適切なタイトルをどうつけようか悩んだ。
Slack から Amazon Echo の Alexa を操作したいなぁと思って作った。
かれこれ作ってから1年くらい経ってしまったけど・・、ようやくアウトプット。
実現したいこと
- Slack のメッセージを RaspberryPi のスピーカーから音声として出力する
- RaspberryPi のマイクへの音声を Slack へメッセージとして送信する
先に結果
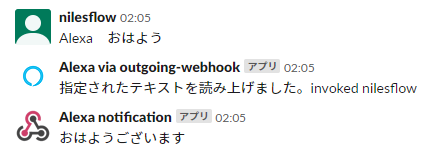
- Slack のメッセージをスピーカー再生ができた
- マイクの入力音声を、Slack のメッセージで通知できた
※ 相手が、Alexa を想定したイメージになっているが、実際に Amazon Echo は無いので、自分の声でテストしている
全体構成
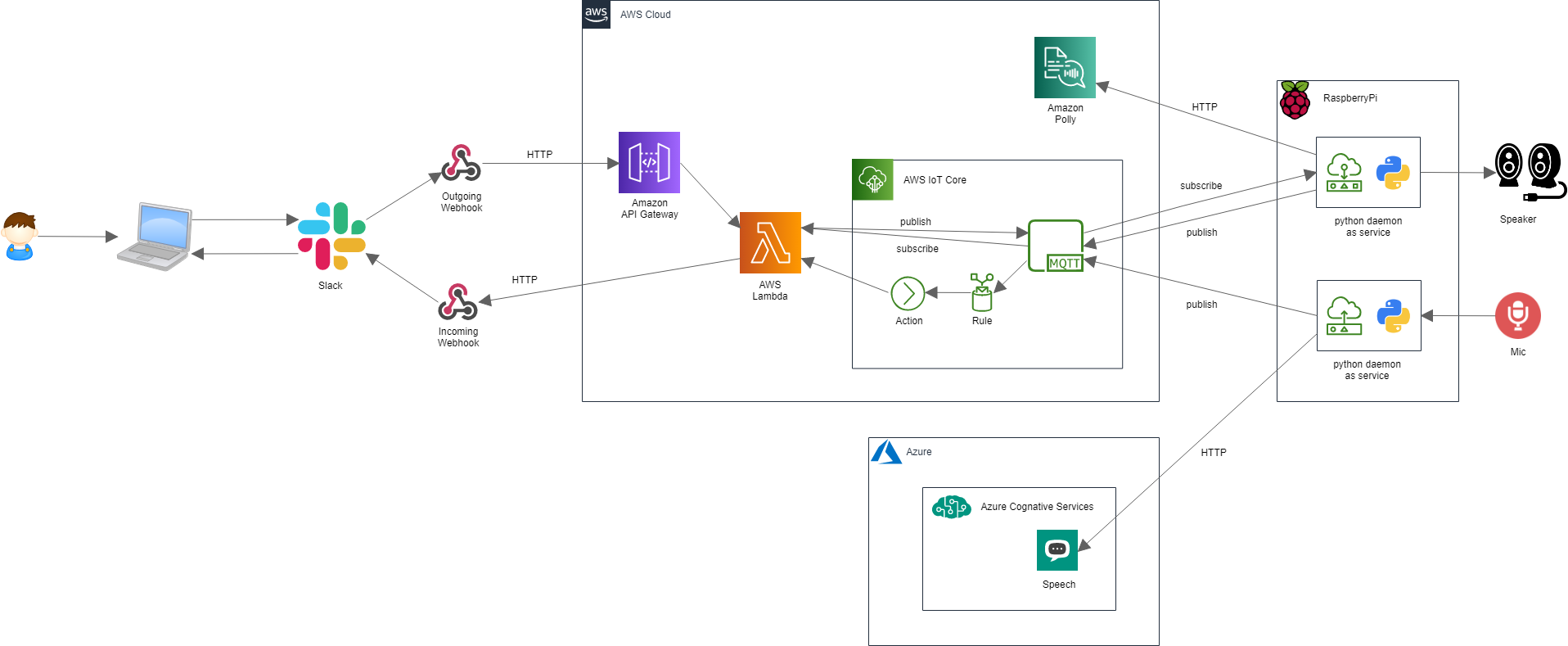
Slack to RaspberryPi
AWS を用いて構成する。
Slack の Webhook 受信に Amazon API Gateway を、
RaspberryPi との送受信には、AWS IoT Core を用いた。
MQTTトピック
Lambda → AWS IoT → RaspberryPi
下記のトピックを使用。
raspberrypi/request/#
テキスト→音声再生のトピックで通知。
raspberrypi/request/speak
RaspberryPi → AWS IoT → Lambda
下記のトピックを使用する。
raspberrypi/response
処理終了後 ACK メッセージを応答送信する。
RaspberryPi
python スクリプトをデーモン化し、systemd でサービス化。
RaspberryPi には、イヤホン端子スピーカを接続。
セットアップ
- config を設定
- AWS IoT Core の接続情報、SSL証明書を設定
- AWS Amazon polly のアクセスキー/シークレットキーを設定
処理の流れ
- paho ライブラリを使用して、AWS IoT Core へ MQTT subscribe
- MQTT メッセージ受信
- AWS SDK for Python boto3 を用いて、Amazon Polly でテキスト→音声変換
- 変換後の音声ファイルは、ファイルシステムに一時保存
- pyaudio ライブラリで、保存したmp3ファイルをスピーカー再生
- 再生待ち処理をスレッド化、再生終了後にコールバック
- 要求元の Slack 向けに、ACKメッセージを MQTT publish
- 音声再生終了コールバック処理で、録音プロセス向けに、録音開始指示を MQTT publish(後述)
Paho - Pyton MQTT Client
下記を参考に。
MQTT with AWS IoT Platform using Python and Paho
https://iotbytes.wordpress.com/mqtt-with-aws-iot-using-python-and-paho/
https://github.com/pradeesi/AWS-IoT-with-Python-Paho
Amazon Polly
synthesize_speech でテキスト→音声変換
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/polly.html#Polly.Client.synthesize_speech
response = self.client.synthesize_speech(
Text = text,
OutputFormat = 'mp3',
VoiceId = voice
)
Text には、Slack から 受信したメッセージを設定する。
mp3 生成処理は、下記を参考に。
https://dev.classmethod.jp/cloud/aws/change-polly-voice-using-boto3/
mp3 再生
mp3 の再生は下記を参考に。
https://deviceplus.jp/hobby/raspberrypi_entry_012/
python からの再生は下記を参考に。
https://qiita.com/Nyanpy/items/cb4ea8dc4dc01fe56918
Tips:pygame の再生終了待ちをスレッドで行う
下記等を参考にした。
http://d.hatena.ne.jp/kadotanimitsuru/20090216/thread
