はじめに
開発中盤で AppSync で開発している最中に追加したデータが、
突然 List Query で取得出来ない事態が発生しました... ![]()
調査したところ、
AppSync のデータソースで DynamoDB のデータソース生成した際に GraphQL を自動生成したのですが、
そこにヒントがあることを発見しました![]()
結局の所、DynamoDB への理解不足で片付く話なのですが、、
何となく AppSync を使っていると遭遇してしまう問題だと思います... ![]()
そこで、同じ問題で悩む人を助けられればと思い、
記事に残しておくことにしました ![]()
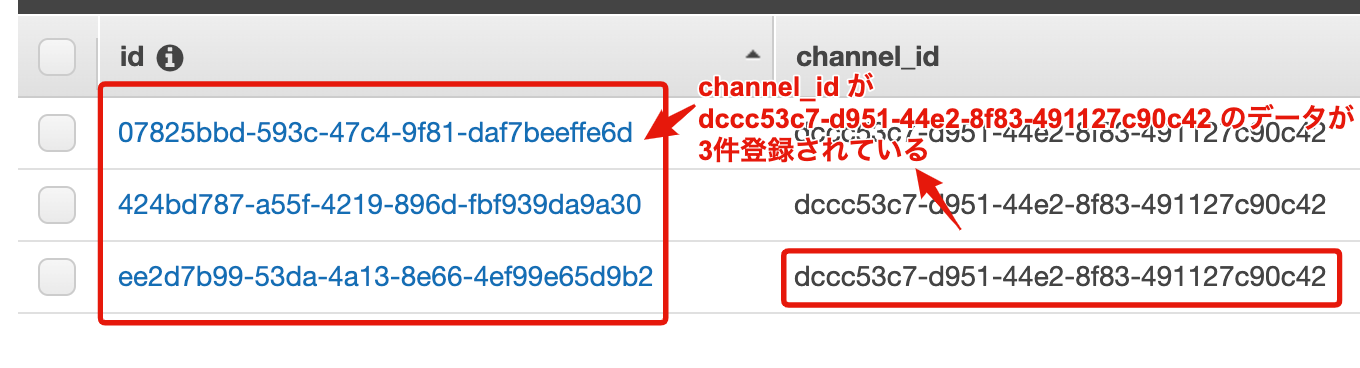
DynamoDB に登録されているはずのデータが AppSync の List Query で取得したデータに含まれない事象が発生することがある
AppSync で開発を開始した直後や、
