内容
・趣旨目標
・参考サイト
・使用できるサービス
・概要理解
・やっていく
趣旨目標
AWSにおいてAIを活用したサービスをハンズオンを通じて理解する。
AI/ML サービスの全体感を掴む。なんなら業務改善も視野に入れたい。
参考サイト
使用するサービス
・Amazon Personalize
概要理解
最初にAI/ML サービスとは。
分かりやすい説明
https://www.ctc-g.co.jp/solutions/cloud/column/article/27.html
公式資料
https://aws.amazon.com/jp/builders-flash/202401/awsgeek-ai-ml-services/?awsf.filter-name=*all
超簡単にまとめると人工知能と機械学習を簡単に始められるサービス。と認識して進めます。
やっていく
Amazon Personalize
これは簡単に言うと、ユーザーの好みや行動履歴を分析するもの。
もっと簡単に言うと、ネット検索の中でおすすめが勝手に出てくる便利なものの原理と同じ!
・「amazon personalize データセット」で検索
https://docs.aws.amazon.com/ja_jp/personalize/latest/dg/datasets-schemas-overview.html
ここでは、誰が(メタ情報)、何を(アイテム情報)、いつ、何をしたなどのデータセット。
・「amazon personalize レシピ」で検索
https://docs.aws.amazon.com/ja_jp/personalize/latest/dg/working-with-predefined-recipes.html
次に、私なりの超簡単解説によると、「レシピに基づいて学習させて、最適解を出すもの。」と解釈しました。詳しくは公式を参照
・全体の流れ

