1. 探索的データ解析とは?
機械学習エンジニアやデータサイエンティストが、一番最初に行う作業をご存知でしょうか?会社や組織から課題を与えられた場合、最初に行うのが「探索的データ解析」と呼ばれる作業です※1。この探索的データ解析は、Dataikuを使うとノンプログラミングで行えます。
※1:https://www.codexa.net/basic-exploratory-data-analysis-with-python/
2. ノンプログラミングでできること
Dataiku DSS(バージョン7.0以上)では、データセットのStatisticsタブから次のような探索的データ解析が行えます。
- 単変量解析
- 二変量解析
- 曲線へのフィッティング度合の確認
- 相関行列の作成
- 主成分分析
- 仮説検定
今回は、Dataiku DSSで用意されているチュートリアルのプロジェクトを使って、1つの項目に対する解析を行う単変量解析をしてみたいと思います。
3. Dataikuプロジェクトの作成
まず、チュートリアルのプロジェクトを作成しましょう。Dataiku DSSにログインしたら、+NEW PROJECTを選択し、DSS tutorialsを選択します。

そして、ML Practitionerを選択し、Interactive Visual Statistics (Tutorial)をクリックします。
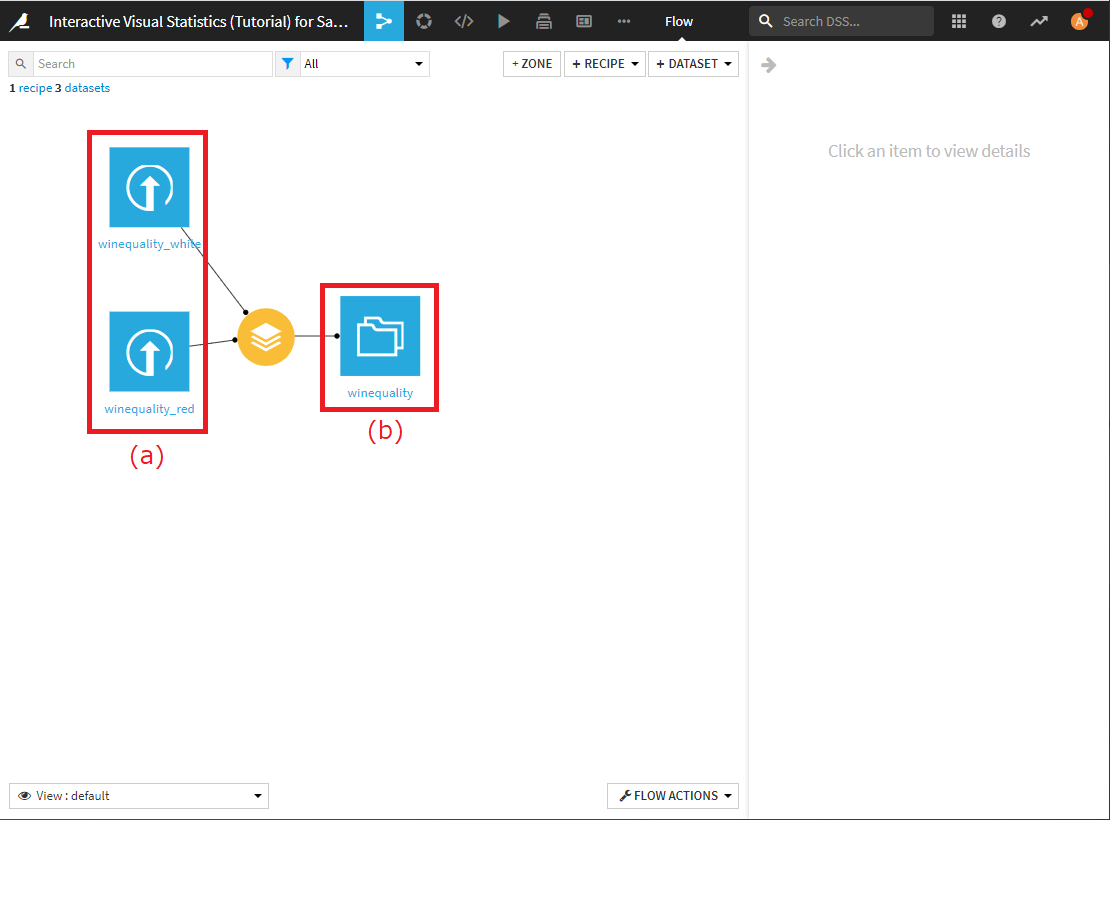
チュートリアルで使用するデータセットは、公開されているワインの品質に関するデータセット※2です(下図(a))。これらデータセット(赤ワインと白ワイン)を一つにまとめて、赤か白ワインかの種類を表す項目(type)を追加したデータセットが既に作られています(下図(b))。
※2:Paulo Cortez, António Cerdeira, Fernando Almeida, Telmo Matos, and José Reis. Modeling wine preferences by data mining from physicochemical properties. 2009.