登録データ数が少ない間は List Query の filter を用いてデータの絞り込みを行いつつ、
正常に意図したデータが取得出来るはずです ![]()
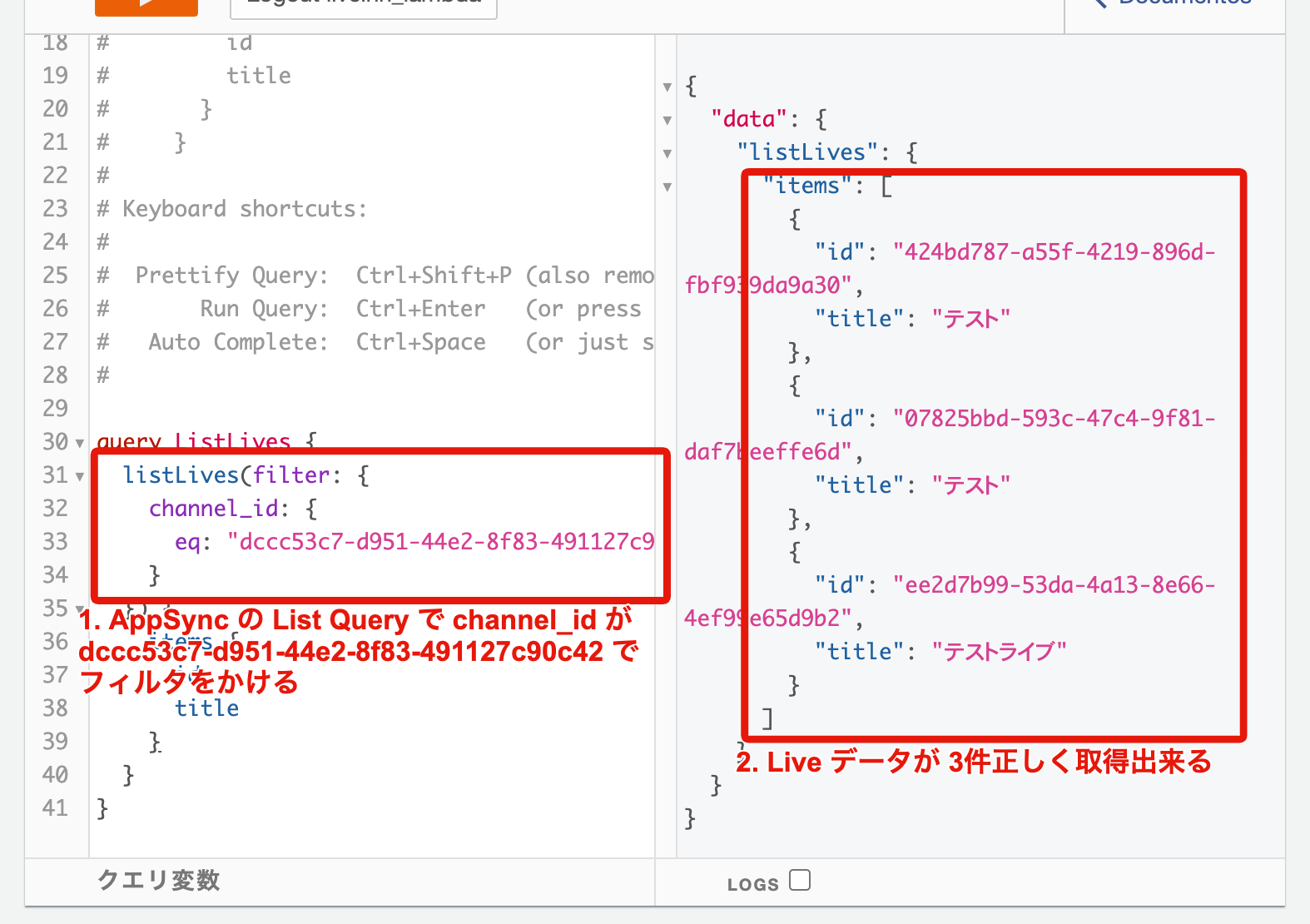
しかし、ある日 DynamoDB にデータが登録されているのに List Query の filter で、
正常に意図したデータが取れない事象が特定の List Query で発生するようになってしまいました... ![]()

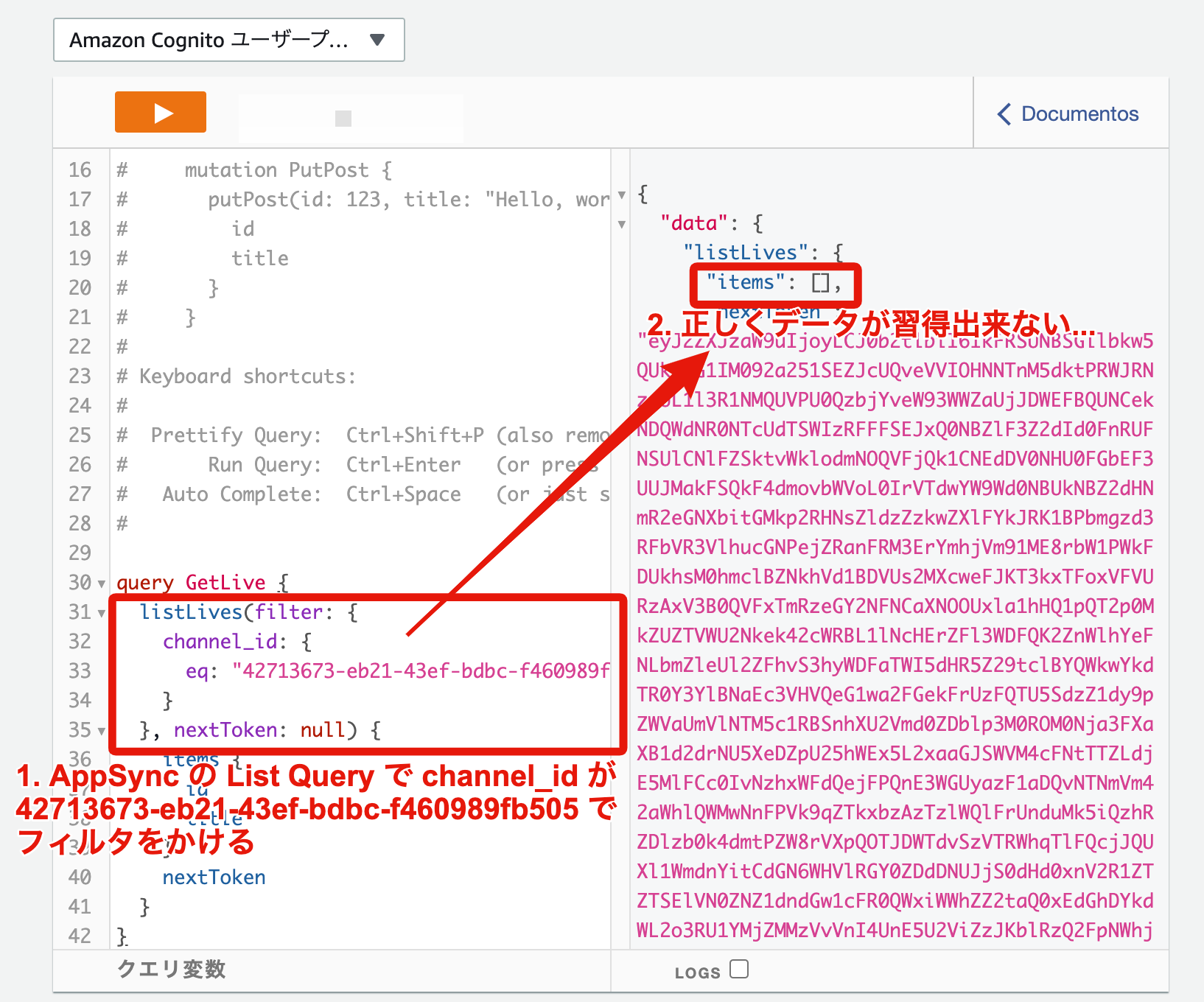
DynamoDB には channel_id が 42713673-eb21-43ef-bdbc-f460989fb505 でデータが 1件登録されていることは確認済みなのに AppSync の List Query では 1件も取得できないのは何故でしょうか。。??![]()
DynamoDB データソース追加時に自動生成されたリゾルバを確認してみる
DynamoDB のデータソース登録時に自動で GraphQL 生成にチェックを入れていれば、