1 データインポート。
2 サービスを作成
3 予測する。
流れとなります。
・ここで簡単に、Forcastとの違いについて触れます。
Forcastは、何が、どれだけ、売れるかを予測することに比べ、
Personalizeは、誰が、何をしたか、何をするか、を予測します。
組み合わせると怖いほど物が売れそうですね。。。
整理できたところで実際に作業します。
作業開始
・ハンズオンのためのデータをダウンロードする。
(途中で使用するバケットポリシーや仮想的なデータがあります。)
・S3から設定していく。
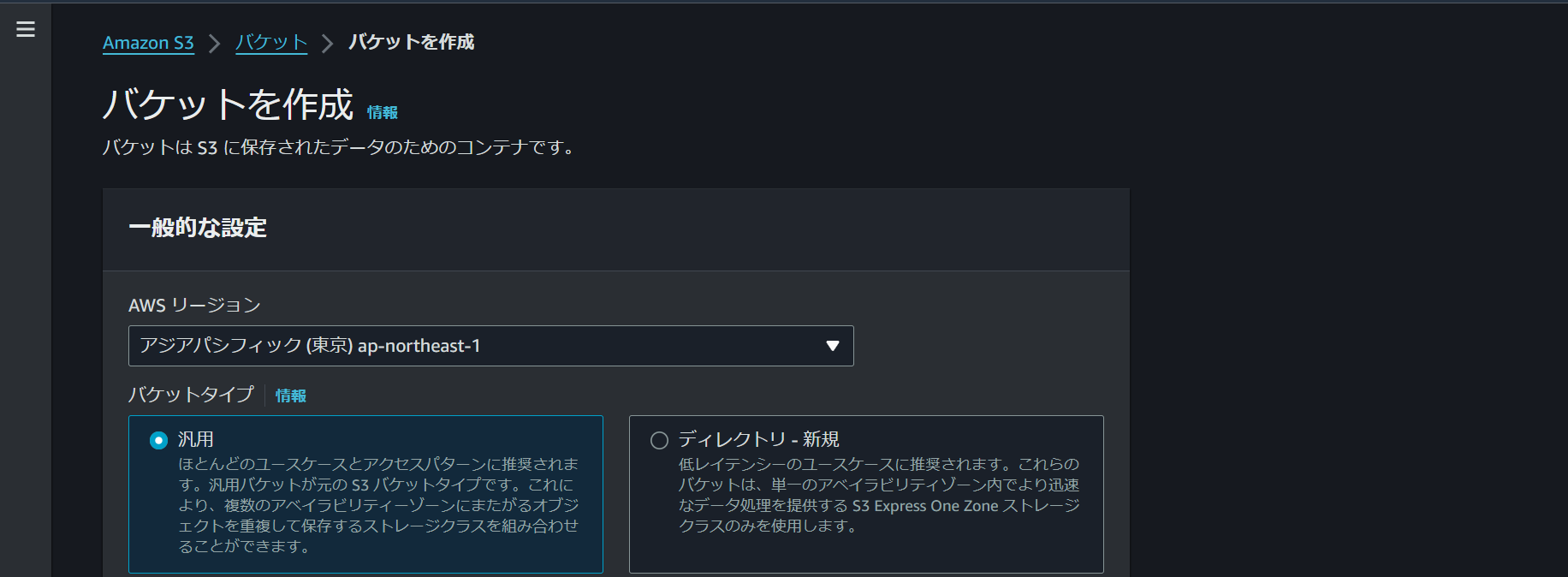
一意のネームを付ける。
データの前処理を行います。決まった形にするのが基本です。
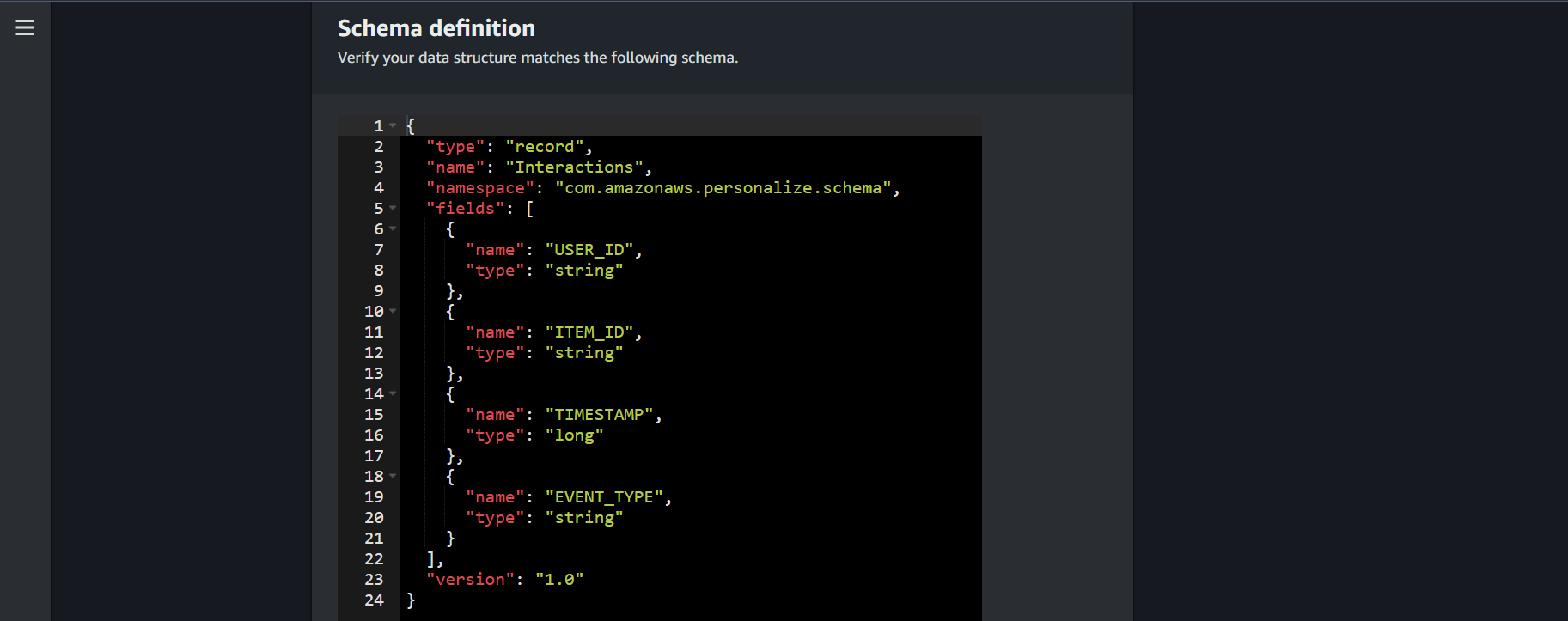
公式さんが作成したデータをコンソール上で設定するスキーマと整合させます。
1 EVENT_TYPEのカラムを追加する。
2 適当なビデオ視聴状況を入力する。
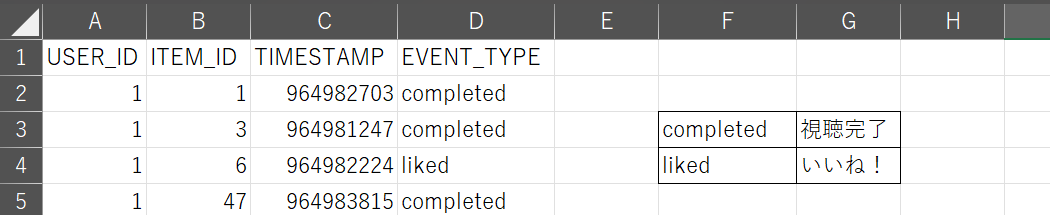
S3にデータをアップロードする。