https://www.raspberrypi.org/forums/viewtopic.php?t=46096
ソースコード
下記に。
https://github.com/nilesflow/AwsIoTSpeaker/
AWS IoT
セットアップ
- RaspberryPi 用の things を作成
- 証明書を作成
- ダウンロードした証明書とroot証明書、エンドポイントを控えておく
Lambda
RaspberryPi と合わせて、Python で構築。
API Gateway からの要求を AWS IoT Core にMQTT送信。
応答メッセージを Slack へ返却するために、
Lambda 関数内でしばらく ACK 待ちを行っているのがポイント。
AWS IoT Core と 統合している訳ではないので、デプロイ時に MQTT 接続用のSSL証明書類をアップロードしている。
RaspberryPi からの通知でも同じ関数を使用しているので、処理分岐している。
セットアップ
- Lambda 関数をコンソール、または
- EC2 から AWS CLI でアップロード
- 環境変数
- SUBSCRIBE_HOST:AWS IoT Core のエンドポイント、
yourhostname.iot.region.amazonaws.com等 - SUBSCRIBE_CAROOTFILE:同ルート証明書、
certs/root-CA.crt等 - SUBSCRIBE_CERTFILE:同SSL証明書、
certs/certificate.pem.crt等 - SUBSCRIBE_KEYFILE:同SSL証明書鍵、
certs/private.pem.key等
- SUBSCRIBE_HOST:AWS IoT Core のエンドポイント、
処理の流れ
- API Gateway からリクエストを受信
- 呼び出し元が、Slack か RaspberryPi を判定
- paho ライブラリを使用して、AWS IoT Core へ MQTT subscribe (ACK 受信用)
- トピックは、
raspberrypi/response
- トピックは、
- paho ライブラリを使用して、AWS IoT Core へ MQTT publish
- トピックは、
raspberrypi/request/speak
- トピックは、
- ループ処理で sleep して、応答を待つ
- paho ライブラリで MQTT 応答メッセージ受信
- 正しい応答かどうかを確認
- API Gateway へ 応答メッセージを返却
- 応答メッセージは、slack 上にメッセージテキストとして表示される
- 例えば、
指定されたテキストを読み上げました。invoked xxxxxx
- 例えば、
応答について
API Gateway 側でプロキシ統合を選んだ場合は、Lambda 側で実装するが、
API Gateway 側で吸収させるなら、既定の形式で返す必要がある。
下記等を参考。
https://qiita.com/taknuki/items/dd47d1c6d4190b52df9a#%E3%83%AC%E3%82%B9%E3%83%9D%E3%83%B3%E3%82%B9
ソースコード
API Gateway
Slack の Outgoing Webhooks を受信可能なエンドポイントを定義する。
-
リソース
-
/raspberrypi/{proxy+}でリソース定義 - POST
-
-
メソッドリクエスト
- 認可:
AuthorizationRequestTokenで Lammbda 関数を利用 - リクエストの検証:クエリ文字列パラメータおよびヘッダーの検証
- APIキーの必要性:false
- URL クエリ文字列パラメータ:token を必須
- HTTP リクエストヘッダー:Content-Type
- 認可:
-
統合リクエスト
- 統合タイプ:Lambda
- Lambda プロキシ統合の使用:しない
- Lambda 関数は、上述の関数を指定
- URLパスパラメータ:
method.request.path.proxy - マッピングテンプレート
- リクエスト本文のパススルー:なし
-
application/x-www-form-urlencoded:ソースコード参照- Slack のPOSTパラメータから、Lambda の引数へのマッピングを行っている
-
統合レスポンス
- 200 のマッピングテンプレート
-
