はじめに
今回は、ChatGPTを使って、外部のデータを活用して「より正確な回答を提供できるAI」を作る方法を紹介します。このアイデアを思いついたきっかけは、先日、研究者、弁護士や公認会計士などの専門家の方と話していたときのことでした。その中で、ChatGPTなどの生成AIについて、いくつかの不満が出てきました。
- 専門分野の質問をすると、間違った答えが返ってくることがある
- 論文の執筆を目的に使おうとすると、見当違いの情報を提供される
- 存在しない書籍や論文を紹介されることがある
確かに、私自身もChatGPTにコードを作らせたときに、動かないコードや存在しないライブラリが含まれていた経験があります。こういった問題を解決するため、外部データを取り込んで「より正確な回答を提供するAI」を作ることを試みました。そこで活用したのが、RAG(検索拡張生成)という技術です。
RAGを使うと、生成AIは外部の情報を検索し、その情報を基に回答を生成します。通常の生成AIがもともと学習済みの情報から答えるのに対し、RAGでは最新の情報や特定の資料を直接参照するため、より正確な回答が期待できます。さらに、ChatGPT APIにもRAGを利用できる機能があることを知り、今回これを使って試してみることにしました。
RAG(検索拡張生成)とは?
RAG(検索拡張生成)は、外部の情報を検索し、その情報を元にAIが回答を生成する技術です。正式名称は英語で「Retrieval-Augmented Generation」です。通常のChatGPTは、入力された質問に対してその場で回答を生成しますが、RAGでは、質問に関連する外部データ(例えばドキュメントやデータ)を検索して、それを基に回答します。この方法を使うことで、単に学習データに頼るのではなく、特定の資料やデータを取り込み、より正確で信頼性の高い回答が可能になります。
ソースコード
今回使用したソースコードは下記のレポジトリにあります。ぜひ参考にしてみてください。
通常のChatGPT APIを使用する
ChatGPT APIを取得する
今回の開発に必要なChatGPT APIを使うには、OpenAIの公式サイトからAPIキーを取得する必要があります。以下のステップでAPIキーを取得できます。
1.OpenAI公式サイトにアクセスしてください。アカウントを事前に作成します。
2.「製品」を押下してから、「APIログイン」をクリックしてください。

3.「Dashboard」をクリックする
4.「API Keys」をクリック
5.「Create new secret key」をクリック
6.Nameを設定して、「Create secret key」をクリック
7.Secret keyが生成されるので、これをコピー。この際このキーは絶対に外部公開しないでください。
8.次は支払い設定です「your profile」から「Billing」をクリックしてください
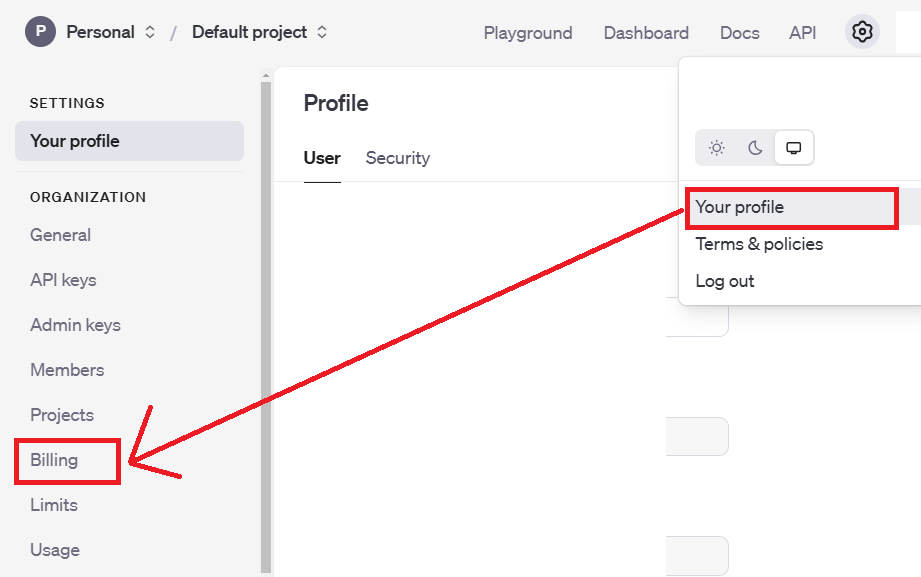
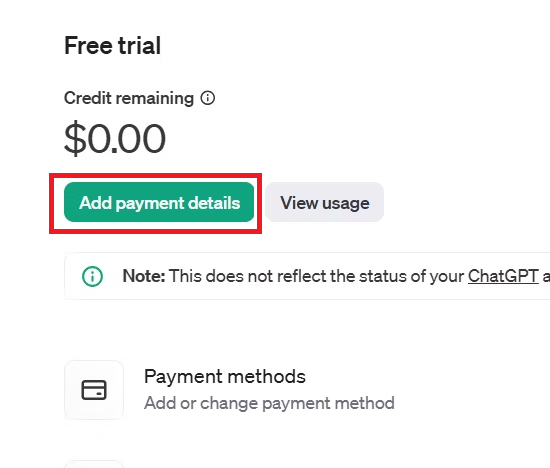
9.OpenAIに初めて登録すると、最初の3ヶ月間は5ドル分が無料で使える特典があります。ただ、私の場合はその期間を過ぎていたので、「Add payment details」をクリックして、支払い情報を登録し、課金しました。
通常のChatGPT APIを使ってみる
まずは、ChatGPT APIを使って簡単な質問に答えてもらいましょう。次のPythonコードを実行すれば、基本的なAPIの使い方がわかります。今回はライブラリを使用しない少し長めのコードを使っています。これは、他のプログラミング言語に移植する際にも役立つようにするためです。Pythonには便利なOpenAIのライブラリがたくさんあり、コードを短くしたり、効率化することも可能ですが、ここでは理解しやすさを優先しました。
import requests
import json
# API URL for OpenAI chat completion
api_url = "https://api.openai.com/v1/chat/completions"
# API key for authentication
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 適切なAPIキーを指定
# Request body
request_body = {
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "日本で一番高い山を教えて"}
],
"temperature": 0
}
