一人でプログラムを書いてたりすると、環境によってはあまりコードの書き方には指摘を受けなくて困りますよね。プロになっても、曲がりなりにもちゃんと動くコードを書けてしまうとあまりに当たり前のことなんかは指摘されることも稀で、そのままある程度偉くなっちゃった日には、もはや自分で気付くしかなくなってしまいます。
FindBugsとか、Effective Javaなら使ったり読んでみたり読ませたりすることはできますが、それ以前のところって難しいんですよね。よいコードと言うよりそれが当たり前だと思われているので、指摘するにしても「こうすればいいよ」(アドバイス)じゃなくて「なんでこうしてないの?」(詰問)になってしまいがちです。
そこで、最近そういうJavaニュービーに指摘している(したい)ことの多い、Javaの基礎的な事柄をまとめてみました。ワタシJavaチョットデキルって人は、これ以外にもやりがちな項目があればぜひ指摘していただくとか記事を書いていただきたいです。
なお、この記事では基本的にはPure Java以外の話はしません。ポリシーに関するような話もしませんし、設計に関する話もしません。
Javaの書き方
まずは書き方の話です。
プリミティブのラッパークラスを使わない
intの代わりにIntegerを使う人はあまりいませんが、longの代わりにLongを使ったり、doubleの代わりにDoubleを使う人は結構います。
コード上で明示的にプリミティブのラッパークラスのインスタンスを使う利点はただ1つ、その値がnullを取れるということだけです。
// ラッパークラス
Long value = 10L;
Double d = 5.0D;
int i = value.intValue();
d = null;
----
// プリミティブ
long value = 10;
double d = 5.0D;
int i = (int) value;
d = null; // コンパイルできない …でも必要?
確かにコレクションライブラリを初めとするGenericsの都合で、ListやMapはラッパークラスを要求しますし、返り値の型もlongではなくLongになったりします。しかし、これはnullでないことが確かならlongで受けることができますし、Longで受けても何らかの操作をしようとしたときにNullPointerExceptionが出るので、単にぬるぽを遅延させるだけで何のメリットもありません。
// プリミティブで受け取る
Map<String, Long> map = new HashMap<>();
long value = map.get("nothing"); // ここでNullPointerException
value += 4;
----
// ラッパークラスで受け取る
Map<String, Long> map = new HashMap<>();
Long value = map.get("nothing");
value += 4; // ここでNullPointerException
さらにその値をあちこちで処理しようとするとどうなるでしょうか。ラッパー型を引数に受け取るメソッドは、nullを即値で受け取るコードを書いてもコンパイルエラーになりません。プリミティブ型引数ならそもそもコンパイルエラーになります。可能な限り、プリミティブを使うべきです。
/** プリミティブバージョン */
private long add(long a, long b) {
return a + b;
}
/** ラッパークラスバージョン */
private Long ADD(Long a, Long b) {
return a + b;
}
...
add(1, null); // コンパイルエラー
ADD(1, null); // 実行時例外
なお、ラッパークラスのスタティックメソッドparseXXX(String)はプリミティブ型を返し、valueOf(String)はラッパークラス型を返しますので、使い分けるとよいでしょう。
配列を使わない
現代のJavaにおいて、数値計算でもなければ配列が本当に必要なシーンというのはほとんどありません。Javaの配列は扱いやすいとは言えませんので、迷わずArrayListを使うべきです。配列は確かに重要なデータ構造ですし、ArrayListを実装するということにでもなれば、配列のことを知ってないとダメなんですが、普通のプログラムで使う意味はほとんどありません。
Listだと初期化が面倒というときには、Arrays.asList()を使ってみてください。
配列が本当に必要なシーンは、それがプリミティブ型の配列で、それなりに長く、パフォーマンスに影響を与える場合です。その場合はfastutilなどの外部ライブラリの導入を検討するとよいでしょう。
// 配列
Date[] days = new Date[5]();
int[] ints = new int[]{4, 8, 9};
----
// ArrayList
List<Date> days = new ArrayList<>();
List<Integer> ints = Arrays.asList(4, 8, 9); // その後中身を変えないでいい場合
List<Integer> modifiable = new ArrayList<>(Arrays.asList(4, 8, 9)); // 中身を変えたい場合
宣言時に意味のない初期化をしない(ローカル変数)
「変数は宣言と同時に初期化する」
これは一部の(ほとんどの場合はC言語の)コーディングガイドの流儀です。
Javaにおいては、念のための初期化は不要なばかりか、「値が代入されないケースがある」という種類のエラーを殺してしまい、実行時エラーに化けさせてしまうなど害悪にすらなります。
