はじめに
畳み込みを使ったCNNは白黒の二次元画像の特徴量を抽出するのが比較的得意です。白黒画像といえばQRコードが挙げられるのでこのQRコードの値をCNNで読み込めるかどうかを試してみます。
本当は白黒のどのビットがどの値かというのはルールベースで読み取れますし、畳み込みを使わないNNでも充分であるわけですが、ここではあえてCNNを使ってみます。
QRコードのあれこれ
QRコードのversionはQRコードのサイズと自ら含むことのできる文字数に依存します。
例えばversion=1では21×21のサイズで下記のように"www.wikipedia.org" と17文字の文字列を含むことができます。E1~E7はエラー補正なので読み取りは必須ではありません。つまり、この場合は各文字は8bitですから計136bitの値を確認すればルールベースでもこのサイズで何が書いてあるかは読めるわけです。
とりあえずこの最小QRコード21×21に書かれた数字を読むことを目的とします。
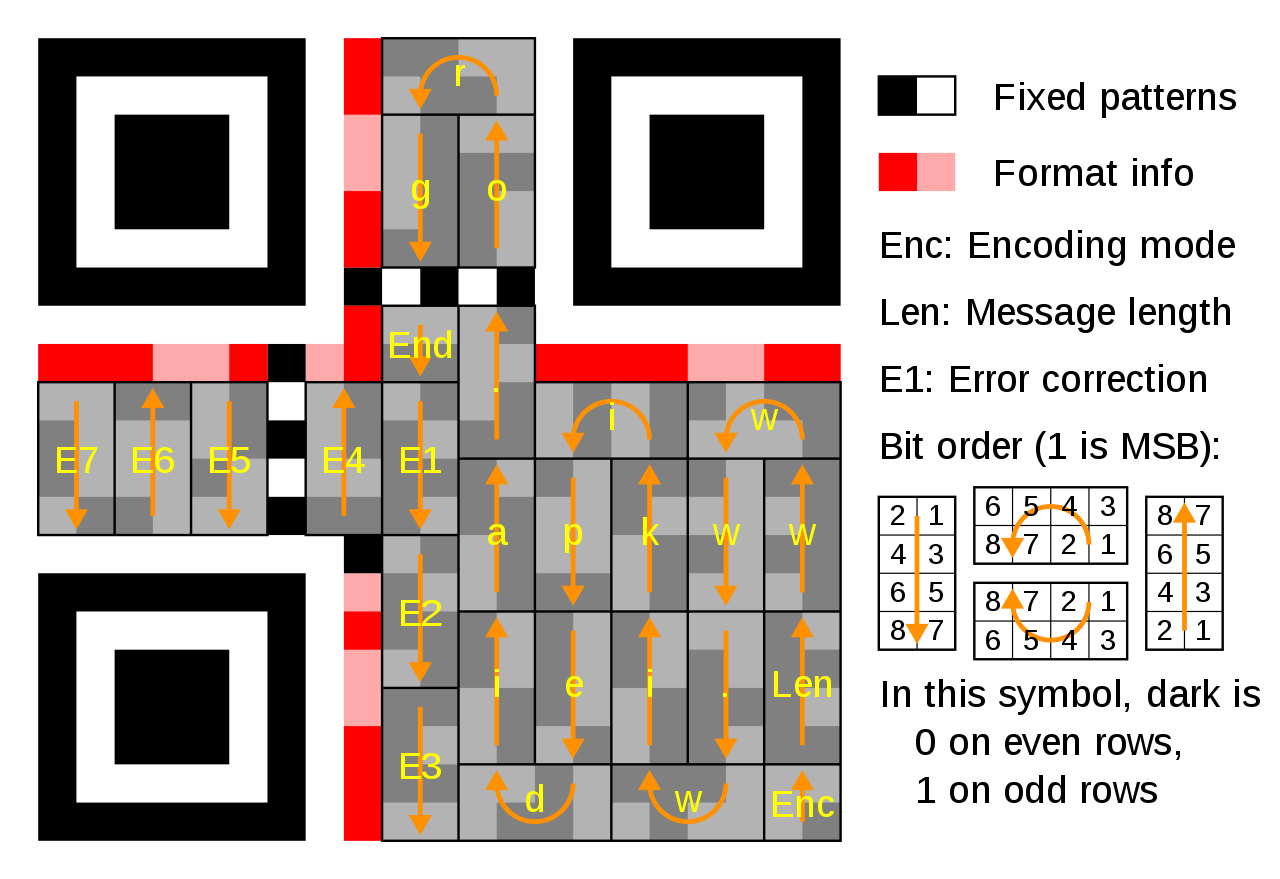
コード
Kerasで下記のように書きました。
6桁の数字を文字列になおして最小サイズのQRコードを40000個作成して学習とテストデータとしました。
また、本来のCNNならpoolingを使って画像サイズを半分にしていくべきかも知れませんが、今回の場合は入力サイズが21×21と小さいのでconv2dのみで畳み込み部分を構成しています。
import qrcode
import numpy as np
import random
from keras.utils import np_utils
from keras.layers import Input, Conv2D, MaxPooling2D, AveragePooling2D, BatchNormalization, Concatenate
from keras.models import Model
batch_size = 128
num_classes = 10
epochs = 30
X, Y = [], []
sample_list = random.sample(range(10**6), k=40000)
for i in sample_list:
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_H,
box_size=1, border=0 )
qr.add_data('%06d' % (i))
qr.make()
img = qr.make_image()
X.append(np.asarray(img))
Y.append([int(d) for d in format(i, '06d')])
X = np.reshape(np.asarray(X),(-1,21,21,1))/1.0
Y = np.reshape(np_utils.to_categorical(np.asarray(Y)), (-1,1,6,10))
print(X.shape)
print(Y.shape)
inputs = Input((21,21,1))