# Headers for the request
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Sending the POST request
response = requests.post(api_url, headers=headers, data=json.dumps(request_body))
# Processing the response
if response.status_code == 200:
response_content = response.json()
answer = response_content['choices'][0]['message']['content']
print(answer) # Display the response content
else:
# Handle errors
print(f"Error: {response.status_code}")
print(response.text)
このスクリプトを実行すると、AIは「日本で一番高い山は何ですか?」という質問に対して応答を返します。たとえば、以下のような出力が得られます。
日本で一番高い山は富士山(ふじさん)です。富士山の標高は3,776メートルです。
ちなみにcurlコマンドで書くと下記のようになります。
curl -X POST "https://api.openai.com/v1/chat/completions" ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "Content-Type: application/json" ^
-d "{ \"model\": \"gpt-4o\", \"messages\": [ {\"role\": \"system\", \"content\": \"You are a helpful assistant.\"}, {\"role\": \"user\", \"content\": \"日本で一番高い山を教えて\"} ], \"temperature\": 0 }"
より正確な回答を提供できるAIを作成する
今回は、外部データを活用して「より正確な回答を提供するAI」を作成する方法を紹介します。ChatGPTを使って、このプロセスを以下の手順で進めていきます。
- ファイルのアップロード(データを用意して読み込む)
- アシスタントの生成(AIを設定する)
- スレッドの生成(会話の場を作る)
- スレッドに紐づけたメッセージの生成(質問と答えを準備する)
- ランを実行(AIに考えさせる)
- ランを取得(AIの動きをチェックする)
- メッセージのリストを取得(会話の内容を確認する)
以上の手順を踏むことで、ChatGPTを活用して、外部データを取り込み、より正確な回答を提供できるAIを作成することができます。
1.ファイルのアップロード(データを用意して読み込む)
今回はためしに、電子政府の総合窓口のe-Govポータルから刑法、民法、商法、日本国憲法のHTMLファイルをダウンロードし、それをChatGPTにアップロードしてみます。
import requests
# OpenAI APIのファイルアップロード用URL
api_url = "https://api.openai.com/v1/files"
# OpenAI APIキー
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 適切なAPIキーを指定
# アップロードするファイルのパス(4つのファイル: 刑法、民法、商法、日本国憲法)
file_paths = [
"C:\\Users\\user\\Downloads\\criminal_code_of_japan.html",
"C:\\Users\\user\\Downloads\\civil_code_of_japan.html",
"C:\\Users\\user\\Downloads\\commercial_code_of_japan.html",
"C:\\Users\\user\\Downloads\\japan_constitution_1947.html"
]
# ヘッダーの設定
headers = {
"Authorization": f"Bearer {api_key}"
}
# 取得したfile_idを格納する配列
file_ids = []
# 各ファイルをアップロード
for file_path in file_paths:
files = {
'purpose': (None, 'assistants'), # ファイルの目的を指定
'file': (open(file_path, 'rb')) # ファイルをバイナリモードで開く
}