プロパティ変数も意味のない初期化を避けたほうが良いのですが、こちらは一般的には初期化漏れを警告してくれないため、とりあえず初期化しておくというのも、ルールとしてはアリかも知れません。
// 不要な初期化
String str = null;
if (condition) {
str = "OK";
} else {
str = "NG";
}
----
// 初期化しない
String str;
if (condition) {
str = "OK";
} else {
str = "NG";
}
標準ライブラリ編
ライブラリの使い方です。Javaはドキュメントが日本語でも揃ってる方だと思うんですが、リンク機能が弱いせいか、必要な機能を探せなかったと思われるコードを見ることがあります。
new Date().getTime()よりSystem.currentTimeMillis()を使う
long now = new Date().getTime(); //ではなく
----
long now = System.currentTimeMillis(); //こっちを使うべき
オブジェクトを作り捨てるとFindBugs先生にも怒られますね。
いちいち、new Date()してオブジェクトを生成する必要はまったくないので、こちらを使いましょう。
size()==0よりisEmpty()、indexOf(value)!=-1よりcontains(value)
StringやCollectionの各クラスには、size()==0で判定を行うのではなく、isEmpty()というよりわかりやすいメソッドがあります。また、indexOf()!=-1に対してはcontains()があります。
Setを使う
最近は少なくなったような気もしますが、SetをMapで代用している人がときどきいます。
SetのJavadocにはこうあります。
重複要素のないコレクションです。すなわち、セットは、e1.equals(e2)であるe1とe2の要素ペアは持たず、null要素を最大1つしか持ちません。その名前が示すように、このインタフェースは、数学で言う集合の抽象化をモデル化します。
// MapをSetっぽく使う
Map<String, String> setLike = new HashMap<>();
setLike.put("key", null);
setLike.containsKey("key");
----
// ちゃんとSetを使う
Set<String> set = new HashSet<>();
set.add("key");
set.contains("key");
TreeMapを使う
順序付きのMapです。HashMapに値を入れておいて、必要になるたびにキーだけListに取り出してCollections.sort()して順番に取り出す、というようなことをしているのであれば、TreeMap/TreeSetを使ってみてください。
Map<String, String> map = new HashMap<>();
...
List<String> keys = new ArrayList<>(map.keySet());
Collections.sort(keys);
for (String k : keys) {
String v = map.get(k);
...
}
----
Map<String, String> map = new TreeMap<>();
...
for (Map.Entry<String, String> entry : map.entrySet()) {
String k = entry.getKey();
String v = entry.getValue();
...
}
ただし、取り出しを1度しか行わない場合にはCollections.sort()した方が速いこともあると考えられるので、TreeMapを知っていてもこのようなコードを書くことはあります。
LinkedHashMapを使う
Mapにput()した順番で取り出したいんだけど、HashMapだと順番がバラバラになるので、キーだけListに格納してあとでその順番で取り出す、というようなことを考えているのならLinkedHashMapというそれ用のコレクションがあります。
// HashMapをLinkedHashMapっぽく
Map<String, String> map = new HashMap<>();
// キー順序を保持しておく
List<String> order = new ArrayList<>();
map.put("key", "value");
order.add("key");
...
for (String k : order) {
String v = map.get(k);
// do something
}
----
// LinkedHashMapを使う
Map<String, String> map = new LinkedHashMap<>();
map.put("key", "value");
...
for (Map.Entry<String, String> entry : map.entrySet()) {
String k = entry.getKey();
String v = entry.getValue();
// do something
}
MapをforEachで回すには、entrySet()を使う
Map.Entryなんて覚えてられないという気持ちもわかるんですが、keySet()でキーをループしてキーごとにget()するよりentrySet()を使ってキーと値のペアを一気に取り出すべきです。
// keySet()とget()で取り出す。
Map<String, String> map = ...