IAMポリシー・ロールを作成します。

公式さんが作成したバケットポリシーはハンズオンデータに存在しますが、PersonalizeからS3にアクセスするための権限が不足するため、手作業で作ります。
ポリシー作成
ナビゲーションバーから、ポリシーを先に作成していきます。
JSONをクリックし、次のポリシーを記載ペーストします。
https://docs.aws.amazon.com/ja_jp/personalize/latest/dg/granting-personalize-s3-access.html
バケット名は任意(bucket-name)です。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::bucket-name",
"arn:aws:s3:::bucket-name/*"
]
}
]
}

ロール作成

エンティティは「AWSのサービス」、ユースケースは「personalize」。
先程作成したポリシーを検索してアタッチしていく。その他は触りません。

次はS3のバケットポリシーを設定します。
personalizeからS3への接続は設定しましたが、S3側の設定をしていないので、設定します。
https://repost.aws/ja/knowledge-center/personalize-import-insufficient-privileges-s3-error
バケット名は書き換えてポリシーを追加しましょう。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::DOC-EXAMPLE-BUCKET",
"arn:aws:s3:::DOC-EXAMPLE_BUCKET/*"
]
}
]
}

personalizeの設定
オレンジのボタンから開始します。

ナビゲーションバーの「create dataset group」をクリック。
任意の名前を付けて、ドメインはビデオを選択します。データ型が決まっているので、選択を失敗すると手戻りが発生しちゃいます。

再びオレンジのボタンから「iteminterractions dataset」をクリック。
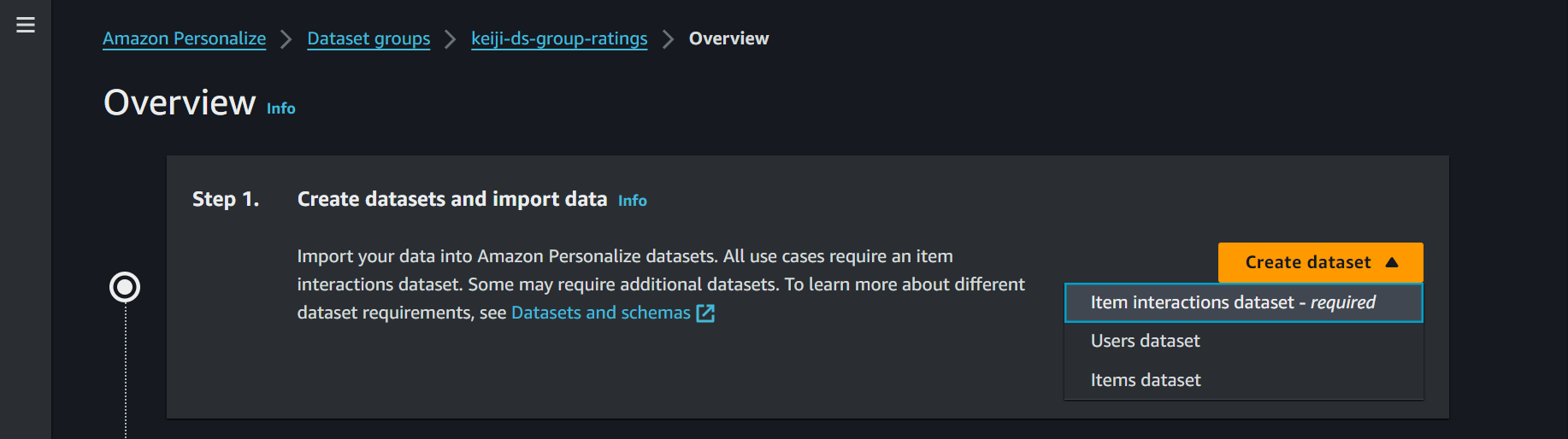
直接インポートを選択します。

