UPaintingの論文を流し読みしてこれって本当にCLIP guidanceなのか?符号が違うくないかと思った。何故そう思ったのかを説明したい。
かなり、自分なりの解釈を交えて話すので妄想多めです。
classifier-free guidance(CFG)
便宜上、現在の入力を$x_t$、プロンプトを入れた拡散モデルの出力を$\epsilon(x_t,c)$、ネガティブプロンプトを入れた拡散モデルの出力を$\epsilon(x_t,uc)$とする。
CFGがない拡散モデルでは
x_{t+1}=\epsilon(x_t,c)
CFG_Scale=0を標準とすれば
x_{t+1}=\epsilon(x_t,c) + cfg\_scale \cdot(\epsilon(x_t,c)-\epsilon(x_t,uc))
CFG_Scale=1を標準とすれば
x_{t+1}=\epsilon(x_t,uc) + cfg\_scale \cdot(\epsilon(x_t,c)-\epsilon(x_t,uc))
となる。
これは「プロンプトによって描かれる成分(変動分移動)を増幅しよう!」という意図がある。
GLIDEのCLIP guidance
GLIDEなどの論文ではCLIP Image Encorderの出力を$f(x_t)$、CLIP Text Encorderの出力を$g(c)$、プロンプトを$c$とすれば
x_{t+1}=\epsilon(x_t,c) + CLIP\_scale \cdot\nabla(f(x_t)\cdot g(c))
と書ける。
すなわち、CFGと同じく「プロンプトによって描かれる成分を増幅しよう!」という立場であろう。
ただし、欠点としてCLIP guidanceはCLIP Image Encorder$f(x)$自体がノイズ混じりの入力に適しておらず、ノイズ混じりの入力を使ってCLIPを再学習しなければいけないという問題がある。
しかも、そのCLIP guidanceの補正性能も従来のCFGに劣る。
UPaintingのCLIP guidance
UPaintingは従来のCLIP guidanceがノイズデータ加えたデータでCLIPを再学習しなければいけないという課題に対してノイズ混じりの再学習なしでCLIP guidanceを使っている。つまりここのCLIPはノイズなしのきれいな画像が入力されないといけない。
従ってこの本質は、一度CFGのみで画像生成し、その画像を使って(ブレンドしつつ)CLIP guidanceを計算する。
すなわちCFGのみで生成した画像を$x_0$として、ブレンド画像$x_{in}$を作る。
x_{in}=\sqrt{1-\alpha}\cdot x_0 - (1-\sqrt{1-\alpha})x_t
このCFGのみの$x_0$を利用した$x_{in}$を使ってUPaintingのCLIP guidanceの式は以下の通りである。
問題は符号が逆なのである。
x_{t+1}=\epsilon(x_t,c) - CLIP\_scale \cdot\sqrt{1-\alpha} \cdot \nabla(f(x_{in})\cdot g(c))
すなわち、「プロンプトによって描かれる成分を増幅しよう!」ではなく「このプロンプトのままじゃ描かれない成分を増幅しよう!」という目的に変わっている。
これは勾配計算時にテキストベクトルと画像ベクトルの内積の正解を0として与えるか1として与えるかの違いであろう。
通常のCLIP guidanceはベクトル内積を0とするから「CLIPによる増幅する成分」を取り出せる。
一方、UPaintingのCLIP guidanceはベクトル内積を1とするから「CLIPで見た足りない(または余剰な)成分」を取り出す。
前者は勾配は正だが、後者では負になるため移動の方向は同じだが勾配の符号にマイナスが必要になる。
以上、というのが、自分の勝手な推測だが、どうなのだろうか?
本当に複雑なpromptを理解できるのか?
以下の様に「簡単なprompt(small-scene)」ではSDと忠実性(Fidelity)ではどっこいどっこいである。
しかし、「複雑なprompt(complex-scene)」を描かせればSDよりもよくなるという事を主張している。
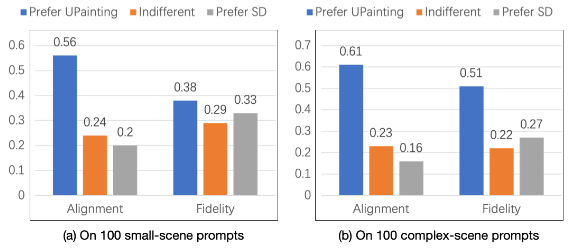
例えばpromptの指定する要素は5個あり、実際に描かれるのが4個だとする。
この場合、UPaintingのCLIP guidanceはpromptに指定する成分の内、描かれなかった1個の要素のみを強める成分を持つ。
また、promptの指定する要素は5個あり、実際に描かれるのが6個だとする。
この場合、UPaintingのCLIP guidanceは過剰に描かれた任意の要素を低減する。
このような成分は要素の漏れを減らし、promptの忠実性を高めれるとしても、これは決して複雑なpromptを理解しているというわけではない。入学試験で例えれば、二重チェックでケアレスミスを減らしているだけで、難易度の高い問題が解けているわけではない気がする。
なぜ最初の10stepをスキップするのか?
何故か10stepをスキップした方がFID、CLIPスコアが共に良い。
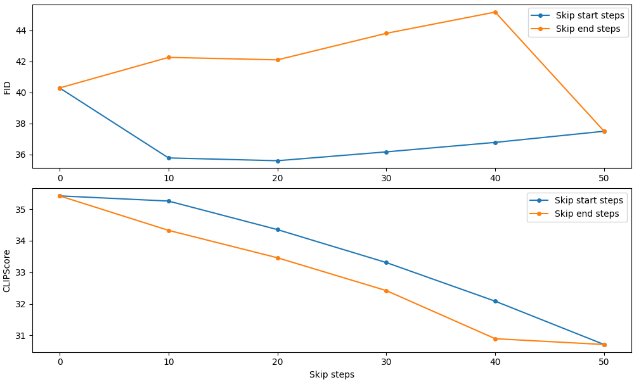
歴史改変系SFに例えれば、悪かった未来を知っていれば、少しずつ過去を改変しても少し良い未来にすることは出来る。しかし、根本を変えてしまうと知っていた未来とはまるで変ってしまい、知っている未来の知識を使った小さな歴史改変が全然上手く行かなくなる。
これが、初期のステップをスキップする理由になるのではと想像する。初期ステップをスキップして大きな歴史改変を起こさないようにする(?)という意味である。
…科学的な説明でなくて申し訳ない。
補完したいだけならCFGだけでもいい?
別に、classifier-free guidanceだけでも要素を補完できるのではと思った事を書いておく。CFGのみで生成した画像を$x_0$とする。
x_{in}=\sqrt{1-\alpha}\cdot x_0 - (1-\sqrt{1-\alpha})x_t
画像に対してキャプションを付与するBLIPモデル(CLIP interrogator、DeepDanbooru integration)の$h(x)$を用意する。このBLIPモデルの与えるキャプション(テキスト)を変化する$x_t$毎に$b_t=h(x_{in})$とする。CFGのみの画像と同一seed値で開始し、
x_{t+1}=\epsilon(x_t,c) + cfg\_scale \cdot(\epsilon(x_t,c)-\epsilon(x_t,uc)) - b\_scale \cdot(\epsilon(x_t,b_t)-\epsilon(x_t,c))
とすればよい。
これも同様に「このままだと描かれない要素」や「余分に描かれてしまった要素」を補完する効果があるのでは…と思うのだが。
まとめ
UPaintingの論文を流し読みして符号が気になった。
符号が違うとCLIP guidanceと増幅している成分が違う。従って、これをCLIP guidanceと呼べないのでは?と疑問に思った。