Microsoft Azureの自然言語処理サービスのLUIS(Language Understanding Intelligent Service)は非常に便利です。
会話の**意図(Intents)とエンティティ(Entities)**を同時に抽出することができ、簡単な会話応答プログラムやチャットボットであれば簡単に作ることができます。(エンティティとは抽出したい単語のことです)
ところが、エンティティを入力していくのは割と骨が折れる作業です。例えば「現在の居住地」と「引越し希望先」が入力されると、最適な引越しプランを教えてくれるチャットボット(のための地名の抽出API)を作ることを考えます。
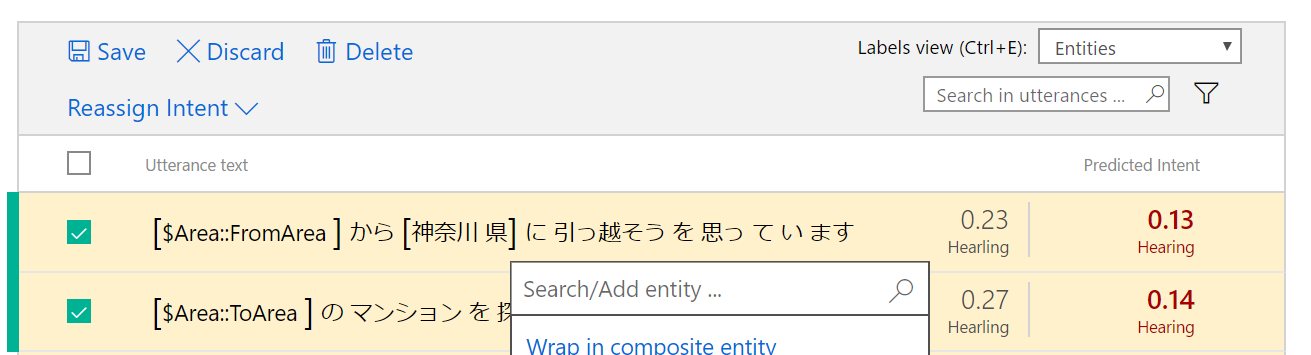
ブラウザ画面を使うと、上の画像のように、例文と「ここからここまでが抽出したいエンティティ」というのをひとつひとつ入力していく必要があり、なかなか根気のいる作業でした。
作戦
LUISには、JSONのエクスポートとインポート機能が備わっています。
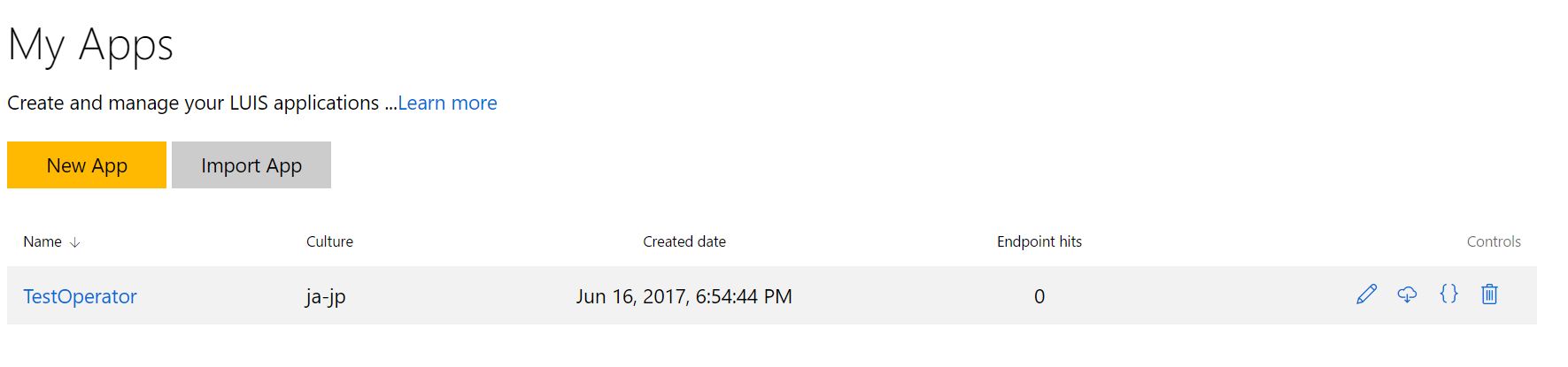
上記画面のアプリケーションのトップページのそれぞれのアプリケーションの{}でエクスポートできますし、Import Appでアップロードしなおすことができます。
そのため、
- 以下のようなExcel上で情報を入力する
- csvに書き出す
- PythonのスクリプトでJSONに変換する

Pythonスクリプト
JSONファイルを生成するために、次のようなスクリプトを用意します。利用しているPythonのバージョンは3.5です。
細かい設定やファイル名は固定値で入れていますが、今回は書き捨てのコードだし、追加するにしても多少のコード変更で済むと思うので許してください。
今回は「引越し元(Area::FromArea)」と「引越し先(Area::ToArea)」親子関係のある(Hierarchical)エンティティで表現するために工夫しました。もちろん、親子関係のないエンティティにも対応しています。
また、Pythonの辞書型は順番を保持しないので、OrderedDictを使いました。おそらく順番は保持しなくても良いはずですが、出力を確認するときに面倒すぎるので…。
# !/usr/bin/env python3
import json
import csv
from collections import defaultdict, OrderedDict
def main():
df = _read_csv('./input.csv')
output = _create_output(df)
print(json.dumps(output))
class DataFrame(list):
def __getitem__(self, key: str) -> list:
return [x[key] for x in self]
def keys(self) -> set:
res = set()
for x in self:
for y in x.keys():
res.add(y)
return res
def _create_output(df: DataFrame) -> OrderedDict:
entity_keys = df.keys() - {'text', 'Entities', 'intent'}
entities = _create_entities(entity_keys)
intents = _create_intents(df['intent'])
utterrances = _create_utterances(df, entity_keys)
return _create_luis_schema(intents, entities, utterrances)
def _read_csv(path: str) -> DataFrame:
with open(path, 'r', encoding='utf8') as f:
df = DataFrame(l for l in csv.DictReader(f) if l)
return df
def _create_entities(entities: list) -> list:
res = []
for name, children in _parse_entities(entities).items():
cs = [c for c in children if c is not None]
res.append(_create_entity(name, cs))
return res
def _create_intents(intents: list) -> list:
res = set(intents)
res.add('None')
return [{'name': n} for n in res]
def _parse_entities(entities: list) -> defaultdict(set):
res = defaultdict(set)
for entity in entities:
name, child = _parse_entity(entity)
res[name].add(child)
return res
def _parse_entity(entity: str) -> tuple:
if '::' not in entity:
return (entity, None)
return tuple(entity.split('::'))
def _create_entity(name: str, children: set) -> OrderedDict:
res = OrderedDict([('name', name)])
if len(children) >= 1:
res['children'] = list(children)
return res
def _create_utterances(rows: DataFrame, entity_keys) -> list:
return [_create_utterrance(x, entity_keys) for x in rows]
def _create_utterrance(row: dict, entity_keys: set) -> OrderedDict:
return OrderedDict([
('text', row['text']),
('intent', row['intent']),
('entities', _create_utterrance_entities(
row['text'], [(k, row[k]) for k in entity_keys]))
])
def _create_utterrance_entities(text: str, entitity_items: list) -> list:
return [_create_utterrance_entity(text, k, v)
for k, v in entitity_items if v] # not ''
def _create_utterrance_entity(
text: str, entity_key: str, entity_value: str) -> OrderedDict:
start_pos = text.find(entity_value)
return OrderedDict([
('entity', entity_key),
('startPos', start_pos),
('endPos', start_pos + len(entity_value) - 1)
])
def _create_luis_schema(
intents: list, entities: list, utterrances: list) -> OrderedDict:
return OrderedDict([
('luis_schema_version', '2.1.0'),
('versionId', '0.1'),
('name', 'TestOperator'),
('desc', 'forTestOperator'),
('culture', 'ja-jp'),
('intents', intents),
('entities', entities),
('composites', []),
('closedLists', []),
('bing_entities', []),
('actions', []),
('model_features', []),
('regex_features', []),
('utterances', utterrances)
])
if __name__ == '__main__':
main()
ただし、抽出したい文字列が2箇所ある場合、最初のものしか指定できません。これはまあ入力のときに気をつければいいでしょう。
このスクリプトを実行して適当なjsonファイルに出力し、先ほどのブラウザ画面からインポートすれば学習させたいテキストが用意された状態のappsが準備されるはずです。
python3 export_schema.py > output.json
今後の展望
Azure CLIも用意されているようなので、もしかするとインポート/エクスポート作業なども自動化もできるのかもしれません。
もし運用まで載せられることができたら、省力化のために試してみようと思います。