またまた久しぶりの投稿です。就活真っ最中です。今回はインスタから画像、動画をスクレイピングすることができるのか検証してみました。機械学習で画像を大量に取得したいとか、様々な"インスタ映え"してる画像を保存したいって人は自己責任で使ってみて下さい。使用言語はrubyです。いつか暇だったらpythonでもやってみるつもりです。
seleniumでinstagramにログイン
ここは前回の記事と同じです。seleniumでログインページへ飛び、ユーザー名とパスワードを入力してログインしてるだけです。
def initialize(username,password)
Selenium::WebDriver::Chrome.driver_path = "/mnt/c/chromedriver.exe"
ua = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
caps = Selenium::WebDriver::Remote::Capabilities.chrome('chromeOptions' => { args: ["--user-agent=#{ua}", 'window-size=1280x800', '--incognito'] }) # シークレットモード
client = Selenium::WebDriver::Remote::Http::Default.new
client.read_timeout = 300
@driver = Selenium::WebDriver.for :chrome, desired_capabilities: caps, http_client: client
@driver.manage.timeouts.implicit_wait = 60
@driver.navigate.to'https://www.instagram.com/accounts/login/?source=auth_switcher'
@driver.find_element(:name, 'username').send_keys(username)
@driver.find_element(:name, 'password').send_keys(password)
sleep 1
@driver.find_element(:name, 'password').send_keys(:return)
end
画像を保存するメソッド
メソッド全体を先にさらします。引数のkey_wordにハッシュタグの単語、numberは保存する投稿の数です。(一つの投稿に複数の画像があることが多いですが、全ての画像を保存します。)
def save_image_hashtag(key_word,number)
encode_word = URI.encode(key_word)
sleep 3
@driver.navigate.to"https://www.instagram.com/explore/tags/#{encode_word}/"
sleep 5
@driver.execute_script("document.querySelectorAll('article img')[9].click()")
sleep 2
count = 0
number.times{
count += 1
count_img = 1
loop{
if count_img == 1
img_index = 0
else
img_index = 1
end
sleep 1
media_array = @driver.find_elements(:css, 'article')[1].find_elements(:css, 'video,img.FFVAD')
media_url = media_array[img_index].attribute('src')
if media_url.include?('mp4')
file_name ="img/"+count.to_s+"_"+count_img.to_s+".mp4"
else
file_name ="img/"+count.to_s+"_"+count_img.to_s+".jpg"
end
open(file_name, 'wb') do |file|
file.puts(Net::HTTP.get_response(URI.parse(media_url)).body)
end
if css_exist?('div.coreSpriteRightChevron')
@driver.find_element(:class, 'coreSpriteRightChevron').click()
count_img += 1
else
@driver.execute_script("document.querySelector('a.coreSpriteRightPaginationArrow').click()")
break
end
}
sleep 2
}
end
def css_exist?(css_selector)
