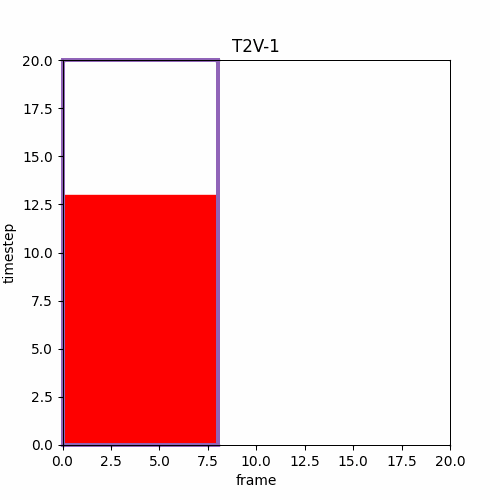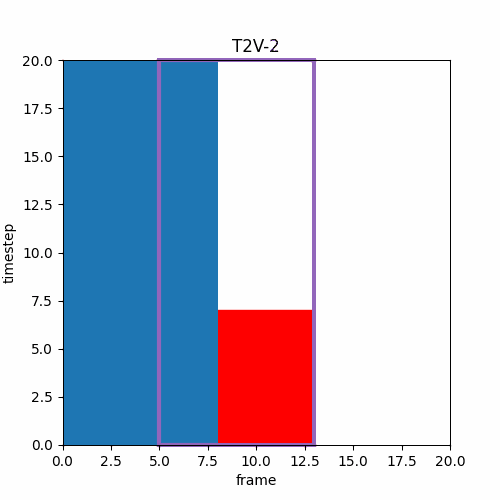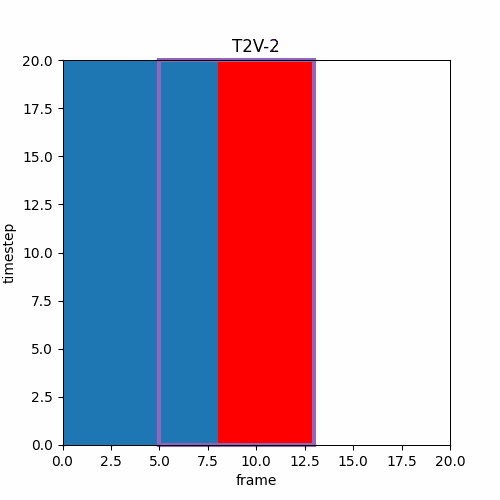
ここでV2Vと前述のLong Video Generationを考えるなら、途中でpromptの変更がある場合は以下のようにフレーム境界を滑らかに設定した方が良く作成できるのではと思った。
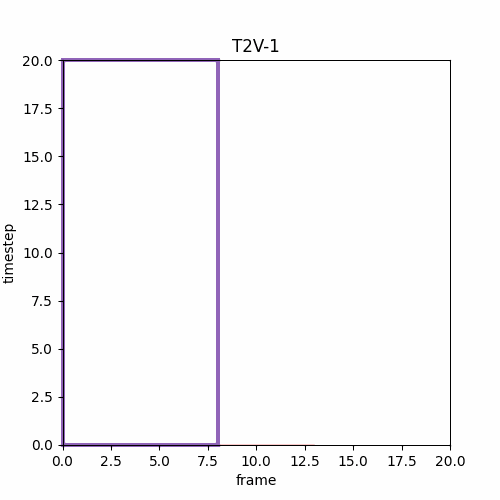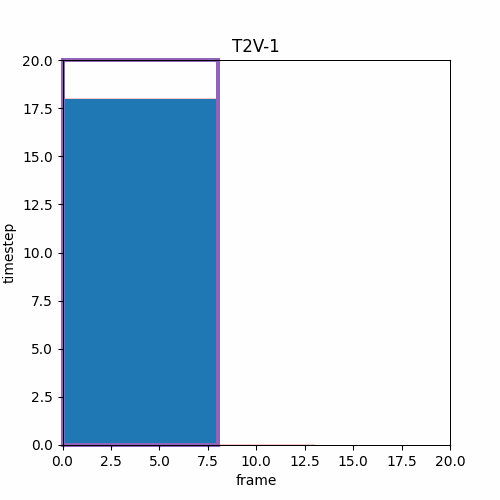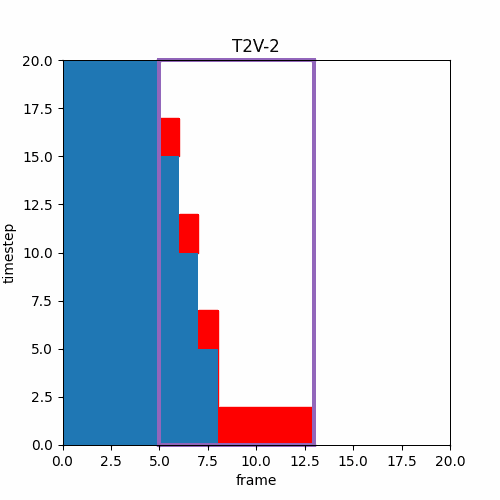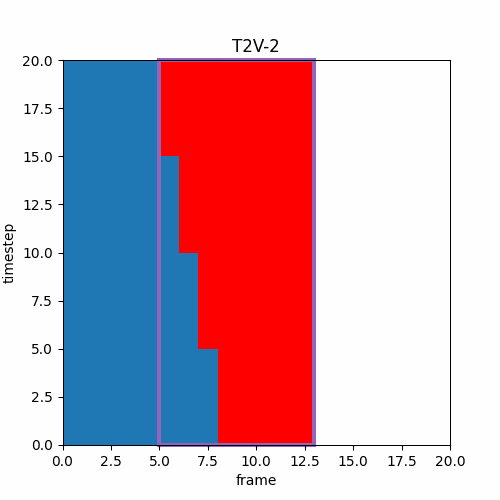
⑦ 生成フレーム範囲の並進
また、このような異なるTimestep推論が可能なら以下のようなTimestep増加と同時にフレーム範囲の前進を行えば、効率良く長い時間の動画を生成できるのではと思ったのだが。
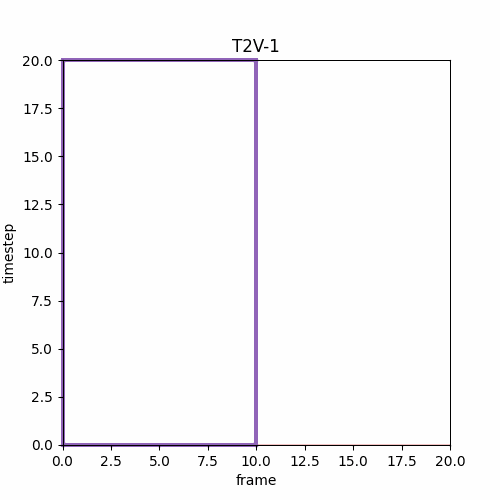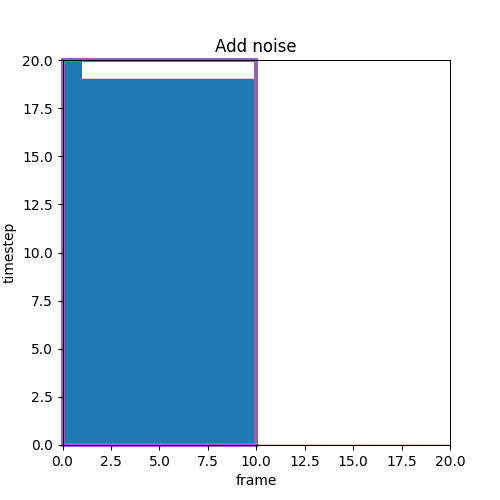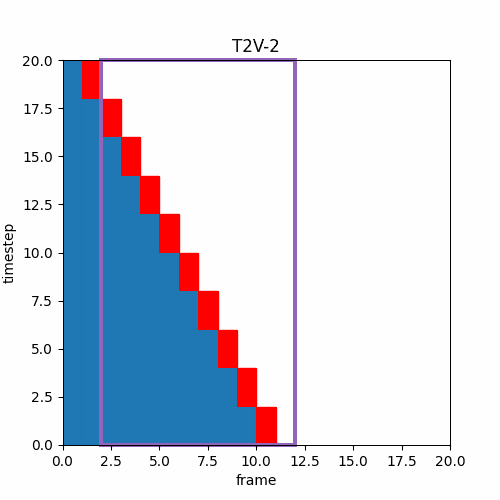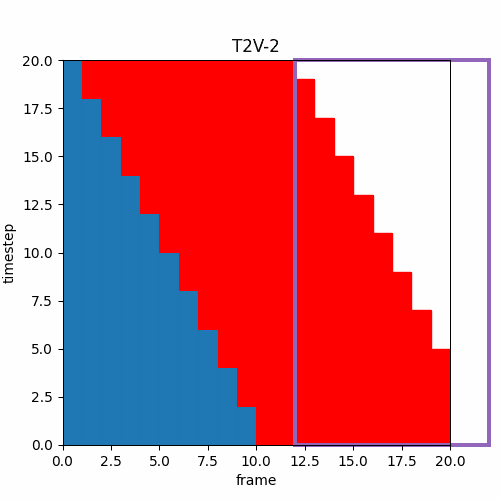
ファインチューンモデル学習時のノイズ加算
この論文には異なるTimestepを適応するのに、ブラウン運動(Brownian motion)やノイズ摂動(noise perturbation)がどうのこうのと書かれており意味不明である。

最初、これらがよく見かける拡散過程の式から出発してるのかと思ったが、数式的にはウィーナー過程の式の方に近い。前者(DDIM?)は拡散過程で生成ノイズを一回しか使用しないが、後者(DDPM)は拡散過程で何度も異なるノイズを足していく。
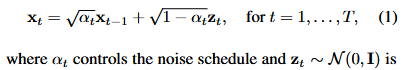
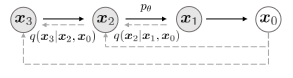

要するに拡散過程(Add noise)を表現する時、一個の生成ノイズにTimeStep比率を掛けて足してしまうと推論時に複数点のtimestep上の同一ノイズ加算に類似性が見られてしまうので良くない。DDPMのようにtimestepごとに毎回異なるノイズを加算していく必要がある、という事なのだろう、たぶん。
参考:
まとめ
Vectorized TimestepとI2Vとかの違いを考えてみるためにフレームとtimestepの推論図を考えてみた。