# リクエストを送信
response = requests.post(api_url, headers=headers, files=files)
# レスポンスを処理
if response.status_code == 200:
# 成功した場合、file_idを配列に追加
response_content = response.json()
file_id = response_content.get('id', 'ID not found')
file_ids.append(file_id)
else:
# エラーが発生した場合の処理
print(f"エラー: {response.status_code} - ファイル: {file_path}")
print(response.text)
# すべてのfile_idを出力
print("取得したファイルID:")
for file_id in file_ids:
print(file_id)
このように出力されれば成功です。刑法、民法、商法、日本国憲法のそれぞれのファイルIDが出力されます。
取得したファイルID:
file-111111111111
file-222222222222
file-333333333333
file-444444444444
ちなみにcurlコマンドで書くと下記のようになります。
curl https://api.openai.com/v1/files ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-F purpose="assistants" ^
-F file="@C:\\Users\\user\\Downloads\\criminal_code_of_japan.html"
curl https://api.openai.com/v1/files ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-F purpose="assistants" ^
-F file="@C:\\Users\\user\\Downloads\\civil_code_of_japan.html"
curl https://api.openai.com/v1/files ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-F purpose="assistants" ^
-F file="@C:\\Users\\user\\Downloads\\commercial_code_of_japan.html"
curl https://api.openai.com/v1/files ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-F purpose="assistants" ^
-F file="@C:\\Users\\user\\Downloads\\japan_constitution_1947.html"
アップロードしたファイルのIDは、Pythonやcurlを使って確認できますが、個人的にはOpenAIのマイページで「Dashboard」から「Storage」をクリックする方法が一番簡単でわかりやすいと思います。
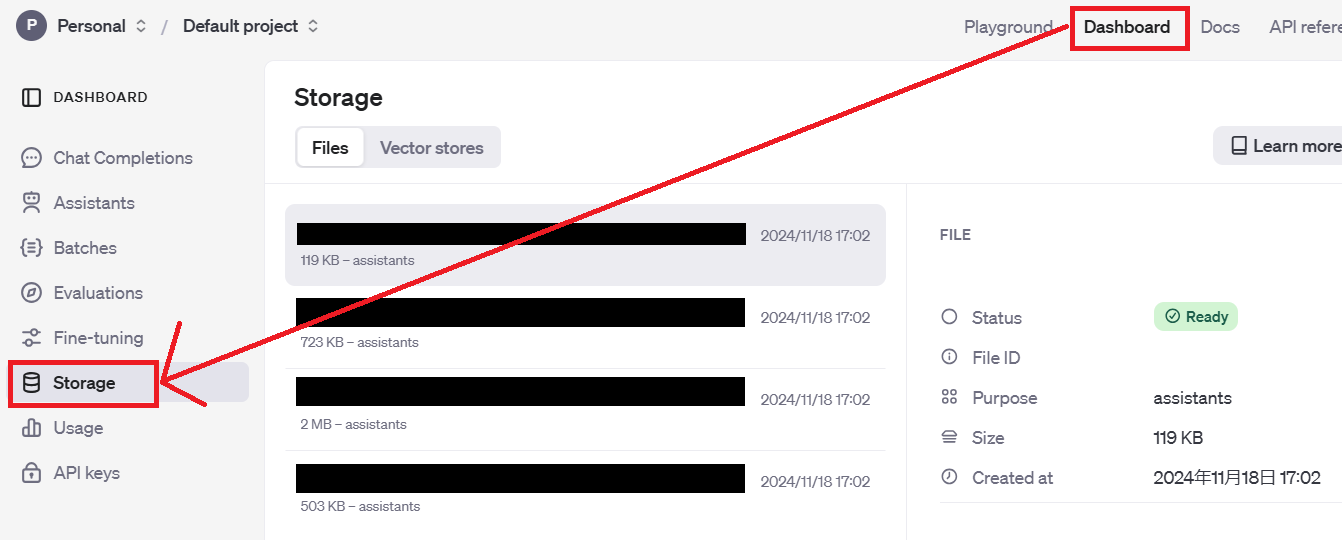
2.アシスタントの生成(AIを設定する)
アシスタントを作成してアシスタントIDを取得します。
import requests
import json
# OpenAI APIのエンドポイントURL
api_url = "https://api.openai.com/v1/assistants"
# OpenAI APIキー
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 適切なAPIキーを指定
# リクエストボディ(JSON形式)
request_body = {
"instructions": "You are a bot that provides legal information. Tell me the contents of the file you loaded.",
"name": "secretary",
"tools": [
{"type": "code_interpreter"}
],
"model": "gpt-4o",
"tool_resources": {
"code_interpreter": {
"file_ids": [
# ファイルのアップロード(データを用意して読み込む)で取得したファイルIDを代入
"file-111111111111",
"file-222222222222",
"file-333333333333",