rescue_session = @driver
rescue_session.manage.timeouts.implicit_wait = 5
if rescue_session.find_elements(:css,css_selector).empty?
false
else
true
end
end
簡単な部分や前回と同じ部分は割愛します。ハッシュタグの検索結果へ遷移する所や最初の投稿をクリック、次の投稿をクリックしている所です。
画像または動画のある要素からurlを取得
media_array = @driver.find_elements(:css, 'article')[1].find_elements(:css, 'video,img.FFVAD')
media_url = media_array[img_index].attribute('src')
実際にurlを取ってきている部分はここなんですが、このCSSの指定の仕方にたどり着くのに一番苦労しました。
videoタグが動画、img.FFVADが画像の入っている要素です。
複数の画像がある投稿だと1枚目では1つ、2枚目以降はその前の画像のタグも出現してるという仕様になっているので、画像が1枚目かどうかでimg_indexの値を変えることで過不足なく全画像を取れるようにしました。
また、画像と動画がどういう順番で乗っているかわからないので、video,img.FFVADというセレクタを使いました。カンマ区切りでどちらかに当てはまる要素を持ってこれるんですね、初めて使いました。
if media_url.include?('mp4')
file_name ="img/"+count.to_s+"_"+count_img.to_s+".mp4"
else
file_name ="img/"+count.to_s+"_"+count_img.to_s+".jpg"
end
open(file_name, 'wb') do |file|
file.puts(Net::HTTP.get_response(URI.parse(media_url)).body)
end
動画なのか画像なのかをurlから判定して保存。ファイル名は何個目の投稿の何枚目の画像なのかを表す。
if css_exist?('div.coreSpriteRightChevron')
@driver.find_element(:class, 'coreSpriteRightChevron').click()
count_img += 1
else
@driver.execute_script("document.querySelector('a.coreSpriteRightPaginationArrow').click()")
break
end
複数の画像の場合次の画像があったら遷移してなければループを抜ける。
username = "username"
password = "password"
bot = InstagramBot.new(username,password)
key_word = "乃木坂ライブ"
bot.save_image_hashtag(key_word,300)
実行部はこんな感じ。InstagramBotというclass化している。
key_wordは自分は乃木坂のオタクってだけです。気にしないでください。
応用例
検証してて色々な改良案を思いついたのであげておきます。
- 特定のユーザーの投稿をスクレイピング
- 「いいね」する機能と組み合わせて既に画像取得した投稿を飛ばす
- 関係ないものが写っている画像を除外する。
1つ目は最初に飛ぶurlを変えるだけ。2つ目は画像保存して次の投稿に移る前にいいねボタンを押しといて、次にクローラー動かす時にいいねしてある投稿をスキップするといった感じ。これはわざわざログインしている利点が活かされるかもしれない。
3つ目に関しては、次の画像をご覧ください。
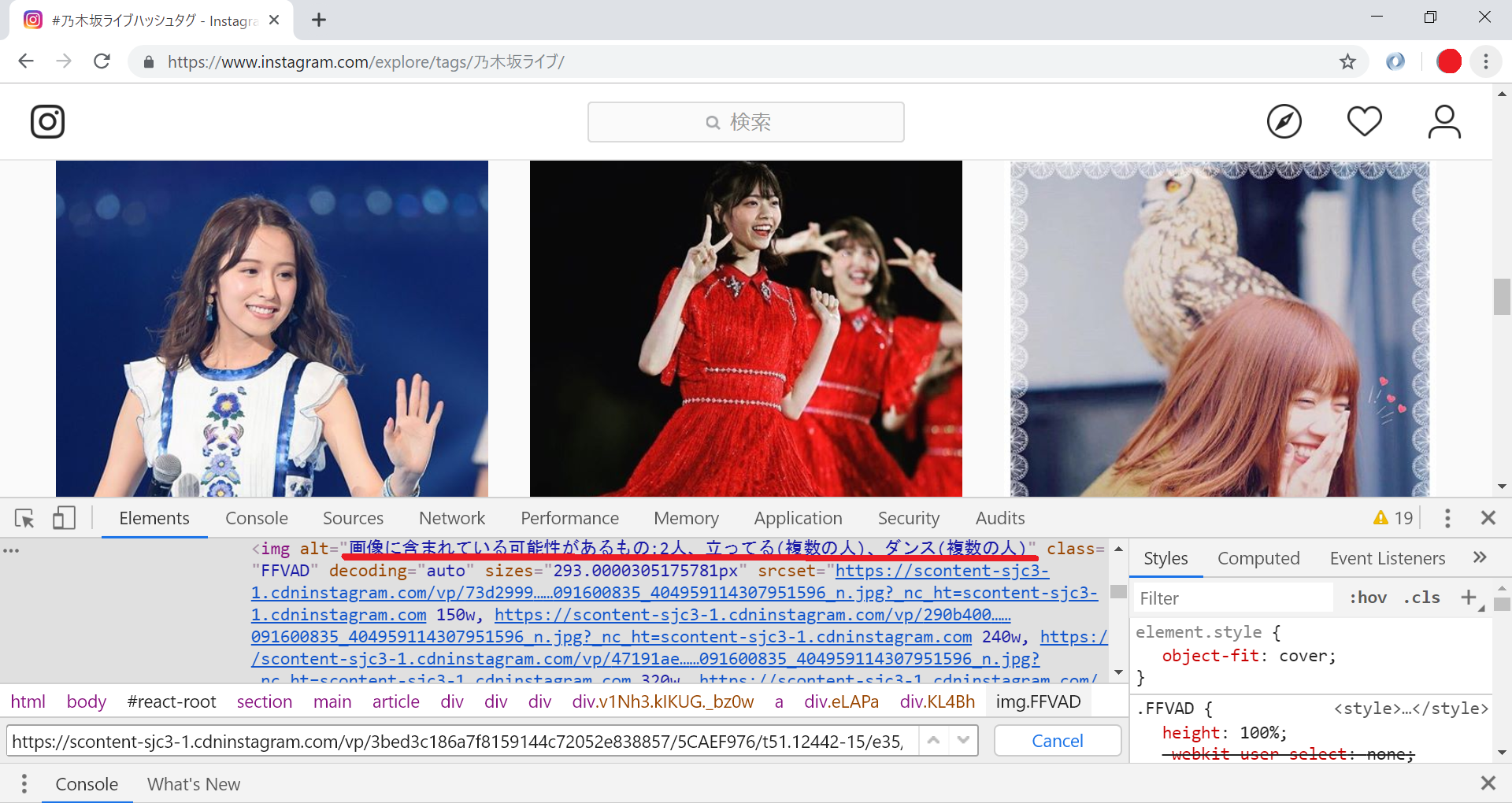
chromeのデベロッパーツールでhtmlを見てみたものなんですが、赤線を引いた部分(imgタグのalt属性)に画像に何が写っているか書いてある!!!しかも何人の人が乗ってるかまで!インスタグラムってすげー。。。
例えば乃木坂46のメンバーを検索した時って、メンバーの画像ではなく文章を載せた画像が結構あったりするんですが、このalt属性を取得して、「人」という文字が含まれているかどうかを判別すれば余計な画像を除外できます。
「食べ物」「植物」「空」「自然」など色々な要素に分類してくれてるのでこれを使うと欲しい画像だけ抽出しやすくなるでしょう。
終わりに
プログラミングの勉強としてインスタグラムの画像をスクレイピングできるのかを検証してみました。特にインスタはスマホの公式アプリだと画像保存できないので検証してみようと思った次第です。頑張ればストーリーの画像、動画も保存できると思います。インスタはクロールするのあまりよくないと思うので、あくまで検証しただけで実際には使わないです。使ってBANされても自己責任で。