"Graph Convolutional Neural Networks for Web-Scale Recommender Systems"を理解するために読む。
情報
- Inductive Representation Learning on Large Graphs
- この記事の画像は上記論文からの転載。
簡単にまとめると
- GraphへのDLのアプローチの多くは、学習時にすべてのノードの情報が必要としており、学習時に未知のノードへの推論の適用はできないものが多い。
- この論文で紹介するGraphSAGEは未知のノードのembeddingを計算することができる。
- 学習時に各ノードのembeddingを学習するのではなく、近傍の情報からembeddingを計算するためのaggregate関数を学習する。
1 Introduction
- グラフ構造は推薦システムや多くのタスクで有用であることが示されてきた。
- しかし、既存の多くのアルゴリズムは学習時に全てのグラフ構造を必要としており、未知のnodeに対して推論することはできない。
- この論文で提案するGraphSAGEは個々のノードに対するembeddingを学習するのではなく、ノードの近傍から特徴を集約する関数群を学習させる。
- 教師なし学習としてembeddingを学習させることもできるし、特定の課題への教師あり学習をさせることもできる。
2 Related work
Factorization-based embedding approaches
- これらの方法は新しいノードに対するembeddingを計算するのコストが高いものが多い。
Supervised learning over graphs
- 既存の方法はグラフやサブグラフの分類を試みているが、この論文では個別のノードの分類を考える。
Graph convolutional networks
- 既存の多くの方法ではスケールしない。大規模なグラフには適用できない。全体のLaplacianを必要とすることが多い。
3 Proposed method: GraphSAGE
3.1 Embedding generation (i.e., forward propagation) algorithm

- embeddingを計算するアルゴリズムについて説明する。
- 上記のアルゴリズムで使われている $\text{AGGREGATE}_k$ と $W^k$ は学習済みとする。
- AGGREGATE関数はノードの近傍から情報を集約する。
- Wはモデルの異なる層の情報を伝搬するために使われる。
- このアルゴリズムでは、イテレーションを繰り返すことで、各ノードは近傍のノードの情報を集約していく。さらに各ノードは近傍より遠いノードの情報も得ていくことになる。
- 入力として、グラフ構造とノードの特徴量が与える。
- 学習時に入力とするのはグラフ構造の一部であり、推論時に新しいノードも含んだグラフ全体を与える。
Relation to the Weisfeiler-Lehman Isomorphism Test
Neighborhood definition
- 一定のサイズの近傍を用いる。
- 近傍はイテレーションごとにサンプリングする。
- $N(v)$ は $\{u \in V : (u, v) \in E \}$から一様に選択する。
3.2 Learning the parameters of GraphSAGE
- 近いノード同士は似たrepresentationを持つように、遠いノード同士は異なるrepresentationを持つようになるように損失関数を定める。
$$ J_g(z_u) = - \log(\sigma(z_u \cdot z_v)) - Q E_{v_n \sim P_n(v)}\log(\sigma(-z_u \cdot z_{v_n}))$$
- 特定のタスクのみでrepresentationを利用する場合、上記の教師なしの損失関数を置き換えることもできる。またcross-entropy lossなどを使うこともできる。
3.3 Aggregator Architectures
- 文章や画像などと異なり、ノードの近傍は自然な順序を持たない。
- Aggregate関数は順序に依存せず対象であることが望ましい。
Mean aggregator
$$h_v^k \leftarrow \sigma(W \cdot \text{MEAN}(\{h_v^{k-1}\} \cup \{h_u^{k-1}, \forall u \in N(v)\}))$$
LSTM aggregator
- LSTMはsymmetricではないので、ランダムな順序のノードに適用する。
Pooling aggregator
$$\text{AGGREGATE}k^{\text{pool}} = \max( \{ \sigma(W{pool} h_{u_i}^k + b), \forall u_i \in N(v) \} )$$
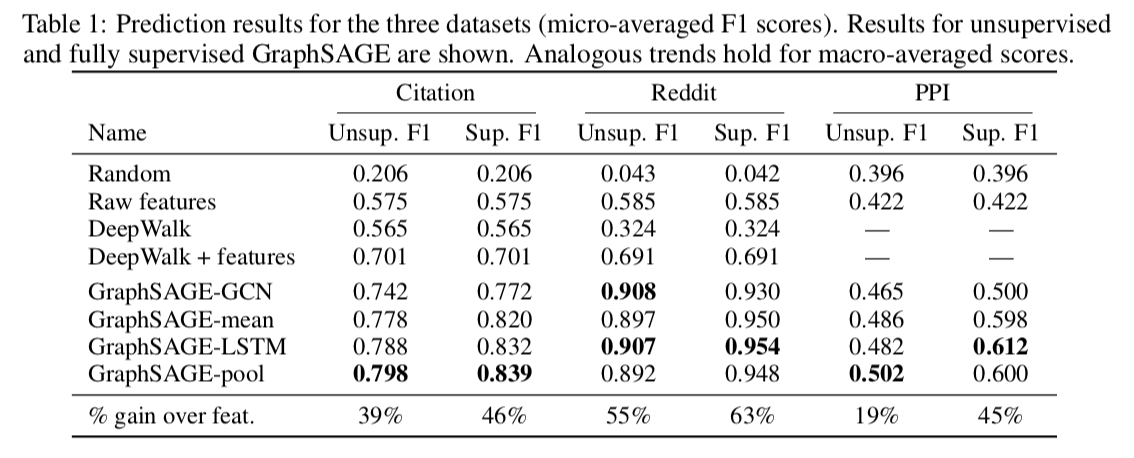
Experiments
Experimental set-up
- 活性化関数としてRELUを使う。
- $K=2$
- 近傍のサンプルサイズ$S_1=25$、$S_2=10$
- コードなどは下記で公開されている
4.1 Inductive learning on evolving graphs: Citation and Reddit data
Citation data
- 2000-2004年のデータを使って学習し、2005年のデータでテストを行った。
- Arora et al のアプローチで300次元のword2vecを使ってアブストラクトを処理し、各ノードの特徴量とした。