前回の記事に引き続いてSDXLのモデル重みをfloat16からInt型に変換してfloat16に戻す。
推論はfloat16のままなので推論速度は変わらない。
今回の記事内ではInt型に変換したデータを書き出して保存する事を目指す。
コード
前提として予めunet/diffusion_pytorch_model.fp16.safetensorsにSDXLのunet成分のstate_dict(モデル重みの辞書型)がsafetensorsで出力されているとする。
safetensorsのデータは純Tensor型のみでlist型などのデータは保持できない。(保存時、全てのデータをTensor型にしないといけない)
変換の精度は
Conv2DレイヤーはNF5(32)型にした。(全体の13%)
linearレイヤーはNF5(32),NF4.58(24),NF4(16),NF3.58(12),NF2.81(7)型にそれぞれした。(全体の86%)
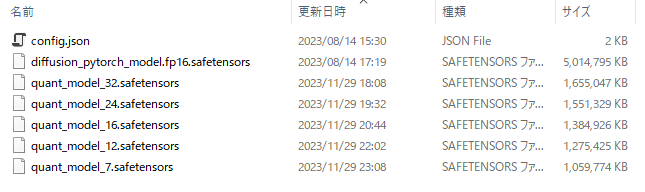
モデルサイズはlinearレイヤーがNF5(32)で1/3、NF3.58(12)で1/4、NF2.81(7)で1/5程度に削減できる。これはあくまで一パラメータ当たりの使用bit数を削減しているだけでSSD-1B(Segmind Stable Diffusion Model) のようなパラメータ数自体を削減している訳ではない。
また、LCM-XLやSDXL Turboのようなinference_stepを削減するタイプでもない。
モデルの更新日時を見てわかるようにモデル読み込み、Int型に変換、保存、保存したInt型の読み込み、float16型に戻す、unet重み置き換え、画像生成に一時間程度かかっており読み込み時間が増えるので正直全く実用的ではない。
また、pipeline読み込み時にunet=Noneが指定できないため結局のところ元のunet重み無しでは動かないという本末転倒な結果でもある。
from diffusers import DiffusionPipeline
from safetensors.torch import load_file, save_file
import torch
import numpy as np
import bz2
def make_q(split_num=16):
x = np.linspace(-1, 1, split_num+1)
Qx = torch.erfinv(torch.tensor(x, dtype=torch.float32) * 0.96)
Qx = Qx.detach().numpy().copy()
q = np.zeros(split_num)
q = (Qx[:-1]+Qx[1:])/2
q = q/np.max(q)
q = list(q)
q.append(1.3)
return q
def quantization(M, split_num):
shift_num = 50
q = make_q(split_num)
block_size1 = 64
block_size2 = 64*256
orig_shape = M.shape
orig_length = len(M.flatten())
if orig_length%block_size2==0:
extend_M = M.flatten()
else:
extend_M = torch.cat((M.flatten(), torch.zeros(block_size2 - orig_length%block_size2)))
extend_length = len(extend_M)
Mmax1 = []
for i in range(extend_length//block_size1):
Mmax1.append(torch.max(torch.abs(extend_M[block_size1*i:block_size1*(i+1)])))
Mmax1 = torch.stack(Mmax1, dim=0)
Mmax1 = Mmax1.repeat_interleave(block_size1)
Mmax2 = []
for i in range(extend_length//block_size2):
Mmax2.append(torch.max(torch.abs(extend_M[block_size2*i:block_size2*(i+1)])))
Mmax2 = torch.stack(Mmax2, dim=0)
Mmax2 = Mmax2.repeat_interleave(block_size2)
Mmax2_save = Mmax2[::block_size2].clone()
c1 = torch.round(255.0 * Mmax1 / Mmax2).to(torch.uint8)
c1_save = c1[::block_size1].clone()
c1 = c1.to(torch.float32).clamp(min=1e-12)
M2 = extend_M / (Mmax2 * c1 / 255.0)
for i in range(split_num):
M2 = torch.where(M2 <= (q[i]+q[i+1])/2, shift_num+i, M2)
M2 = torch.round(M2).to(torch.uint8)
M2 = M2[:orig_length]
M2 = bz2.compress(M2.detach().numpy().copy().tobytes().decode("ascii").encode("utf-8"))
M2_save = torch.from_numpy(np.array([M2]).view(np.uint8)).clone()
quant_param = torch.tensor([orig_length, split_num, shift_num, block_size1, block_size2], dtype=torch.int32)
#print('before_quant:', orig_length*2, ', after_quant:', len(c1_save) + len(Mmax2_save)*4 + len(M2_save), end=', ')
#print('quant_rate:', (len(c1_save) + len(Mmax2_save)*4 + len(M2_save))/(orig_length*2))
return orig_shape, quant_param, c1_save, Mmax2_save, M2_save
def save_quantization_model(model_path, output_path, linear_split_num, conv_split_num):
state_dict = load_file(model_path, device="cpu")
new_state_dict = {}