4. 単変量解析を試してみる
それでは、winequalityデータセットをダブルクリックしてください(上図(b))。種類(type)は質的変数、それ以外の項目は量的変数です。
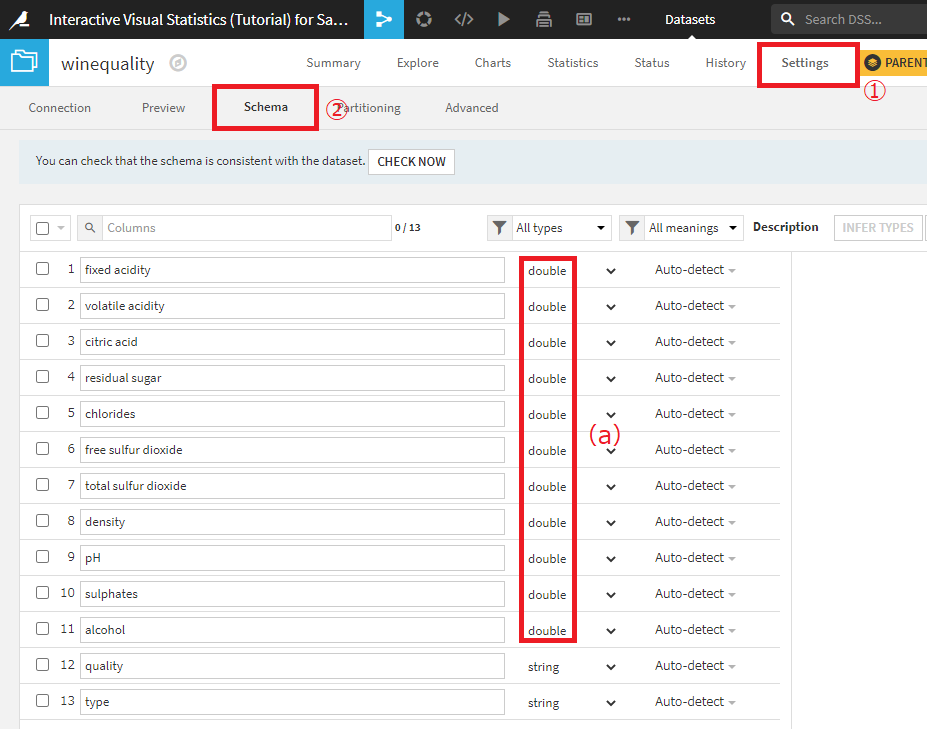
fixed acidity~alcoholのストレージタイプは、stringからdoubleへあらかじめ変更されています(下図(a))。
それでは、単変量解析をしてみましょう。まず、Statisticsタブを選択します。
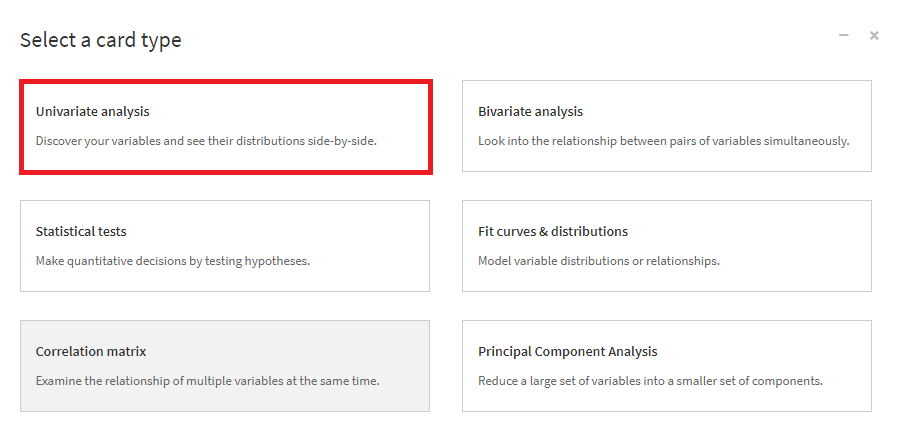
そして、Statistics画面で、+ NEW CARDを選択し、Univariate analysis(単変量解析)を選択します。

単変量解析の機能を使うと、複数項目の分布を並列に表示して観察することができます。左のウィンドウには、利用可能な項目が表示されます(下図(a))。#は量的変数、Aは質的変数を表します(qualityは量的変数ですが、ストレージタイプをstringに設定しているため、質的変数として扱われています)。

それでは、密度(density)、アルコール、種類の3項目について単変量解析を実行してみましょう。密度、アルコール、種類をそれぞれ選択して、真ん中のウィンドウへドラッグします。