データセットの名前を付けて、新たにスキーマを作成します。
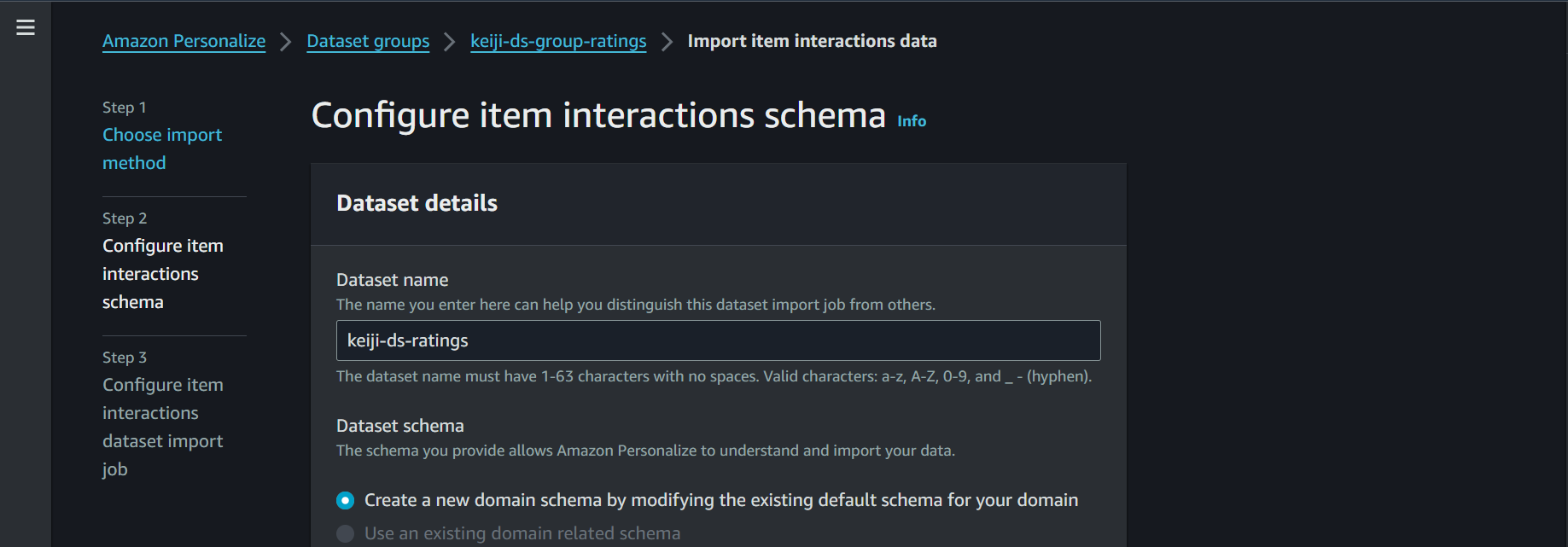
スキーマはデフォルトで大丈夫です。CSVデータをスキーマの定型に合わせているためです。

次にjob名を決めます。
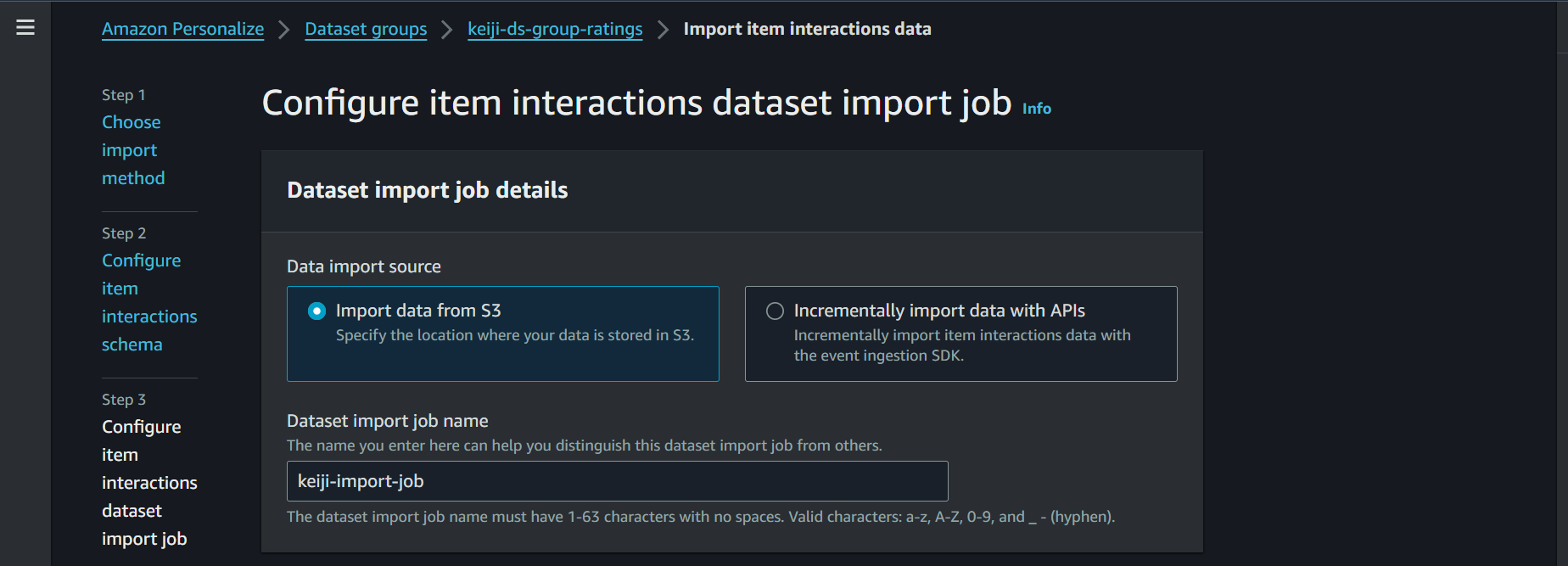
そして、S3の画面からオブジェクトのURIをコピーしてきて、personalizeの画面に貼り付けます。