for name, param in state_dict.items():
if len(param.shape)==2 and not('emb' in name):
print(name, param.shape, type(param))
M = param.clone().to(torch.float32)
orig_shape, quant_param, c1, c2, M2 = quantization(M, linear_split_num)
new_state_dict[name] = torch.tensor([0]) # dummy_data
new_state_dict[name+'.quantization.orig_shape'] = torch.tensor(orig_shape)
new_state_dict[name+'.quantization.param'] = quant_param.clone()
new_state_dict[name+'.quantization.c1'] = c1.clone()
new_state_dict[name+'.quantization.c2'] = c2.clone()
new_state_dict[name+'.quantization.M'] = M2.clone()
elif len(param.shape)==4:
print(name, param.shape, type(param))
M = param.clone().to(torch.float32)
orig_shape, quant_param, c1, c2, M2 = quantization(M, conv_split_num)
new_state_dict[name] = torch.tensor([0]) # dummy_data
new_state_dict[name+'.quantization.orig_shape'] = torch.tensor(orig_shape)
new_state_dict[name+'.quantization.param'] = quant_param.clone()
new_state_dict[name+'.quantization.c1'] = c1.clone()
new_state_dict[name+'.quantization.c2'] = c2.clone()
new_state_dict[name+'.quantization.M'] = M2.clone()
else:
print(name, param.shape, type(param))
new_state_dict[name] = param.clone()
save_file(new_state_dict, output_path)
def load_quantization_model(path):
state_dict = load_file(path, device="cpu")
for name, param in state_dict.items():
if not('quantization' in name) and len(param)==1:
orig_shape = torch.Size(list(state_dict[name+'.quantization.orig_shape']))
print(name, orig_shape, type(orig_shape))
orig_length, split_num, shift_num, block_size1, block_size2 = tuple(state_dict[name+'.quantization.param'])
c1 = state_dict[name+'.quantization.c1']
c2 = state_dict[name+'.quantization.c2']
M = state_dict[name+'.quantization.M']
q = make_q(split_num)
c1 = c1.repeat_interleave(block_size1).to(torch.float32).clamp(min=1e-12)[:orig_length]
c2 = c2.repeat_interleave(block_size2)[:orig_length]
M = M.detach().numpy().copy().tobytes()
M = bz2.decompress(M)
M = torch.from_numpy(np.array([M]).view(np.uint8)-int(shift_num)).clone()
M2 = M.to(torch.float16)
for i in range(split_num):
M2 = torch.where(i==M, q[i], M2)
M2 = M2 * (c2 * c1 / 255.0)
M2 = M2[:orig_length].reshape(orig_shape).to(torch.float16)
state_dict[name] = M2.clone()
state_dict = {name: param for name, param in state_dict.items() if not('.quantization' in name)}
return state_dict
model_id = './stable-diffusion-xl-base-1.0/'
model_path = './stable-diffusion-xl-base-1.0/unet/diffusion_pytorch_model.fp16.safetensors'
output_img_path = './quant3/'
prompts = ['An ice sculpture is made with the text "Happy Holidays". Christmas decorations in the bacground. Dslr photo.',
'An origami of a monkey dressed as a monk riding a bike on a mountain.',
'A storefront with "Text to Image" written on it.',
'Greek statue of a man tripping over a cat.',
'A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says Welcome Friends!',
'A map of the United States made out of sushi. It is on a table next to a glass of red wine.',
'an armchair in the shape of an avocado',
'A teddybear on a skateboard in Times Square.']