...
for (String key : map.keySet()) {
String value = map.get(key);
...
}
----
// entrySet()で一気に取り出す
Map<String, String> map = ...
...
for (Map.Entry<String, String> entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
...
}
なんかヤダって時はJava8に移行するといいですよ。
// Java8の場合
Map<String, String> map = ...;
...
map.forEach((key, value) -> {
...
});
Collections.XXXを使う
たとえば空のリストを返したいときはCollections.emptyList()を使います。return new ArrayList<>()なんてしているコードがあったら要注意ですね。Collectionsクラスの便利メソッドは一通り見ておくとよいのではないでしょうか。Java8から使えるメソッドもあります。
Javadocを眺めてみる
標準ライブラリには素晴らしいドキュメントがあります。ありますが、Javadocの歩き方はなかなかわかってもらえないようです。技術的な正しさを求めたがためにわかりにくくなっているということ以外に、おそらく見落としがちなポイントが3つあるのだと思います。
https://docs.oracle.com/javase/jp/8/docs/api/
継承関係を見る
たとえばHashMapを見てLinkedHashMapを知るにはどうすればいいでしょうか。似たような機能を持ったクラスは継承関係にあることが多いので、継承周りから探します。
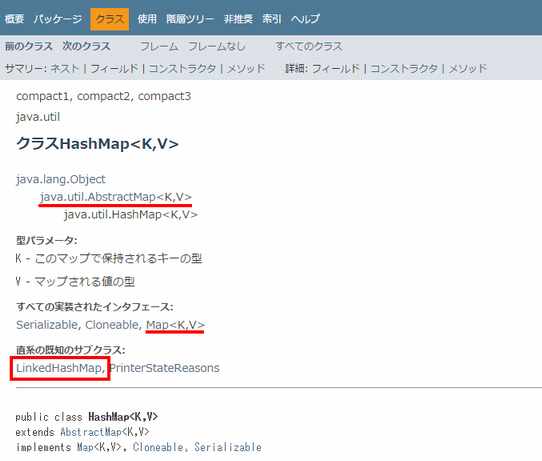
HashMap
他にもHashMapはMapを継承していることがわかります。Mapの他の実装がないかは、MapのJavadocを見るとわかります。また、HashMapの継承関係から、AbstractMapなるものがあることもわかります。自分でMapを実装することがあれば便利そうですね。
「関連項目」も眺めてみる
クラスの概要には割とためになることが書かれていますが、その下の、関連項目も大事です。
Collectionに対するCollectionsやArraysのように、複数形のクラス名はユーティリティであることが多いのでそういうのを見つけたら重点的にチェックしておきましょう。

パッケージのクラスを一覧で見てみる
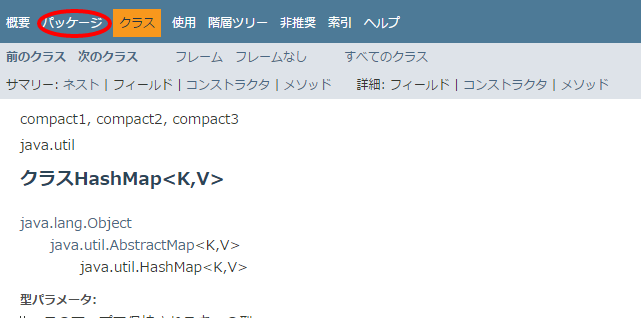
「パッケージ」をクリックするとjava.utilに属する全パッケージとその概要、java.util自体の説明が読めます。
たぶん、標準ライブラリのパッケージ概要が一番読まれていない割に重要なことが書いてあるところじゃないでしょうか。
Javadocはどこかを押してみてもそれほど不幸なことにはならないので、遠慮せず冒険してみましょう。
発展
基礎というほど基礎ではないですが知っておくとよい話です。
コメントをJavadoc形式で書く
コメントをJavadoc形式で書いておくと、Javadocを生成しなくても、各IDEが解釈してくれて幸せになれます。どうせコメントを書くのであれば、Javadoc形式で書きましょう。
// ただのコメント
// 何かするメソッド
private void doSomething(int i) {
...
}
---
// Javadoc形式
/**
* 何かするメソッド
* @param i 引数例
*/
private void doSomething(int i) {
...