application/json:ステータスコードが 200 かどうかを判定する- Lambda の応答から、Slack への応答JSON形式へのマッピングしている
-
- 200 のマッピングテンプレート
-
メソッドレスポンス
- 応答を返却できるように下記のステータスコードを定義
- 200
- 400
- 500
- 応答を返却できるように下記のステータスコードを定義
-
ステージ作成
- 必要に応じて、
dev、prodを作成
- 必要に応じて、
-
オーソライザー
-
AuthorizationRequestTokenを作成- Lambda 関数:APIGateway-Authorization
- ソースコード参照
- IDソース:クエリ文字列:token
- 認可のキャッシュ:有効
- TTL(秒):300
- Lambda 関数:APIGateway-Authorization
-
-
カスタムドメイン名
- 必要に応じて作成
- ACM 証明書も配置する
ソースコード
https://github.com/nilesflow/RaspberryPiClient/tree/master/API_Gateway
https://github.com/nilesflow/RaspberryPiClient/tree/master/Lambda/APIGateway-Authorization
Slack Outgoing Webhooks
slack標準のOutgoing Webhookを使用。
セットアップ
- チャンネル:対象のチャンネルを指定
- 引き金となる言葉:「alexa,Alexa,ALEXA,アレクサ,あれくさ」等
- URL:API Gateway のエンドポイントと token を指定
https://{your domain}/raspberrypi/speak?token={your token}
- トークン:生成してURLパラメータに設定
- 説明ラベル:任意
- 名前をカスタマイズ:任意
- アイコンをカスタマイズする:任意
参考
送信 POSTパラメータ等、下記。
https://api.slack.com/custom-integrations/outgoing-webhooks
RaspberryPi to Slack
Azure と AWS を用いて構成する。
RaspberryPi から Slack への通知には、同じく、AWS IoT Core を利用している。
MQTTトピック
RaspberryPi → AWS IoT → RaspberryPi
下記のトピックを使用。
raspberrypi/request/#
音声録音のトピックで通知。
音声再生デーモン処理終了時に発行される。
raspberrypi/request/listen
RaspberryPi → AWS IoT → Lambda
下記のトピックを使用する。
raspberrypi/response
テキスト変換処理終了後 通知メッセージを送信する。
raspberrypi/notify
Slack Incoming Webhooks
slack標準のIncoming Webhookを使用。
セットアップ
- チャンネルへの投稿:対象の通知チャンネルを指定
- Webhook URL:生成、後ほど Lambda に入力
- 説明ラベル:任意
- 名前をカスタマイズ:任意
- アイコンをカスタマイズする:任意
参考
送信 JSON フォーマット等、下記。
https://api.slack.com/incoming-webhooks
Lambda
同じ関数を使用。
AWS IoT Core を通じた RaspberryPi からの MQTT メッセージを処理、
Slack Incoming Webhooks の URL へ送信する。
セットアップ
- 同じ Lambda 関数を使用
- 環境変数
- SLACK_WEBHOOK_URL:Slack の Webhook URL、上述。
処理の流れ
- AWS IoT Core から統合リクエストを受信
- 呼び出し元が、Slack か RaspberryPi を判定
- 指定の JSON 形式で、HTTP リクエスト送信
ソースコード
AWS IoT
セットアップ
- ACT を作成:RaspberryPiNotification
- ルールクエリステートメント:
SELECT * FROM 'raspberrypi/notify' - アクション:上述の Lambda 関数を指定
- エラーアクション:任意
Azure Speech Service
セットアップ
- Azure ポータル
