Grad-CAMって何だろうと思ってKeras実装コードを調べてみました。
論文も読んでないし、数式も全く理解してませんが一応動作は追えたかなと思います。
Grad-CAM のコード
https://github.com/eclique/keras-gradcam
Grad-CAMの核心部分は下記です。今回の場合layer_name='block5_conv3'です。
途中にprint文を挟んでnp.arrayの形を確認しました。
def grad_cam(input_model, image, cls, layer_name):
y_c = input_model.output[0, cls]
conv_output = input_model.get_layer(layer_name).output
grads = K.gradients(y_c, conv_output)[0]
output, grads_val = K.function([input_model.input], [conv_output, grads])([image])
print('output.shape=', output.shape)
print('grads_val.shape=', grads_val.shape)
output, grads_val = output[0, :], grads_val[0, :, :, :]
weights = np.mean(grads_val, axis=(0, 1))
print('weights.shape=', weights.shape)
cam = np.dot(output, weights)
print('cam.shape=', cam.shape)
# Process CAM
cam = cv2.resize(cam, (W, H), cv2.INTER_LINEAR)
print('cam_new.shape=', cam.shape)
cam = np.maximum(cam, 0)
cam = cam / cam.max()
return cam
shapeの出力結果は以下のようになりました。
なるほど、modelからoutputとgrads_valを取り出して、grads_valをチャンネル毎に平均化してweightを求め(正解ラベル選択時の各チャンネルの寄与度)、それにoutputを掛けるだけ。追ってみるとそんなに難しくないですね。
output.shape= (1, 14, 14, 512)
grads_val.shape= (1, 14, 14, 512)
weights.shape= (512,)
cam.shape= (14, 14)
cam_new.shape= (224, 224)
model.summary() #modelはVGG16
--------------------------------------------------
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
:
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
:
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
Grad-CAMイメージ:
言葉だけで説明しても伝わりにくいと思いますのでイメージ図を書いてみます。
誤差逆伝搬の理解があやふやですが、勾配レイヤーの取り出しは多分こういうイメージかと思います。
勾配自体は学習時におけるモデル重みの更新量っていう理解です。
なぜgrads_valの平均がチャンネルの正解寄与度を求めれるのかは自分には分かっていません。
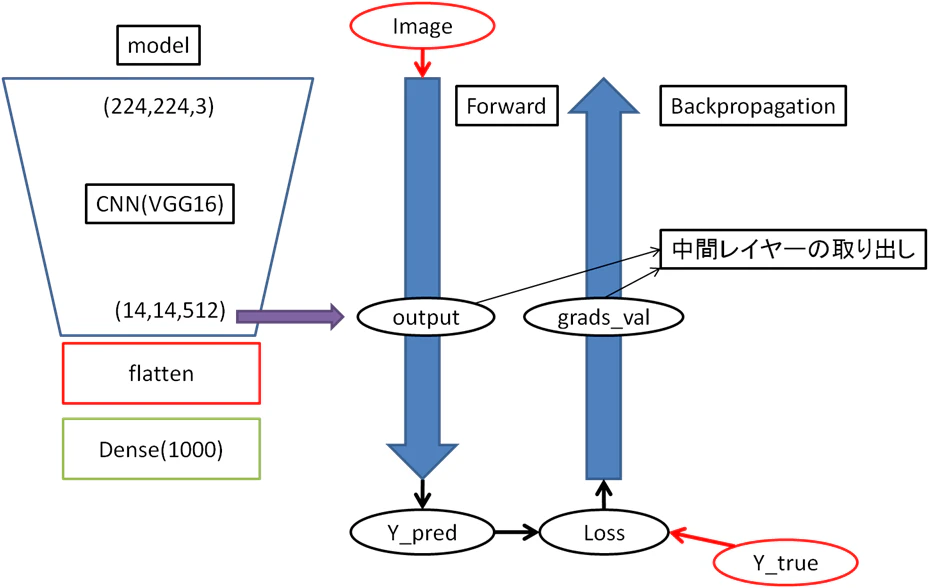
図1:中間レイヤーの取り出し