IAMロールを選択します。先程作成したロールをアタッチします。
IAMの画面からARNをコピーしてきて、personalizeの画面に貼り付けます。
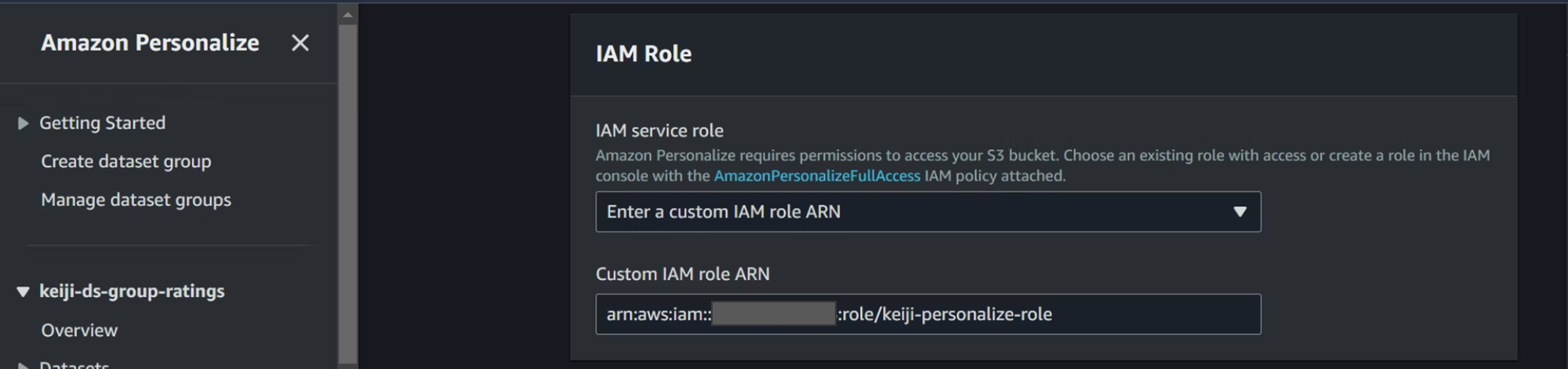
そしてインポートを開始します。

ソリューションを設定していきます。
ナビゲーションバーの下の方の「Solutions and recipes」をクリック。
「create solution」から設定を開始します。

https://docs.aws.amazon.com/personalize/latest/dg/customizing-solution-config.html
https://docs.aws.amazon.com/personalize/latest/dg/native-recipe-new-item-USER_PERSONALIZATION.html#user-personalization-features
今回はユーザーが何をしたいかを知りたいこともあるので、「User-Personalization」を選択します。
補足としてオプションが充実しているようです。