}
初見だとこれを書くのは面倒そうに見えるんですが、有名どころのIDEには支援機能があるので、/** + enterでたいていはどうにかしてくれます。
hashCodeとequalsを実装する
HashMapのキーに複数の値を使いたいときに、Stringで結合させて無理やりキーを作っていませんか?HashMapのキーに自作のクラスオブジェクトを入れ込むには、hashCode()とequals()の2つのメソッドを実装します。実装方法がわからなくても、今どきはIDEに生成機能があるので、ほとんどの場合はそれで事足りるはずです。
// 本当はSetなんだけど、MyObjectをキーにできないからMapにする
public class MyObject {
public String name;
public int score;
}
...
Map<String, MyObject> values = new HashMap<>();
MyObject obj = ...
values.put(obj.name + "_" + obj.score, obj);
----
// ちゃんとMyObjectをキーにする
public class MyObject {
public String name;
public int score;
public int hashCode() {
... // 省略
}
public boolean equals(Object obj) {
... // 省略
}
}
...
Set<MyObject> values = new HashSet<>();
MyObject obj = ...
values.add(obj);
なお、TreeMap/TreeSetのキーとして使いたい場合はComparator<MyObject>を作るかComparable<MyObject>を実装します。ググってください。
toString()を書く
toString()を実装しておくと、printfデバッグやロガー出力が楽になります。
// デバッグでそれぞれの値を出したい
public class MyObject {
public String name;
public int score;
}
...
MyObject obj = ...
System.out.printf("今の値:" + obj.name + ":" + obj.score);
----
// toStringする
public class MyObject {
public String name;
public int score;
public String toString() {
return name + ":" + score;
}
}
...
MyObject obj = ...
System.out.printf("今の値:" + obj); // 文字列と+すると自動的にtoString()が呼ばれる
これでデバッグ用にプロパティ変数をpublicにしたり本質的でないgetterを作ったりしなくてもよくなりますね。
コレクション同士の操作はたいていメソッドとして存在する
いや、もうそのままなんですが、addAll()やretainAll()とかremoveAll()、あと判定にはcontainsAll()とかCollections.disjoint()とか使うといいですよ。あとは、標準ライブラリのコレクションはコンストラクタで要素をコピーできます。
// valuesBからvaluesAと重複する要素だけを取り出した新しいSetを作る
Set<String> valuesA = ...
Set<String> valuesB = ...
Set<String> duplicates = new HashSet<>();
for (String a : valuesA) {
if (valuesB.contains(a) {
duplicates.add(a);
}
}
----
// それretainAllでできます
Set<String> valuesA = ...
Set<String> valuesB = ...
Set<String> duplicates = new HashSet<>(valuesA); // コピーして
duplicates.retainAll(valuesB); // 重複していない要素を一括削除
一度は自力で各メソッドを実装してみるのも楽しいのですが、そういう機能はたいていすでにあります。
getする前にcontainsKeyしない(Map)/addする前にcontainsしない(Set)
これは割と細かい話なんですが、Mapでgetしたりremoveしたりする前にcontainsKey()してそのキーがあるか確かめるコードを割とよく見ます。Map#getはキーが無ければnullを返すので、それで判定できます。キーがあってもnullを値として入れている場合と区別できないという問題がありますが、そもそもnullを値として使う場合はほとんどないはずです。
Map#remove()やSet#add()はもっと安全で、キーが無くても怒られないですし、addしたらそのキーがaddする前にも存在したかどうかを返してくれます。
// キーがあればgetして処理を行う
if (map.containsKey(key)) {
value = map.get(key);
doSomethingWith(value);
}
// キーがなければaddして処理を行う
if (!set.contains(key)) {
set.add(key);
doSomething();
}
----
// getだけを使う
value = map.get(key);
if (value != null) {
doSomethingWith(value);
}
// addだけを使う
if (set.add(key)) {
doSomething();
}
ただし、もはやcontainsしてからなにかするというのはイディオム化しつつあるらしく、経験上「わかりにくいコード」だと考えられることもあるようです。