x = Conv2D(256, (3,3), padding='same', activation='relu')(inputs)
x = BatchNormalization()(x)
x = Conv2D(256, (3,3), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(256, (3,3), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(256, (3,3), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(256, (3,3), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(512, (3,3), padding='same', activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(512, (3,3), padding='same', activation='relu')(x)
x = MaxPooling2D(pool_size=(21, 21))(x)
y = [Conv2D(10, (1,1), activation='softmax')(x) for i in range(6)]
y = Concatenate(axis=-2)(y)
model = Model(inputs=inputs, outputs=y)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
history = model.fit(X[:30000], Y[:30000], batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X[30000:], Y[30000:]))
model.save('qr_model.h5', include_optimizer=False)
ここで
y = [Conv2D(10, (1,1), activation='softmax')(x) for i in range(6)]
y = Concatenate(axis=-2)(y)
の部分は下記のように書いても良いです。
y1 = Conv2D(10, (1,1), activation='softmax')(x)
y2 = Conv2D(10, (1,1), activation='softmax')(x)
y3 = Conv2D(10, (1,1), activation='softmax')(x)
y4 = Conv2D(10, (1,1), activation='softmax')(x)
y5 = Conv2D(10, (1,1), activation='softmax')(x)
y6 = Conv2D(10, (1,1), activation='softmax')(x)
y = Concatenate(axis=-2)([y1,y2,y3,y4,y5,y6])
この時のコード実行結果は以下のようになりました。
(40000, 21, 21, 1)
(40000, 1, 6, 10)
...
