情報
- Graph Convolutional Neural Networks for Web-Scale Recommender Systems
- この記事の画像は上記論文からの転載。
簡単にまとめると
- Pixieの方法を発展させたもの。
- 大規模なグラフに適用できるように、GPU利用を最大化するためのminibatchを構成するためにprocuder-consumerアーキテクチャを開発した。
Abstract
- 近年graph構造へのDNNが推薦システムでSOTAを達成している。
- しかし、大規模データへの適用には課題がある。
- この論文では、Pinterestで使われている推薦システムを説明する。
- 新しいアルゴリズムのPinSageはnodeのembeddingを得るために効果的なrandom walkとgraph convolutionを組み合わせる。
- これで得られるnodeのembeddingはグラフ構造とnodeの特徴量を統合したものになっている。
- これまでのGCNに対するアプローチと比較して、今回の方法は効率的なrandom walkに基づいている。
- convolutionを組み立てる
- 新しいtraining方法を設計する。
- 汎化性能や収束性を改善するためにharder-and-harder training examplesに基づいている。
- Pinterestでは、PinSageを下記のデータ量で訓練している。
- 75億の例
- 30億のノード
- 180億のエッジ
1. Introduction
- deep modelを使って得られるrepresentationは協調フィルタリングのような伝統的な方法を補完する、もしくは置き換えるために使用でき得る。
- また、representationは様々なタスクで再利用できる。
- GCNのコアなアイデアはneural networkを使って、局所グラフ近傍から特徴量を繰り返しaggregateする方法を学ぶことである。
- 主な挑戦は、trainingだけでなくinferenceにおいてもスケールさせることである。
- 既存の方法ではスケールさせることは困難である。なぜなら、多くの前提が崩れてしまうから。
- 例えば、full graph Laplacianが必要となる。
Present work
-
PinSageは、GCNのスケーラビリティを根本的に改善するために下記3つの工夫をした。
- On-the-fly convolution
- 既存のGCNでは、full graph Laplacianに特徴量行列を掛ける。
- PinSageでは、nodeの近傍をサンプリングし、サンプリングされた近傍から動的にcomputation graphを構築することにより効果的にlocalized convolutionを実行する。
- Producer-consumer minibatch construction
- モデル訓練時にGPU利用を最大化するminibatchを構成するためにprocuder-consumerアーキテクチャを開発した。
- Efficient MapReduce inference
- 数十億のembeddingを生成するために訓練済みモデルを分配できる効果的なMapReduceパイプラインを設計した。
- On-the-fly convolution
-
また学習テクニックやアルゴリズムの改善を行うことにより、後続の推薦タスクのパフォーマンスの大幅な改善を行った。
- Construction convolutions via random walks
- ノードの近傍全体で計算するのではなく、short random walkを使ってサンプリングすることにより計算量の削減とimportance scoreを持つようになった。
- Importance pooling
- aggregation時に上記のrandom walkで得たimportance scoreを使って特徴量を重み付けすることにより、パフォーマンスが46%改善した。
- Curriculum training
- カリキュラム学習を設計し、パフォーマンスを21%改善した。
- Construction convolutions via random walks
2. Related work
- node2vecやDeepWalkがここでは使えない理由として、
- それらは教師なし学習である。
- nodeの特徴量を活用することができない。
- embeddingを直接学習するので、グラフのサイズに線形に比例してパラメータが増加する。
3 Method
- ノードの局所的な近傍から特徴量を集約する複数のconvolutionを適用する。