"file-444444444444"
]
}
}
}
# ヘッダー設定
headers = {
"Content-Type": "application/json", # JSON形式を指定
"Authorization": f"Bearer {api_key}", # APIキーを設定
"OpenAI-Beta": "assistants=v2" # OpenAI APIのベータ機能指定
}
# POSTリクエストを送信
response = requests.post(api_url, headers=headers, data=json.dumps(request_body))
# レスポンスの確認
if response.status_code == 200:
# 成功した場合の処理
response_content = response.json()
# レスポンスから"id"を抽出して変数に代入
assistant_id = response_content.get("id", "ID not found")
print("Assistant ID:", assistant_id)
else:
# エラーが発生した場合の処理
print(f"エラー: {response.status_code}")
print(response.text)
このように出力されれば成功です。
Assistant ID: asst_wwwwwwwwwwwwwwww
なお下記の内容はファイルの内容ごとに指示を変更してください。今回は「あなたは法的な情報を提供するボットです。読み込んだファイルの内容を教えてください。」という意味の英文を書きました。
"instructions": "You are a bot that provides legal information. Tell me the contents of the file you loaded.",
ちなみにcurlコマンドで書くと下記のようになります。
curl "https://api.openai.com/v1/assistants" ^
-H "Content-Type: application/json" ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "OpenAI-Beta: assistants=v2" ^
-d "{ \"instructions\": \"You are a bot that provides legal information. Tell me the contents of the file you loaded.\", \"name\": \"secretary\", \"tools\": [{\"type\": \"code_interpreter\"}], \"model\": \"gpt-4o\", \"tool_resources\": {\"code_interpreter\": {\"file_ids\": [\"file-1111111111\", \"file-2222222222\", \"file-3333333\", \"file-4444444444\"]}} }"
3.スレッドの生成(会話の場を作る)
スレッドを作成してスレッドIDを取得します。
import requests
import json
# OpenAI API URL
api_url = "https://api.openai.com/v1/threads"
# OpenAI API key
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 実際のAPIキーを入れてください
# ヘッダーの設定
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
"OpenAI-Beta": "assistants=v2"
}
# リクエストボディ(空のJSONデータを送信)
data = {}
# POSTリクエストを送信
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# レスポンスの確認
if response.status_code == 200:
response_data = response.json() # レスポンス内容をJSONとして取得
# 'id' を取得して thread_id に代入
thread_id = response_data.get("id")
if thread_id:
print(f"Thread ID: {thread_id}") # 取得したIDを表示
else:
print("Thread ID not found in the response.")
