前提・背景
私は有料集客支援の内製ツール(MAM)の実装と運用に携わっています。このツールの中では、各媒体からデータ取得して加工する、いわゆるETL処理のバッチが100個以上存在します。
ところが、システムが古びてきてしまっていて、ここ数年はいくつかの絡まった問題を抱えてしまっていました。具体的に言うと次のようなものです。
- バッチ処理の実行にサポートの切れたAmazon Linux AMI(AL1)を使ってしまっている
- ところが、社内のAWS環境で運用しているGitLabとJenkinsを利用している。特にJenkinsのCIで動いているサーバーもAL1なので、AL2に移行できない
- 該当リポジトリに秘匿情報が含まれてしまっていて、(会社ルールとして)GitHubにそのまま移行できない
- 過去利用されているが、今は利用されていない処理も多く残されていて、整理しづらい
今回の記事では、そんな状態を整理して、コツコツ解消した方法を共有します。他にもElastic Beanstalkで立ち上げられたダッシュボード画面でも同様の作業がありました。ただ今回は割愛します。
Before After
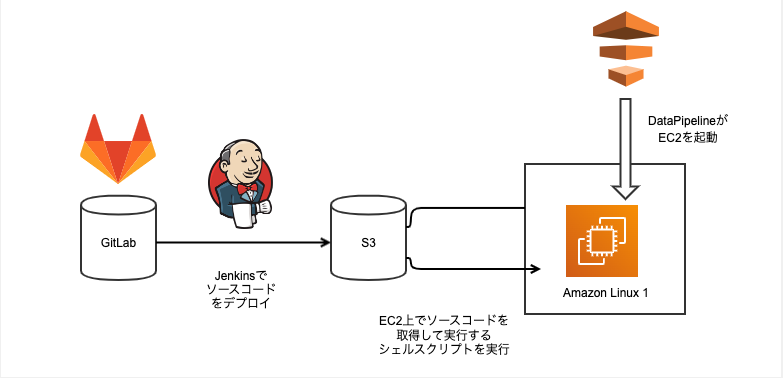
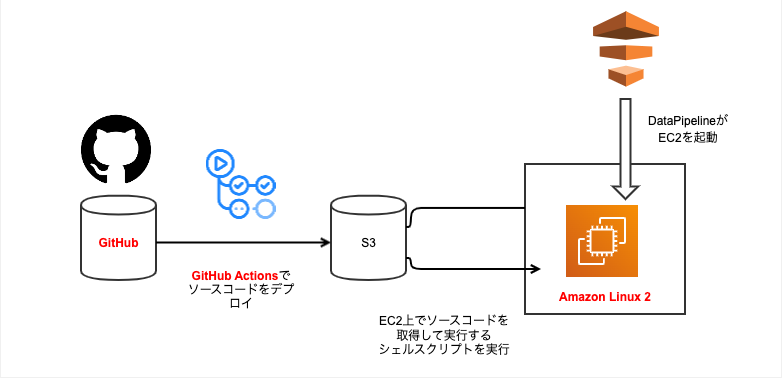
まず、前後でどう整理したのか図で説明します。Before Afterは次のような感じで、次の3点が変更されています。ソースコードの流れを実線の矢印で示しています。
- GitLabがGitHubに置き換わった
- JenkinsがGitHub Actionsに置き換わった
- EC2インスタンスがAL1からAL2にバージョンアップした
Before
After
さらに、「Prefect Cloud + Fargateでバッチ処理のワークフローを作成するまで」でも説明した通り、近い将来、これを次のように徐々に変えていく予定です。
- DataPipelineによるバッチ起動をPrefectに移行する
- 徐々にバッチ処理をDocker化し、EC2からFargateに移行する。(それに伴ってデプロイ先もS3からECRに変える)
- 全社のバッチ基盤に移行する(※「データ活用を促進するためのデータプラットフォーム開発」を参照)
まとめてしまうと、多数のバッチがあって一気に置き換えるのは現実的ではないので、徐々にフェードイン・フェードアウトさせる作戦です。
移行までの道のり
次に、移行までに実際に行ったこと、悩んだ点などを紹介します。
①明らかに利用されていない処理を削除する
私達はこれまで、あるデータ取り込みバッチが廃止されるときに、「DataPipelineからのみ削除して、ソースコードからは削除していない」という状態でした。そのため、何をするにも必要以上に難しく見えてしまうような状態でした。
そこで、次のような表を作り、不要なソースコードを手分けして洗い出して削除しました。

また、スクラムっぽい何かを導入していて、バッチごとに削除のチケットを切って他の開発タスクの合間に進めやすくしながら、スプリントイベントで「予定から大きく外れてないよね」って確認しながら進めました。
②秘匿情報を消し、独自運用のGitLabからGitHubに移行する
実は多数の広告媒体や社内DBに接続していて、ソースコードにそれらの接続情報がベタ書きで管理されてしまっていました。社内のセキュリティルール上、GitHubに秘匿情報をpushしてはいけないため、パラメータストア等に退避させる必要があります。また、広告の権限を持ったチーム外の開発者に見えてしまうのも避けるべきです。
これも①と同様に、「表を作って、それを元に小さくチケットを作り、手分けして削除する」という作戦を取りました。
過去のコミットログは、GitHubに移行する時点で消してしまいました。一応、git-filter-repoなどのツールはあるものの、過去にあった接続先などは確認しきれなかったためです。代わりに、GitLab時代のコミットログを含めたソースコードはAWS CodeCommitに保存しています。(ただ、コンソール上でgit blameにあたる操作ができないなど、不便な点は多い)
この時点でJenkinsも廃止したかったのですが、とある事情(後述)で一旦諦め、「Jenkinsのビルド時にcloneするリポジトリをGitLabからGitHubに切り替える」という方法でしのぎました。ただ、GitHubから社内のJenkinsに手軽にWebHookで通知する方法がなく、「一時的だから仕方ないよね」って判断で手動でJenkinsのスクリプトを起動してました😅
③AL2用のデプロイをGitHub Actionsに実装する