seed = 42
generator = torch.Generator(device="cuda")
pipe = DiffusionPipeline.from_pretrained(model_id, use_safetensors=True, torch_dtype=torch.float16, variant="fp16").to("cuda")
pipe.enable_model_cpu_offload()
for split_num in [32, 24, 16, 12, 7]:
output_path = './stable-diffusion-xl-base-1.0/unet/quant_model_%d.safetensors' % (split_num)
save_quantization_model(model_path, output_path, linear_split_num=split_num, conv_split_num=32)
state_dict = load_quantization_model(output_path)
pipe.unet.load_state_dict(state_dict)
del state_dict
for i, prompt in enumerate(prompts):
generator = generator.manual_seed(seed)
image = pipe(prompt=prompt, generator=generator).images[0]
image.save(output_img_path + "img_quant_NF4(%d)_%02d.png" % (split_num, i))
結果:


torchのDynamic Quantization
torchの量子化の記事を読んだが自分のやってきたことはDynamic Quantizationという分野の結果に近い。
これは$y=W*x$のとき、モデル重み$W$のみをint化して入力$x$や出力$y$はfloat16のままである。
このDynamic QuantizationをSDXLじゃなくてStableDiffusionで試してみる。
確かにunetの重みをtorch.float16からtorch.qint8型に変換できているのが確認できるが、この時の推論速度はfp16から早くなっていない。しかもintをfloatに変換しているのか推論が始まるまでに時間が掛かる。
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.enable_model_cpu_offload()
unet_fp16 = pipe.unet
unet_int8 = torch.quantization.quantize_dynamic(unet_fp16, {torch.nn.Linear}, dtype=torch.qint8)
pipe.unet = unet_int8
print('fp16_weight=', unet_fp16.time_embedding.linear_1.weight)
print('int8_weight=', unet_int8.time_embedding.linear_1.weight())
print('pipe_weight=', pipe.unet.time_embedding.linear_1.weight())
-------------------------------------------
fp16_weight= Parameter containing:
tensor([[-0.0025, 0.0008, 0.0041, ..., -0.0163, 0.0121, -0.0105],
[ 0.0007, -0.0001, 0.0060, ..., -0.0087, 0.0062, -0.0029],
[ 0.0025, -0.0033, 0.0018, ..., -0.0150, -0.0041, 0.0027],
...,
[-0.0047, -0.0016, 0.0041, ..., -0.0106, 0.0102, 0.0080],
[-0.0020, -0.0027, -0.0004, ..., 0.0086, 0.0011, 0.0030],
[-0.0026, 0.0061, 0.0078, ..., 0.0080, 0.0078, 0.0159]],
dtype=torch.float16, requires_grad=True)
int8_weight= tensor([[-0.0019, 0.0000, 0.0037, ..., -0.0168, 0.0112, -0.0112],
[ 0.0000, 0.0000, 0.0056, ..., -0.0093, 0.0056, -0.0037],
[ 0.0019, -0.0037, 0.0019, ..., -0.0149, -0.0037, 0.0019],
...,
[-0.0056, -0.0019, 0.0037, ..., -0.0112, 0.0093, 0.0075],
[-0.0019, -0.0019, 0.0000, ..., 0.0093, 0.0019, 0.0037],
[-0.0019, 0.0056, 0.0075, ..., 0.0075, 0.0075, 0.0168]],
size=(1280, 320), dtype=torch.qint8,
quantization_scheme=torch.per_tensor_affine, scale=0.0018650428391993046,
zero_point=0)
pipe_weight= tensor([[-0.0019, 0.0000, 0.0037, ..., -0.0168, 0.0112, -0.0112],
[ 0.0000, 0.0000, 0.0056, ..., -0.0093, 0.0056, -0.0037],
[ 0.0019, -0.0037, 0.0019, ..., -0.0149, -0.0037, 0.0019],
...,
[-0.0056, -0.0019, 0.0037, ..., -0.0112, 0.0093, 0.0075],
[-0.0019, -0.0019, 0.0000, ..., 0.0093, 0.0019, 0.0037],
[-0.0019, 0.0056, 0.0075, ..., 0.0075, 0.0075, 0.0168]],
size=(1280, 320), dtype=torch.qint8,
quantization_scheme=torch.per_tensor_affine, scale=0.0018650428391993046,
zero_point=0)
一方、$y=W*x$で$W$だけではなく$x$と$y$もint型に変換するのをStatic Quantizationという。
Unetの入口と出口でfloat16=>int、int=>float16に変換して、unet内部はint型で行うので高速化するのだろうか。拡散モデルであればunetが繰り返し(step数だけ)呼ばれるので途中のunetのfloat型への変換は省略できるかもしれないが、この場合代わりにCFGやsampling method(DPM++とか)が計算できないだろう。
まとめ
SDXLモデル容量を減らすコードを示した。
実用面では読み込み時間、Int型からfloat16型への変換時間が増え、全く実用的ではない。
モデルサイズが削減できるが、追加モデル変換読み込み時間>>Download時間なのでメリットはない。linearがNF2.81(7)でほぼ1/5のモデルサイズでも画像を書き出せるのが意外とはいえ、promptによっては劣化が目立つ。