else:
print(f"Error: {response.status_code}")
print(response.text)
このように出力されれば成功です。
Thread ID: thread_XXXXXXXXXXXXXXX
ちなみにcurlコマンドで書くと下記のようになります。
curl -X POST https://api.openai.com/v1/threads ^
-H "Content-Type: application/json" ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "OpenAI-Beta: assistants=v2" ^
-d "{}"
4.スレッドに紐づけたメッセージの生成(質問と答えを準備する)
スレッドに紐づけたメッセージの生成します。今回は「日本国憲法に定められている基本的人権の概要を書いて」という質問をします。
import requests
import json
# OpenAI API URL(スレッドIDを含む)
api_url = "https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/messages"
# OpenAI API key
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 実際のAPIキーを入れてください
# ヘッダーの設定
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
"OpenAI-Beta": "assistants=v2"
}
# リクエストボディ(メッセージの内容)
data = {
"role": "user",
"content": "日本国憲法に定められている基本的人権の概要を書いて"
}
# POSTリクエストを送信
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# レスポンスの確認
if response.status_code == 200:
print("Message sent successfully!")
print(response.json()) # レスポンス内容を表示
else:
print(f"Error: {response.status_code}")
print(response.text)
このように出力されれば成功です。
Message sent successfully!
{'id': 'msg_.........
ちなみにcurlコマンドで書くと下記のようになります。
curl -X POST https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/messages ^
-H "Content-Type: application/json" ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "OpenAI-Beta: assistants=v2" ^
-d "{ \"role\": \"user\", \"content\": \"日本国憲法に定められている基本的人権の概要を書いて\" }"
5.ランを実行(AIに考えさせる)
ランを実行します。
import requests
import json
# OpenAI API URL(スレッドIDとrunのエンドポイント)
api_url = "https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/runs"
# OpenAI API key
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 実際のAPIキーを入れてください
# ヘッダーの設定
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"OpenAI-Beta": "assistants=v2"
}
# リクエストボディ(assistant_idを含む)
data = {
"assistant_id": "{2.アシスタントの生成(AIを設定する)で取得したアシスタントID}" # 実際のassistant_idを指定
}
# POSTリクエストを送信
response = requests.post(api_url, headers=headers, data=json.dumps(data))
# レスポンスの確認
if response.status_code == 200:
response_data = response.json() # レスポンス内容をJSONとして取得
# 'id' を取得して run_id に代入
run_id = response_data.get("id")
if run_id:
print(f"Run ID: {run_id}") # 取得したIDを表示
else:
print("Run ID not found in the response.")
else:
print(f"Error: {response.status_code}")
print(response.text)
このように出力されれば成功です。
Run ID: run_cccccccccccccc
ちなみにcurlコマンドで書くと下記のようになります。
curl -X POST https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/runs ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "Content-Type: application/json" ^
-H "OpenAI-Beta: assistants=v2" ^
-d "{\"assistant_id\": \"{2.アシスタントの生成(AIを設定する)で取得したアシスタントID}\"}"
6.ランを取得(AIの動きをチェックする)
ランを取得します。
import requests
# OpenAI API URL(スレッドIDとランIDを指定)
api_url = f"https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/runs/{5.ランを実行(AIに考えさせる)で取得したランID}"
# OpenAI API key
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 実際のAPIキーを入れてください
# ヘッダーの設定
headers = {
"Authorization": f"Bearer {api_key}",
"OpenAI-Beta": "assistants=v2"
}
# GETリクエストを送信
response = requests.get(api_url, headers=headers)
# レスポンスの確認
if response.status_code == 200:
# statusの値のみを取得して表示
response_content = response.json()
status_value = response_content.get("status", "Status not found")
print(f"Status: {status_value}")
else:
print(f"Error: {response.status_code}")
print(response.text)
このコードを実行してcompleted(完了)と表示されれば成功です。他のステータスとして、queued(キュー中)、in_progress(進行中)、requires_action(アクションが必要)、cancelling(キャンセル中)などがありますが、処理が完了するまでcompleted(完了)を待ちましょう。
Status: completed
ちなみにcurlコマンドで書くと下記のようになります。
curl -X GET https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/runs/{5.ランを実行(AIに考えさせる)で取得したランID} ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "OpenAI-Beta: assistants=v2"
7.メッセージのリストを取得(会話の内容を確認する)
メッセージのリストを取得します。
import requests
# OpenAI API URL
api_url = f"https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得したスレッドID}/messages"
# OpenAI API key
api_key = "{「通常のChatGPT APIを使用する」で取得したAPI}" # 実際のAPIキーを指定してください
# ヘッダーの設定
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
"OpenAI-Beta": "assistants=v2"
}
# GETリクエストを送信
response = requests.get(api_url, headers=headers)
# レスポンスの確認
if response.status_code == 200:
data = response.json()
# 必要なデータをすべて出力する
if data.get('data'):
for message in data['data']:
# 各メッセージのコンテンツを取得
content_list = message.get('content', [])
if content_list:
value = content_list[0].get('text', {}).get('value', '内容が見つかりません')
print(f"回答: {value}")
print(f"--------------------")
else:
print("Response structure does not match the expected format.")
