"Word Mover's Embedding: From Word2Vec to Document Embedding"を読むために必要なところだけまとめる。
情報
- From Word Embeddings To Document Distances
- この記事の画像は全て上記論文から転載した。
Abstract
- テキスト間の距離を表すWord Mover's Distance(WMD)を定義する。
- WMDとKNNを組み合わせて文書分類のタスクに取り組む
Introduction
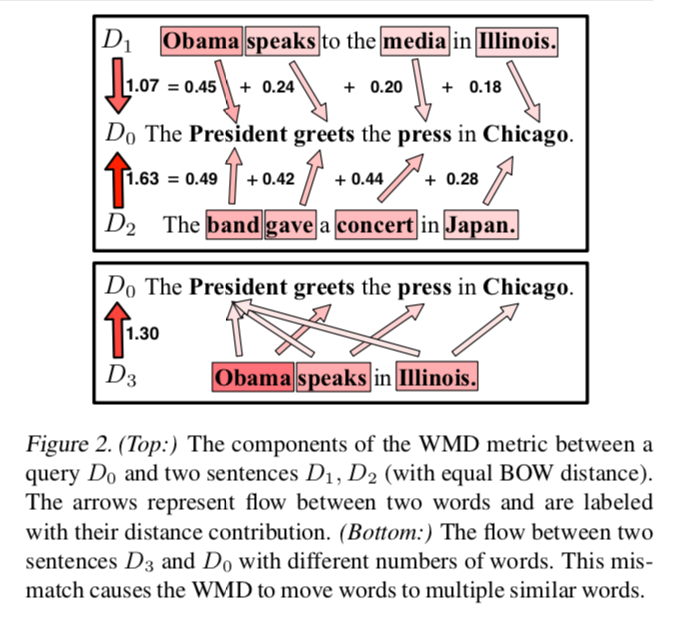
- 既存の方法(BOW)では下記2つの文は似ているにもかかわらず似ていると判定できない
- Obama speaks to the media in Illinois.
- The President greets the press in Chicago.
- 他にも既存の方法として、TFIDF/BOW、LSI、LDAなどがある。
Word Mover's Distance
Notation
- word2vecによるembedding: $X \in R^{d \times n}$
- ボキャブラリーサイズ: $n$
- embeddingの次元: $d$
- normalized bag-of-words (nBOW): $d \in R^n$
nBOW representation.
- nBOWだとintroductionで触れたように意味的には近くても同じ単語を使われていない文章は距離が遠くなるという欠点がある。
Word travel cost.
- word2vecによるembeddingで単語間の距離を定義する。
- 単語$i$と$j$の距離を$c(i, j)=|| x_i - x_j||_2$ とする。
Document distance
- 文書$d$の単語$i$と文書$d'$の単語$j$の移動コストを$T_{ij} \geq 0$とする。
- $\sum_j T_{ij} = d_i$
- $\sum_i T_{ij} = d'_j$
- 文書間の距離を$\sum_{i,j} T_{ij}c(ij)$と定める。
- $T_ij$は下記の最小化問題と解くことで求める。
Transportation problem.
$$\min_{T \geq 0} \sum_{i,j=1}^n T_{ij} c(i, j)$$
subject to:
$$\sum_j T_{ij} = d_i$$
$$\sum_i T_{ij} = d'_j$$
- 実際にこの問題を特には計算コストが非常に高いのでコストが低い問題に置き換える(精度は探る)
例
終わり
- "Word Mover's Embedding: From Word2Vec to Document Embedding"を読むために必要なところだけで良いので一旦ここまで。