次に、Jenkinsで行なっていたデプロイ処理をGitHub Actionsに移行しました。このとき、OpenID Connectを使って、GitHub ActionsにS3の特定バケットにputする権限のみ与えています。
- アマゾン ウェブ サービスでの OpenID Connect の構成(※自分たちのケースにドンピシャでした)
- OpenID Connect (OIDC) ID プロバイダーの作成
- GitHub ActionsにAWSクレデンシャルを直接設定したくないのでIAMロールを利用したい
(余談ですが、当時の自分はこのOpenID Connectの方法を把握できていなかったんですが、社内のQ&Aフォーラムで相談して、アーキテクトチームからアドバイスをいただきました🙇♂️)
また、このときS3に成果物の中に、Rubyのgemも一緒に含める形にしてあります。そのため、GitHubホステッドランナーにあるubuntuでは同じ環境が再現できなくて、al2のイメージをdocker buildして、その成果物をdocker cpで取り出すというやっています。
- name: Build
run: |
docker build . -t $IMAGE_NAME
docker cp `docker create $IMAGE_NAME`:/workspace ./workspace
mkdir distribution
tar cvzf 'distribution/mam-etl.tar.gz' 'workspace'
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
role-to-assume: ${{ env.AWS_ROLE }}
role-session-name: github-deploy
aws-region: ${{ env.AWS_REGION }}
- name: Deploy
run: |
aws s3 cp distribution/mam-etl.tar.gz "s3://${S3BUCKET}/al2/master/mam-etl.tar.gz"
これと同じ実装がAL1では(おそらく使っていたバージョンもかなり古かったため)動作しなかったという事情があります。
④複数バージョンのデプロイ処理を併存させて、徐々に切り替えていく
次に、実際にAL2をベースに、必要なミドルウェアをインストールしたAMIを作成する必要があります。実は、運良くAL1時代のスクリプトが残っていたため、それを修正する形で大きな問題なく作成できました(これは当時のチームリーダーに感謝です🙏)。
次にDataPipelineで起動するAMIを切り替えればいいのですが、こうしたOSのバージョンアップって、丁寧にテストしたつもりでも、だいたい何かしら想定外のエラーが起こるものです。そのため、AL1のデプロイ処理をしばらく併存させて、徐々に切り替える方針にしました。
特に、利用しているバッチの接続先が社内のいくつか別チームのDBにまたがっていたため、MySQLやPostgreSQLなど、特定の接続先のみ問題が起きるようなケースが懸念でした。そのため、具体的には次のように切り替え作業を実施しました。
- 従来、AL1用のコードを
s3://${S3BUCKET}/master/mam-etl.tar.gzにputしていたのを、GitHub Actionsではs3://${S3BUCKET}/al2/master/mam-etl.tar.gzという別ディレクトリにputするようにした - DataPipelineでEC2インスタンスを立ち上げる設定から、
AMI IDと「ダウンロード先のS3のパス」を修正する - 接続先ごとに日を分けて、問題ないことを確認しながら切り替えていく
ここでは運良く大きな問題は起きませんでした。
最後に
以上のようにしてOSのアップデートをしつつ、不要な処理の削除などで、ある程度計画的にシステム面の問題をコツコツ解消していけていると思います。一言で言うと「コツコツやるやつぁご苦労さん」という気持ちです。
また、バージョン等は古かったものの、過去の資産がきちんと残されていて、これらの点で大きく詰まらなかったことも助かりました。
- バッチ処理のテストコードがきちんと実装されていたこと
- AMIを作成するスクリプトとserverspecが残されていたこと
また、いわゆるモダンデータスタックと呼ばれている分野も気になっていて、特に広告媒体からデータ取り込みできるツールもありそうで、定期的なバージョンアップ対応が不要になりそうなので気になっています。「データ活用を促進するためのデータプラットフォーム開発」のチームとも連携しながら調べて導入していきたいです。