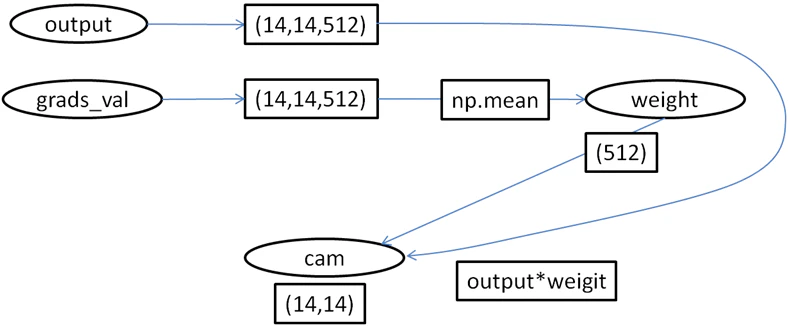
図2:中間レイヤーからcamの計算
grads_valの最大値の場合
grads_valのチャンネル毎平均って結局CNN層のglobal_average_pooling層ってことですよね。
もしそうなら、別にglobal_max_pooling層相当で計算しても計算できるんでしょうか。
#weights = np.mean(grads_val, axis=(0, 1))
weights = np.max(grads_val, axis=(0, 1))
(14,14)の縦横行列の内、チャンネル毎の最大値を取り出しました。
若干範囲が広がりますが、別にこれでも大丈夫そう。

 :左(mean)、右(max)
:左(mean)、右(max)
最大値チャンネルのみ表示させた場合:
outputのチャンネルとweightチャンネルの掛け算を計算させますが、weightの最も大きいチャンネルのみ表示させても問題ないのでは?と思った結果。
#cam = np.dot(output, weights)
cam = output[:,:,np.argmax(weights)]
weightsの最も大きいチャンネル結果を表示してます。従来結果よりは範囲が狭まった気がします。
もしかしたら犬の何らかの局所的な位置に反応している可能性はありますけれど、camの解像度が低いのでよく分かりません。
 :左(dot)、右(argmax)
:左(dot)、右(argmax)
camの解像度
ところでGrad-CAMの解像度って今回VGG16の場合(14,14)で、入力画像サイズ(224,224)に比べ割と低い印象を持ちました。(こんなものでしょうか?)
試しにlayer_name='block5_conv3'をlayer_name='block4_conv3'にした場合、camの解像度自体は(28,28)に上がりましたが、特徴量の場所表示は上手く行かないようです。
 :左('block5_conv3')、右('block4_conv3')
:左('block5_conv3')、右('block4_conv3')
XceptionやResnetなんかは入力画像サイズ(224,224)で全結合前が(7,7)なので解像度はさらに悪くなります。かと言ってモデルのpooling層を減らせば、分類精度が下がるでしょうし。どうすればいいんでしょう。
ReLUはどこに消えた?
論文の図を見るとcamマップの出力前にReLUが入ってます。
(14,14)のcamデータには当然マイナスの値も含んでいますが、どこに行ったんでしょうか。
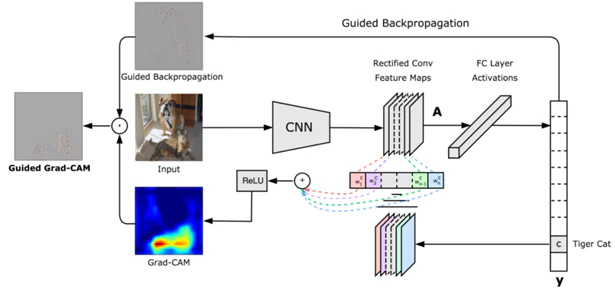
調べたら実装コードのnp.maximumがReLU相当でした。これでcamのマイナスの値には代わりにゼロが入るようになります。
なお、試しにnp.maximumとcv2.resizeの順番を入れ替えてみましたが、特に違いはないようです。
(ReLU=>resizeの順の方がcamのマイナス値の影響を除けるので良いのでは?と思いますが)
cam = np.maximum(cam, 0)
cam = cv2.resize(cam, (W, H), cv2.INTER_LINEAR)
 :左(resize=>ReLU)、右(ReLU=>resize)
:左(resize=>ReLU)、右(ReLU=>resize)
わざと1点だけ大きなマイナスを入れた場合、resize=>ReLUだと回りの点も影響を受けてしまいました。
cam[2,6] = -1000
cam = np.maximum(cam, 0)
cam = cv2.resize(cam, (W, H), cv2.INTER_LINEAR)

 :左(resize=>ReLU)、右(ReLU=>resize)
:左(resize=>ReLU)、右(ReLU=>resize)