- これらのconvolutionのパラメータは全てのノードで共有されるのでグラフのサイズとモデルの複雑さは比例しない。
3.1 Problem Setup
- $I$をアイテムの集合、$C$をユーザーのコンテキストの集合
- $u \in I$に対して実数値の属性$x_u \in R^d$を持つ。
- ゴールは2部グラフの構造と属性の両方を使って高品質のembeddingを生成することである。
- notationをシンプルにするために$V = I \cup C$とする。
3.2 Model Architecture
Forward propagation algorithm
- ノードの特徴量やグラフ構造を取り入れたembedding $z_u$ $(u \in V)$ を生成することを考える。

- Line 2でconcatするほうが平均を取るよりも精度がよかった。
- Line 3での正規化でモデルがより安定した。
Importance-based neighborhoods
- PinSAGEで重要なイノベーションはノードの近傍$N(u)$の定義の仕方である。
- importance-based neighborhoodを定義する。
- ノード$u$の近傍は$u$に最も影響のある$T$個のノードと定義する。
- 具体的には、$u$からスタートしたrandom walkをシミュレートし、$L_1$正則化された訪問回数を計算する。
- 訪問回数の上位$T$個を近傍と定義する。
- 詳しくは Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time
- この方法の利点は、
- 固定数のノードを選ぶのでメモリー使用量を管理できる。
- Aggregate時にノードの重要度を考慮することができる。
- Algorithm 1で$\gamma$を加重平均として実装する。ここでウエイトは$L_1$正則化された訪問回数を使う。
Stacking convolutions

3.3 Model Training
- ラベル付けされたアイテムのペアの集合を$L$とする。
- $(q, i) \in L$のとき、クエリアイテム$q$アイテム$i$は良いリコメンデーション候補である。
- 学習のゴールは$(q, i) \in L$のembeddingが互いに近くなることである。
Loss function
- Max-margin ranking lossを使って学習させる。
- 正例の内積は大きくし、負例の内積は事前に定義したマージン以上に正例の内積よりも小さくしたい。
- 一つのペア($(q, i) \in L$)に対する損失関数は下記のようになる。
$$J_G(z_q, z_i) = E_{n_k \sim P_n(q)} \max(0, z_q \cdot z_{n_k} - z_q \cdot z_i + \Delta)$$
Sampling negative items
- 学習コストを減らすために、全体の負例の数を500に限定し、ミニバッチの学習データ全体で共有する。
- この方法は各ノードに対して各々に負例のサンプルを作るのに比べて大幅に計算コストを削減できる。
- また、実験的に両者に有意な差はない。
- 完全に一様に負例をサンプリングすると$q$と殆ど関係ないノードばかりになるため工夫が必要である。
- この課題を解決するために各正例に対して、hard negative exmpleを追加する。
- つまり、ある程度$q$に関連しているアイテムであるが、アイテム$i$には関連したていないものを選ぶ。
- 詳しくは、"Distributed Representations of Words and Phrases and their Compositionality"
- カリキュラム学習を導入する。最初のエポックではhard negative itemを使わずに学習する。
- $n$回目のエポックで$n-1$個のhard negative itemを各アイテムに対して追加する。
MapReduceやGPUの話は飛ばす。
- そのうち追記する。
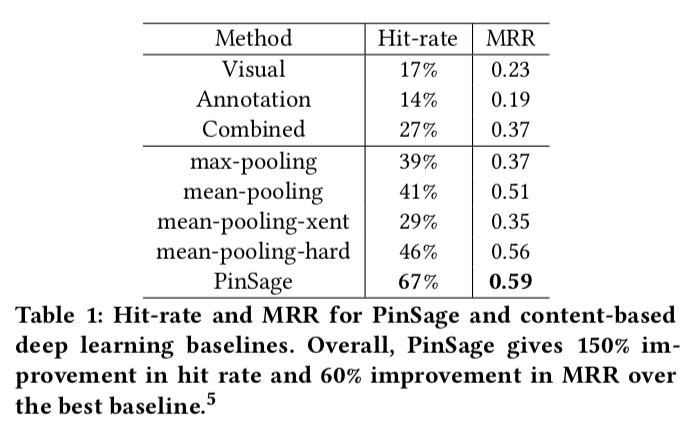
4. Experiments
Training details and data preparation
- 正例のデータ$L$は、アイテム$q$に興味を持ったユーザーが即座にアイテム$i$に興味を持った組み合わを使う。
4.2 Offline Evaluation
$$\text{MRR}=\frac{1}{n} \sum_{(q,i) \in L} \frac{1}{R_{i,q}/100}$$