else:
print("Response structure does not match the expected format.")
else:
print(f"Error: {response.status_code}")
print(response.text)
このように出力されれば成功です。
回答: 4番目のファイルもHTML形式で、「刑法」というタイトルがついています。これは日本の刑法に関する情報が含まれている可能性があります。これらのファイルから特定の法律情報を抽出することができますが、具体的な法律情報の抽出を行う場合、詳細にファイルの内容を解析する必要があります。
これらのファイルについて、特定の情報が必要であればお知らせください。それに基づいて、詳細な内容を解析したり、情報を提供いたします。
--------------------
回答: 3番目のファイルもHTML形式で、タイトルに「日本国憲法」と記載されています。このファイルには、日本国憲法に関する情報が記載されていることでしょう。
次に、最後の4番目のファイルを確認して内容を把握してみましょう。
--------------------
回答: 2番目のファイルもHTML形式で、タイトルに「商法」と記載されています。これは日本の商法に関連する情報が含まれている可能性があります。特定のテキストを解析して、多くの場合、法律の詳細を抽出することが可能です。
次に3番目のファイルを確認してみましょう。
--------------------
回答: 最初のファイルはHTML形式で書かれているようです。内容に「民法」というタイトルが含まれており、日本法に関する情報が記載されている可能性があります。このHTMLファイルから特定のテキストを抽 出したり、詳細な法律情報を提供することもできます。
続いて次のファイルを確認し、その内容を把握してみます。
--------------------
回答: ファイルを確認して重要な内容や概要を提供することができます。次に、ユーザーが興味を持ちそうな特定のファイルの概要や情報を提供します。それでは、最初のファイルの内容を見てみましょう。
--------------------
回答: 日本国憲法における基本的人権は、人間が本来的に持っている権利であり、憲法により保障されています。以下に日本国憲法で定められている基本的人権の主な内容をまとめます:
1. **個人の尊重(第13条)**: 個人の尊厳を重んじ、その幸福を追求する権利が保障されています。
2. **平等権(第14条)**: 法の下における平等が定められており、あらゆる差別を排除することが求められています。
3. **自由権**:
- **思想・良心の自由(第19条)**: 個人の思想および良心の自由が保障されています。
- **信教の自由(第20条)**: 宗教の選択や信仰の自由が認められています。
- **表現の自由(第21条)**: 集会、結社、言論、出版などの自由が確保されています。
4. **身体の自由**:
- **居住・移転および職業選択の自由(第22条)**: 自由に居住地を選び、職業を選ぶ権利が保障されています。
- **奴隷的拘束および苦役からの自由(第18条)**: 奴隷的な拘束を受けない自由と、身体の自由が保護されています。
- **刑事補償と手続の保障(第31条-第40条)**: 主に適正手続きの保障や無罪推定の原則、強制の排除が含まれます。
5. **社会権**:
- **生存権(第25条)**: 健康で文化的な最低限度の生活を営む権利が保障されています。
- **教育を受ける権利(第26条)**: すべての国民に教育を受ける権利が保障されています。
- **勤労の権利(第27条)**: 働く権利と、労働条件の整備が保障されています。
6. **請求権(第32条-第34条)**: 法律上の救済を求める権利や、公正な裁判を受ける権利が含まれます。
7. **参政権(第15条)**: 政治に参加する権利、投票権が保障されています。
これらの権利は日本国憲法の主要な特徴であり、現代日本の法制度と社会の基本的な構成要素です。基本的人権は、公共の福祉に関する制約がある場合もありますが、原則として国や行政によって侵害されては ならないとされています。
--------------------
回答: 日本国憲法に定められている基本的人権の概要を書いて
--------------------