- Cognitive Services から追加
- Speech を選択
- キーとエンドポイントを控えておく
RaspberryPi
python スクリプトをデーモン化し、systemd でサービス化。
RaspberryPi には、USBマイクを接続。
セットアップ
- config を設定
- AWS IoT Core の接続情報、SSL証明書を設定
- Azure Speech Service のアクセスキーを設定
処理の流れ
- paho ライブラリを使用して、AWS IoT Core へ MQTT subscribe
- 接続認証のため、AWS IoT Core で発行したSSL証明書を配置
- MQTT メッセージ受信
- 音声録音処理
- pyaudio ライブラリで音声録音
- 音を検知したら録音データ取得
- 無音が暫く続いたら、またはタイムアウトで終了
- wav ファイルを生成
- pyaudio ライブラリで音声録音
- 音声→テキスト変換処理
- cognitive-services の speech-service REST API をコール
- wav ファイル → テキスト変換処理
- cognitive-services の speech-service REST API をコール
- 結果を MQTT publish で AWS IoT Core へ送信
H/W情報
$ arecord -l
**** ハードウェアデバイス CAPTURE のリスト ****
カード 1: Device [USB PnP Sound Device], デバイス 0: USB Audio [USB Audio]
サブデバイス: 1/1
サブデバイス #0: subdevice #0
$ lsusb
Bus 001 Device 004: ID 8086:0808 Intel Corp.
Bus 001 Device 003: ID 0424:ec00 Standard Microsystems Corp. SMSC9512/9514 Fast Ethernet Adapter
Bus 001 Device 002: ID 0424:9514 Standard Microsystems Corp. SMC9514 Hub
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
$ cat /proc/asound/modules
0 snd_bcm2835
1 snd_usb_audio
$ amixer -c 1 sget Mic
Simple mixer control 'Mic',0
Capabilities: cvolume cvolume-joined cswitch cswitch-joined
Capture channels: Mono
Limits: Capture 0 - 16
Mono: Capture 0 [0%] [0.00dB] [on]
$ amixer -c 1 sset Mic 60%
Simple mixer control 'Mic',0
Capabilities: cvolume cvolume-joined cswitch cswitch-joined
Capture channels: Mono
Limits: Capture 0 - 16
Mono: Capture 10 [62%] [14.88dB] [on]
$ amixer -c 1 sget Mic
Simple mixer control 'Mic',0
Capabilities: cvolume cvolume-joined cswitch cswitch-joined
Capture channels: Mono
Limits: Capture 0 - 16
Mono: Capture 10 [62%] [14.88dB] [on]
参考
音声録音処理は、下記処理を参考にさせていただいた。
https://qiita.com/mix_dvd/items/dc53926b83a9529876f7
Azure Cognitive Services は、
https://docs.microsoft.com/ja-jp/azure/cognitive-services/speech-service/rest-apis
ソースコード
参考
こちらの方が簡単そう・・。
https://qiita.com/miya236a/items/4f56f5b3dd3d3e6a3f8e
こちらの方とは似てる気がします・・。
https://hacknote.jp/archives/39454/