キャンペーンを設定していきます。

最終的な予測する工程に入っていきます。名前を決めて、先程作成したソリューションを選択し、推奨設定のバージョン(今は1つしかない。)を入力します。

スループットによって自動的にスケールするようです。ミニマム1ということ。

ここはおすすめをどれくらい推すかの設定。デフォルトでいきます。

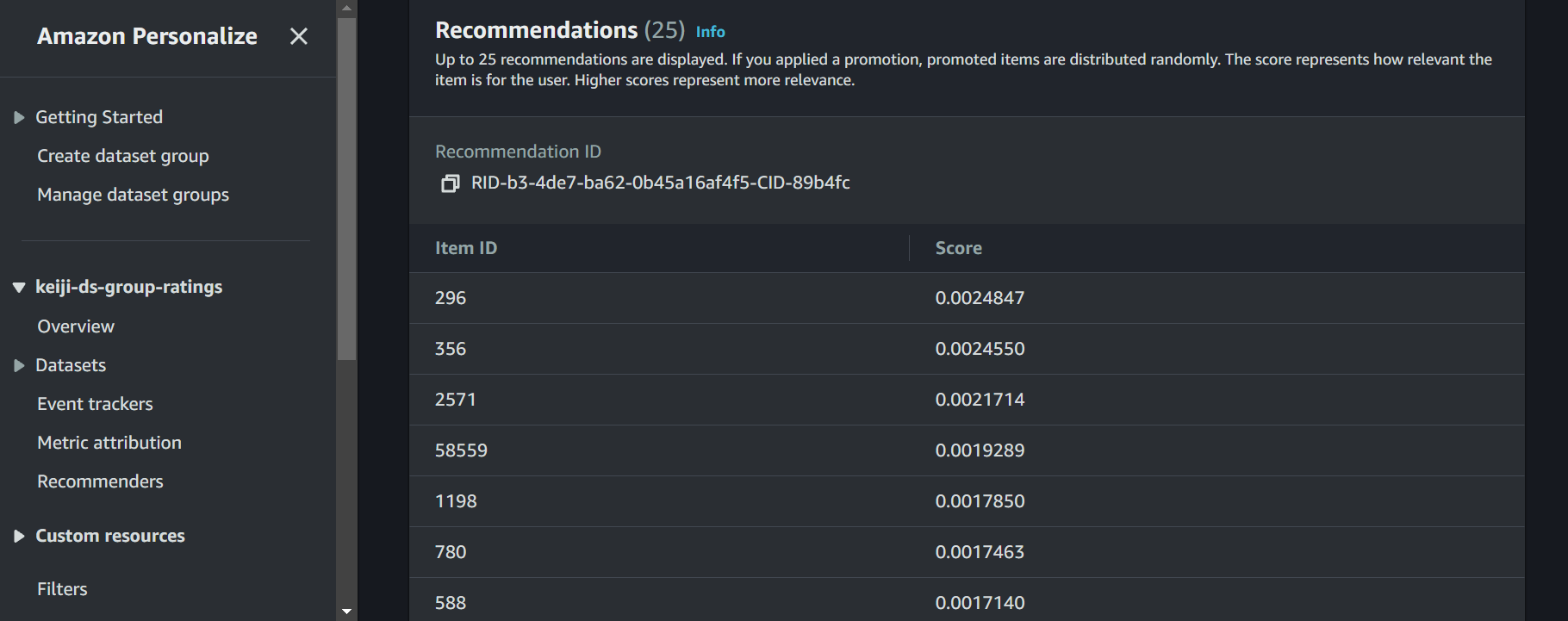
作成ができたら、実際にコードではなく、コンソールで試すことができます。
画像の例であると5番さんに上から順番におすすめの映画が表示されています。

ここまで基本的な設定はできましたが、もしチューニングする場合は、次の公式サイトを活用する。
https://docs.aws.amazon.com/ja_jp/personalize/latest/dg/working-with-training-metrics.html
一口メモ(CloudShellでのリソース削除)
なんせ動きがもっさりしています。エラーを出してしまうと再び作り直すのに時間がいくらあっても足りません。こういった時に以下のコマンドをお試しください。
personalizeにおいてデータセットグループを作成してすぐに削除を使用とすると、次のようなエラーが出ます。画面上で作成が完了していても、実際は作成に数十分かかります。