ちなみに「基本的人権」については日本国憲法に書かれています。今回、刑法、民法、商法、日本国憲法の4つのファイルをアップロードしたので、それぞれに基づいた回答が可能になります。しかし、もし日本国憲法だけをアップロードした場合、'data'の0番目の情報を取得すれば問題ありません。また、すべての法律と日本国憲法を1つのファイルにまとめても同じように処理できます。
簡単に言うと、次のコードを使用すると、すべてのデータを出力できます。
# 必要なデータをすべて出力する
if data.get('data'):
for message in data['data']:
# 各メッセージのコンテンツを取得
content_list = message.get('content', [])
if content_list:
value = content_list[0].get('text', {}).get('value', '内容が見つかりません')
print(f"回答: {value}")
print(f"--------------------")
特定のデータだけを取り出したい場合は、次のようにコードを変更することで対応できます。(この例では、'data'の0番目の要素を取り出しています。)
# 必要なデータを取得(安全な取り出しを行う)
if data.get('data') and data['data'][0].get('content'):
answer = data['data'][0]['content'][0]['text']['value']
print(f"回答は: {answer}")
ちなみにcurlコマンドで書くと下記のようになります。
curl -X GET https://api.openai.com/v1/threads/{3.スレッドの生成(会話の場を作る)で取得した}スレッドID/messages ^
-H "Content-Type: application/json" ^
-H "Authorization: Bearer {「通常のChatGPT APIを使用する」で取得したAPI}" ^
-H "OpenAI-Beta: assistants=v2"
(おまけ)連続した質問の進め方
もし、今回「日本国憲法に定められている基本的人権の概要を書いて」という質問に続けて別の質問をしたい場合は、以下の手順を踏むだけで問題ありません。
4.スレッドに紐づけたメッセージの生成(質問と答えを準備する)
5.ランを実行(AIに考えさせる)
6.ランを取得(AIの動きをチェックする)
7.メッセージのリストを取得(会話の内容を確認する)
これで、連続した会話をスムーズに進めることができます。
まとめ
今回、外部のデータを活用して「より正確な回答を提供できるAI」を作る方法を紹介しましたが、いかがでしたでしょうか?特にRAG(検索拡張生成)について、理解が深まりましたか? RAGを使うと、AIが外部の情報を検索して、その情報を基により精度の高い回答を提供できることが分かるかと思います。
今回使用したAPIはOpenAIのBeta版で、まだ開発段階です。そのため、今後APIの設定方法やURLが変更される可能性があります。もし変更があれば、適宜修正が必要になるかもしれませんので、その点をご了承ください。
今回は法律や憲法に関するデータを読み込みましたが、他にも活用できるデータはたくさんあります。たとえば、裁判の判例や、社内ドキュメント、古文書、歴史書、膨大な統計データ、書籍、議事録、株価情報なども活用できます。この技術を使えば、データをどんどん取り込み、より多くの分野で活用することができます。理系や文系を問わず幅広い分野で応用できる技術ですし、もしかしたら、私が思いつかなかった新しい活用方法が生まれるかもしれません。生成AI技術は日々進化しているので、今後はもっと簡単に、より正確に使えるものが登場するかもしれません。
なお、今回はPythonでコードを書きましたが、このコードでは必要な部分だけを取り出して変数に代入したり出力したりしています。また、今回はできるだけライブラリを使わずに書いたため、PHPやJavaなど、他のプログラミング言語でも同じように実装できると思います。一方、curlを使った方法では、すべての情報が出力されます。この出力には重要な情報が含まれていることがあるので、時間があるときに再度確認してみると良いかもしれません。
それでは、また。
参考文献
RAG | 用語解説 | 野村総合研究所(NRI)
OpenAIのAssistants APIでRAG(検索拡張生成)を実装してみた #Python - Qiita
API Reference - OpenAI API