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 21, 21, 1) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 21, 21, 256) 2560 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 21, 21, 256) 1024 conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 21, 21, 256) 590080 batch_normalization_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 21, 21, 256) 1024 conv2d_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 21, 21, 256) 590080 batch_normalization_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 21, 21, 256) 1024 conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 21, 21, 256) 590080 batch_normalization_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 21, 21, 256) 1024 conv2d_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 21, 21, 256) 590080 batch_normalization_4[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 21, 21, 256) 1024 conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 21, 21, 512) 1180160 batch_normalization_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 21, 21, 512) 2048 conv2d_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 21, 21, 512) 2359808 batch_normalization_6[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 1, 1, 512) 0 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 1, 1, 10) 5130 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 1, 1, 10) 5130 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 1, 1, 10) 5130 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 1, 1, 10) 5130 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 1, 1, 10) 5130 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 1, 1, 10) 5130 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 1, 6, 10) 0 conv2d_8[0][0]
conv2d_9[0][0]
conv2d_10[0][0]
conv2d_11[0][0]
conv2d_12[0][0]
conv2d_13[0][0]
==================================================================================================
Total params: 5,940,796
Trainable params: 5,937,212
Non-trainable params: 3,584
__________________________________________________________________________________________________
Train on 30000 samples, validate on 10000 samples
Epoch 1/30
30000/30000 [==============================] - 66s 2ms/step - loss: 2.7801 - acc: 0.1714 - val_loss: 2.3467 - val_acc: 0.2484
Epoch 2/30
30000/30000 [==============================] - 62s 2ms/step - loss: 1.8426 - acc: 0.3493 - val_loss: 1.6885 - val_acc: 0.3941
Epoch 3/30
30000/30000 [==============================] - 64s 2ms/step - loss: 1.4841 - acc: 0.4555 - val_loss: 1.4549 - val_acc: 0.4547
...
Epoch 28/30
30000/30000 [==============================] - 64s 2ms/step - loss: 0.0401 - acc: 0.9868 - val_loss: 0.3695 - val_acc: 0.9110
Epoch 29/30
30000/30000 [==============================] - 64s 2ms/step - loss: 0.0435 - acc: 0.9853 - val_loss: 0.3403 - val_acc: 0.9184
Epoch 30/30
30000/30000 [==============================] - 63s 2ms/step - loss: 0.0339 - acc: 0.9889 - val_loss: 0.3164 - val_acc: 0.9231
最終精度はacc: 0.9889,val_acc: 0.9231となりました。
epochやモデルは適当なので調整すれば精度はもう少し上がるでしょう。
テスト
検証コードとして下記のように書きます。
結果はQRコードのversion=1という21×21のかなり小さな限定された条件ですが、6桁の数字をある程度予測することが出来ました。
import qrcode
import numpy as np
import random
from keras.models import load_model
X, Y = [], []
sample_list = random.sample(range(10**6), k=10)
for i in sample_list:
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_H,
box_size=1, border=0 )
qr.add_data('%06d' % (i))
qr.make()
img = qr.make_image()
X.append(np.asarray(img))
Y.append(i)
X = np.reshape(np.asarray(X),(-1,21,21,1))/1.0
model = load_model('qr_model.h5')
Y_pred = model.predict(X)
Y_pred_list = []
for i in range(10):
Y_pred_value = 0
for j in range(6):
Y_pred_value += np.argmax(Y_pred[i,0,j])
Y_pred_value *= 10
Y_pred_list.append(Y_pred_value//10)
print(Y)
print(Y_pred_list)
[89127, 306184, 427806, 501649, 727976, 232504, 427216, 893062, 127368, 100207]
[89127, 306184, 427806, 501649, 727976, 234506, 431222, 893062, 127378, 100207]
場所の特徴量
一般にMaxPooling2Dでは画像内に特徴量が存在するかは分かりますが、その場所までは後続のレイヤーに伝わりません。CNNといえば画像内のどこかに犬や猫が含まれるといった分類問題に多く使われますが、一方で場所を特定する特徴量抽出が(flattenを使わず)可能なのかと思いましたが、出来ているようです。
これは短距離畳み込みではデータの値、長距離の畳み込みでは左上、右上、左下にある四角のFixed patternとの距離にてデータの場所の特徴量を抽出しているのかもしれません。
データの値(2,4か4,2の8bit)を読み取るだけならConv2dが2層(5,5相当)でも十分な筈ですが、実際にはConv2dが2層のモデルでは精度はそれほど出ませんでした(val_acc:0.5程度)。このためCNNでQRコードを読むなら長距離の畳み込みによる場所の特徴量抽出も必要かと思われます。
(もしくは手っ取り早くモデルにflattenを使った方がいいよって話かもしれませんが…)