最初に次のコマンドで消したいデータセットのARNを確認します。そのために、データセットグループのARNから調べます。
aws personalize list-dataset-groups
そして、次のコマンドでデータセットのARNを調べます。
aws personalize list-datasets --dataset-group-arn <データセットグループのARN>
データセットを削除します。
aws personalize delete-dataset --dataset-arn "<データセットのARN>"
次にスキーマを探します。
aws personalize list-schemas
スキーマを削除します。
aws personalize delete-schema --schema-arn "スキーマのARN"
次に削除したいデータセットグループのARNを探します。
aws personalize list-dataset-groups
見つけたら消します。
aws personalize delete-dataset-group --dataset-group-arn "<データセットグループのARN>"
リソースの削除
ハンズオンが終了しましたので、通常の削除方法を記載します。
1 Campaignsを削除します。(10分以上かかります。)
ここでしっかり時間をかけることで、以降の削除でエラーが出にくいです。
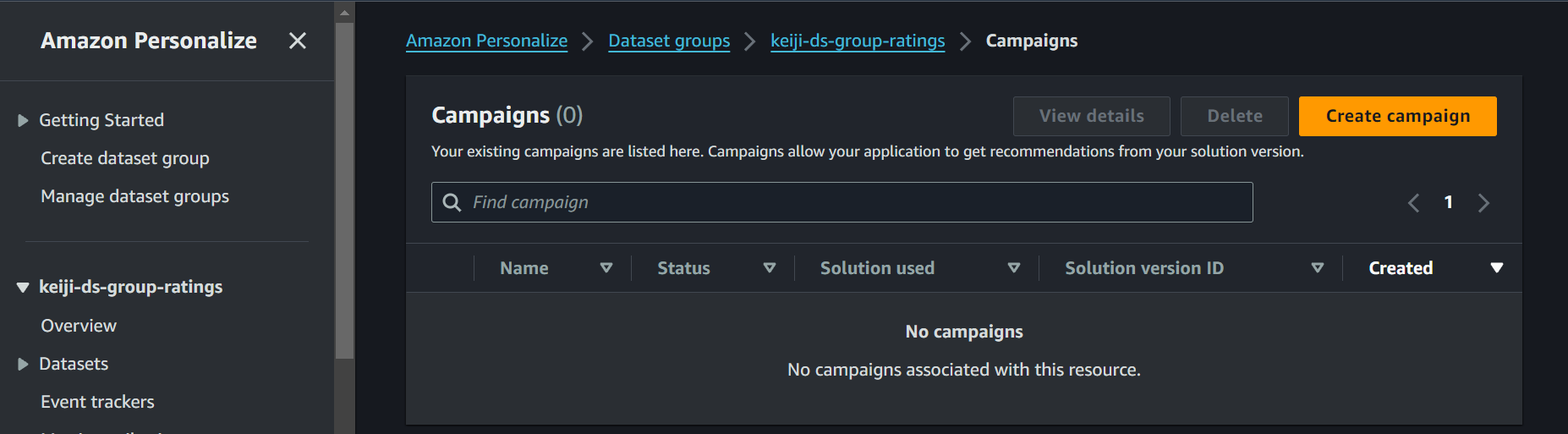
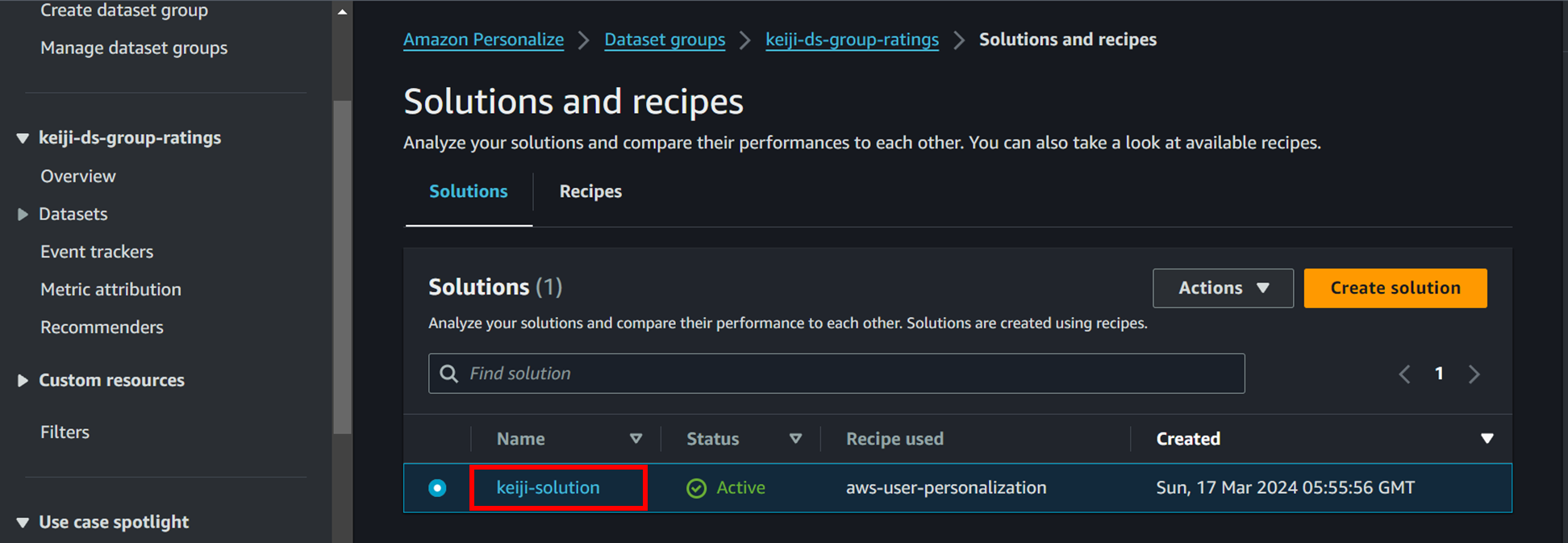
2 Solutions and recipesを削除します。
赤枠をクリックした後の画面で削除を行います。