ちなみにJava8ではキーがあったりなかったりするときの便利メソッドがMapやSetにたくさん生えているので、Java8環境ではそういうのをどんどん使っていきましょう。
時間範囲を使用するときはTimeUnitを使う
Thread.sleep(10000);
さて何秒のスリープでしょうか。もうサッパリですね。
Thread.sleep(10 * 1000)
ああそうだ、思い出した。確かミリ秒なんでしたね。
ということを時間範囲の設定のたびに繰り返すのはやめましょう。
今はTimeUnitがあります。
Thread.sleep(TimeUnit.SECONDS.toMillis(10));
だいぶマシになりました。
TimeUnitはjava.util.concurrentに属するので、マルチスレッドでコードを書かないとあまり目に触れないかもしれませんが、時間範囲に属するいろんなところでよりわかりやすいコードが書けます。
なお、Thread.sleep()に関しては専用のメソッドがあるので、こちらを使ってください。
TimeUnit.SECONDS.sleep(10);
String.formatを使う
Javaにおけるsprintfは、String.format()にあります。文字列と値を+したり、StringBuilder/StringBufferで連結してコードが汚くなったときは導入を考えるといいですね。
// String.formatがないとき
String message = "値a=" + a + ", 値b=" + b + ", 値c=" + c + ", 値a+b=" + (a + b);
---
// String.formatがあるとき
String message = String.format("値a=%d, 値b=%d, 値c=%d, 値a+b=%d", a, b, c, a + b);
sprintfに合わせてフォーマットの指定が%dなどできますが、全部%sにすると勝手にtoString()して表示してくれるので、面倒なときは%sでもよかったりします。sprintfを知ってるとだいたいの感覚で使えるんですが、より詳しいフォーマット指定はFormatterクラスを見る必要があります。
ラベル付きbreak/ラベル付きcontinue(を多用しない)
boolean breakFlag = false;
for (int i = 0; ; i++) {
for (int j = 0; ; j++) {
if (...) {
breakFlag = true;
break;
}
}
if (breakFlag) break;
}
// 条件に合致しなかった場合になにか代替処理を行う
if (!breakFlag) errorProcess();
afterProcess();
みたいなのは比較的よく見るコードです。
これはラベル付きbreakを使ってこのように書くことができます。
(breakFlagだとかiLoopだとかはもっといい名前を付けてくださいね)
boolean breakFlag = false;
iLoop: for (int i = 0; ; i++) {
for (int j = 0; ; j++) {
if (...) {
breakFlag = true;
break iLoop;
}
}
}
// 条件に合致しなかった場合になにか代替処理を行う
if (!breakFlag) errorProcess();
afterProcess();
しかし、ラベル付きbreakの使用は避けるべきです。ラベル付きbreakが必要なシーンなんてものはたいていの場合は複雑になりすぎたコードです。こういうコードを書くのは何かの探索が多いでしょうか。いずれにせよ、簡単にメソッド化できるはずです。
private boolean findIt(...) {
for (int j = 0; ; j++) {
if (...) {
return true;
}
}
return false;
}
private void findAndProcess() {
for (int i = 0; ; i++) {
if (findIt()) {
afterProcess();
return;
}
}
errorProcess();
}
綺麗にやるとこんな感じでしょうが、1メソッドで2重ループしてreturnで抜けてもいいですね。本質的にラベル付きbreakでできることとreturnでできることは同じです。ラベル名を付けられるのならメソッド名も付けられるでしょうし、メソッドの方が見通しが良いことは間違いないでしょう。
ラベル付きcontinueも一般的には見通しの悪いコードになりがちなので、同様にメソッド分割できないか検討しましょう。
イニシャライザー(を多用しない)
Javaにはあまり知られていない機能としてスタティックイニシャライザーとインスタンスイニシャライザーがあります。
public class MyObject {
public String name;
public int score;
private static Date begin;
static {
// これがスタティックイニシャライザー
System.out.println("static!");
begin = new Date();
}
}
---
public class MyObject {
public String name;
public int score;
{
// これがインスタンスイニシャライザー
System.out.println("instance!");
score = 0;
}
}
実行されるタイミングや用途などはググってもらえるとすぐわかるでしょう。これを利用して素直でないコードが書けますが、インスタンスイニシャライザーは普通はコンストラクタで処理すべきですし、スタティックイニシャライザーも、ファクトリークラスや初期化用のメソッドを作ることを検討すべきです。
おわり
おわり