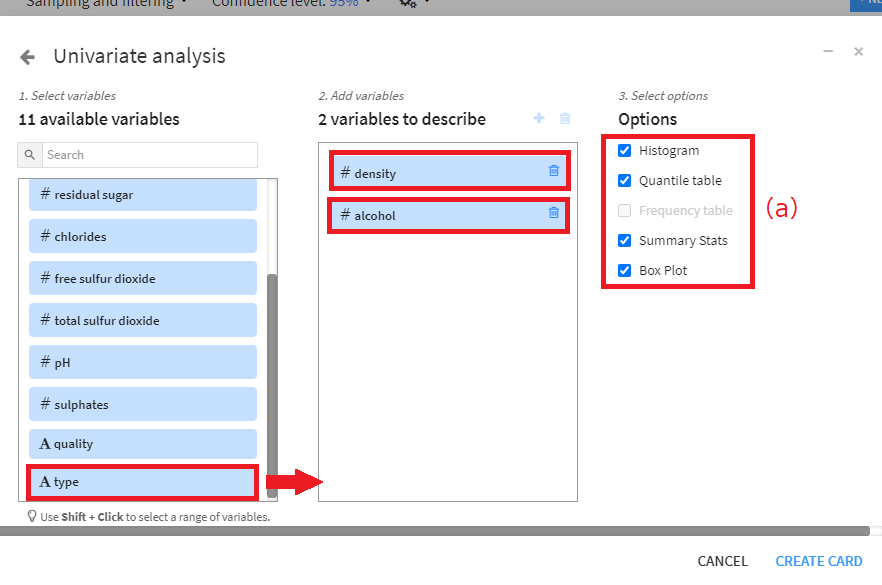
オプションは、量的変数(密度とアルコール)と質的変数(種類)に適したオプションが自動的に選択されます。必要に応じて、これらのオプションの選択は変更できます(上図(a))。
CREATE CARDをクリックすると、単変量解析が行われ、結果が表示されます。項目ごとに表示される図表は、量的変数か質的変数かによって異なります。量的変数の密度とアルコールではヒストグラムと箱ひげ図、分位表が表示され(下図(a))、質的変数の種類では棒グラフ、度数分布表が表示されます(下図(b))。

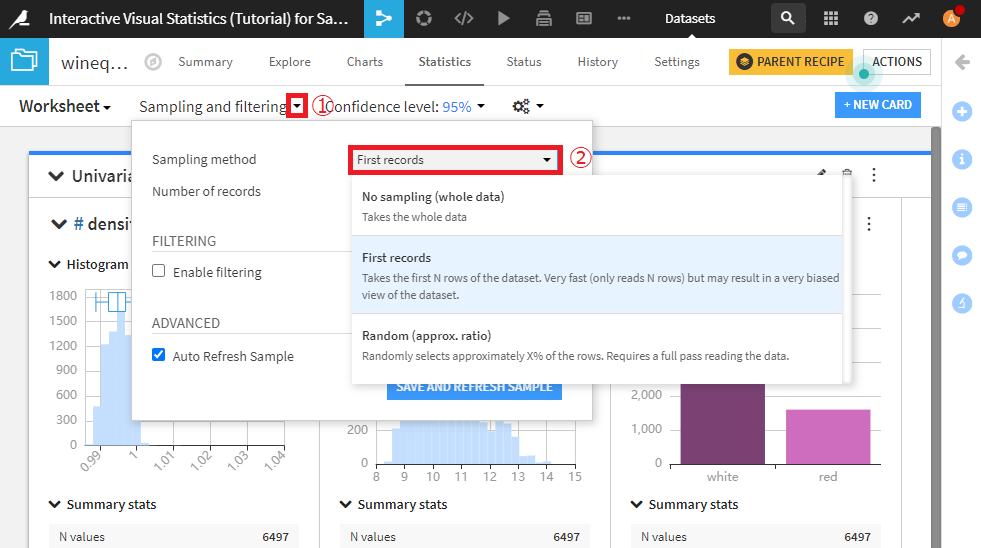
デフォルトでは、データセットの先頭10万行に対する結果を表示します。この設定はSampling and filtering横にあるドロップダウンから変更できます。
4. おわりに
単変量解析以外にも次のような解析がノンプログラミングで行えます。
- 二変量解析
- 曲線へのフィッティング度合の確認
- 相関行列の作成
- 主成分分析
- 仮説検定
興味を持たれた方は、ここを参照ください(今回の内容は、ここのUnivariate and Bivariate Analysisをベースに作成しました)。また、各解析で具体的に何ができるかについてはここが参考になります。