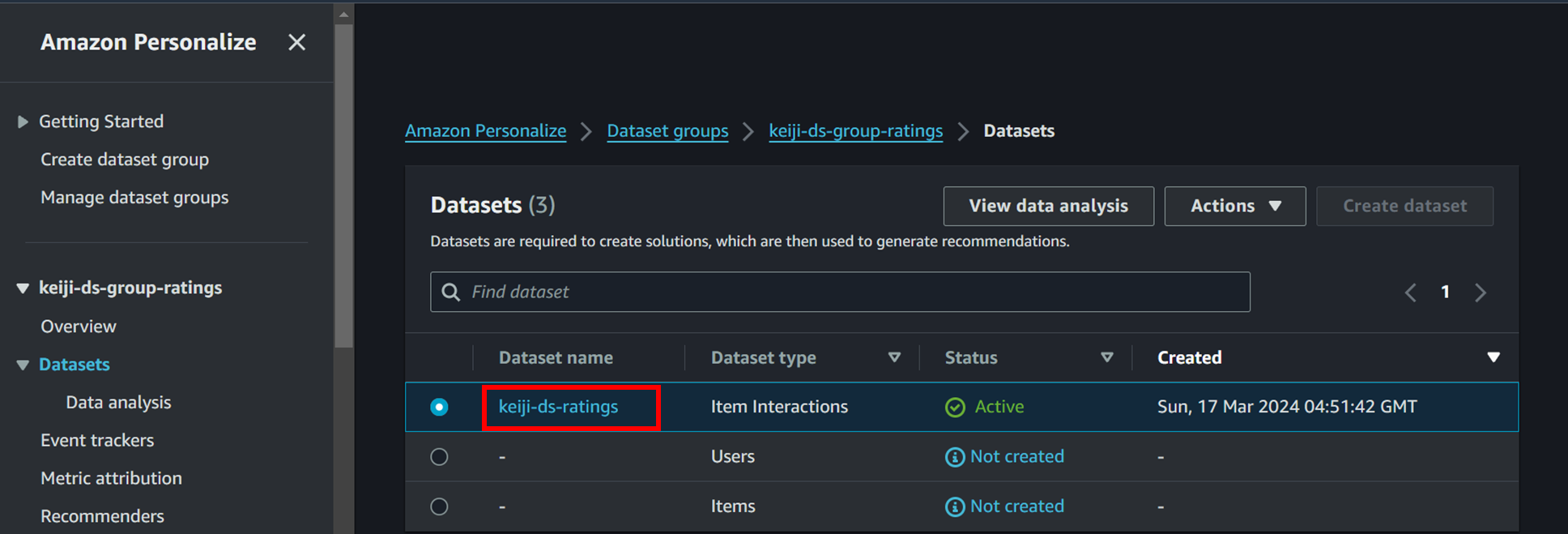
3 Datasetsを削除します。
赤枠をクリックした後の画面で削除を行います。
4 Manage dataset groupsを削除します。

5 S3バケットを削除します。
空にしてから、削除ですね。


凄く勉強になりました。普段接しているおすすめ機能がこのようなアルゴリズムで作られていて、実際に活用されているのが驚きと感動があります。使いこなすまで専属で扱うくらいしないと、実用性が低いかなと感じました。
全般最近行ったハンズオンで一番エラーがきつかったように思います。動作が遅いために、CloudShellで削除したりと、勉強にはなりました。
では!