AppSync の List Query は自動生成され DynamoDB リゾルバが登録されています ![]()
原因調査のため AppSync の裏の DynamoDB リゾルバが何を行っているか中を覗いてみます ![]()
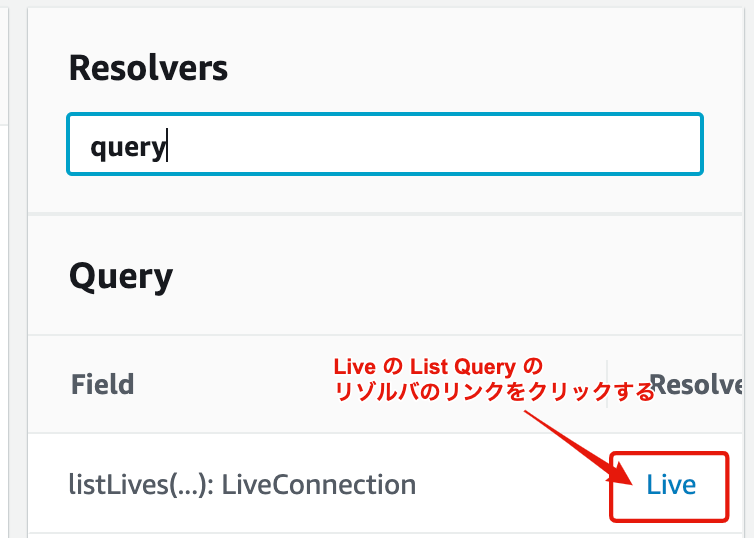
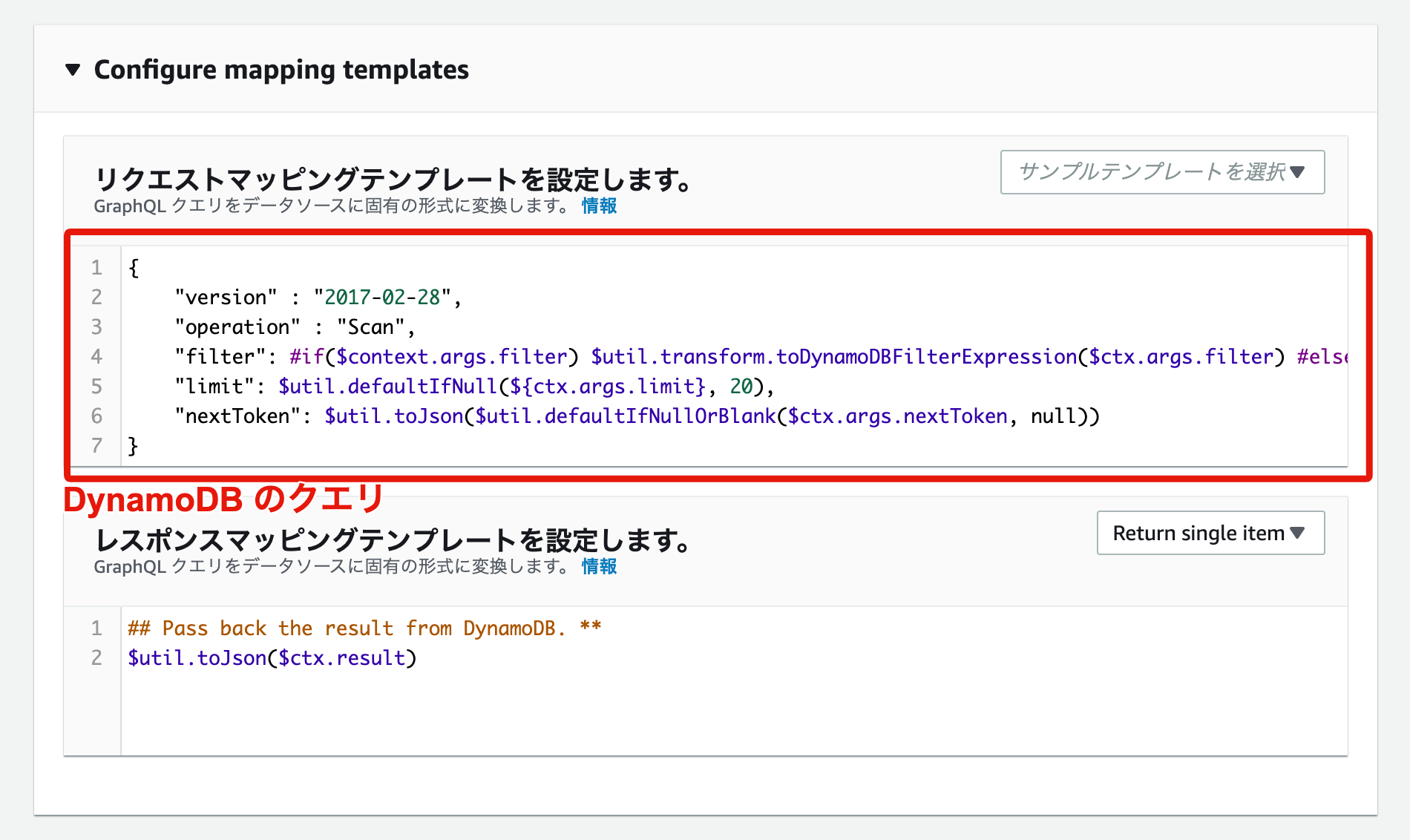
![]() を見ると、
を見ると、Scan を用いて filter で検索条件を絞って limit で指定した件数のデータが取得出来るようになっているように見受けられます ![]()
DynamoDB の Scan の仕様を確認する
次に DynamoDB の公式ドキュメント を見て Scan の仕様について確認していきます。
早速公式ドキュメントのトップに Scan についての説明が記載されていました ![]()
Amazon DynamoDB での Scan オペレーションは、テーブルまたは セカンダリインデックス のすべての項目を読み込みます。デフォルトでは、Scan オペレーションはテーブルまたはインデックスのすべての項目のデータ属性を返します。
![]() を見ると
を見ると Scan はデフォでレコードを全件取得するような挙動となるようです。
結果セットの項目数の制限
ドキュメントを読み進めていくと、
次に 結果セットの項目数の制限 の項目が目に止まりました ![]()
ここで、Scan にフィルタ式を追加するとします。この場合、DynamoDB は返される 6 つの項目にフィルタ式を適用し、一致しない項目を廃棄します。最終的な Scan 結果はフィルタリングされる項目の数に応じて、6 つ以下の項目を含みます。
![]() を見ると
を見ると Scan の filter を使用した際の挙動として 一致しない項目を廃棄します とあります ![]()
AppSync の DynamoDB リゾルバを確認した際、Scan の limit はデフォでは 20 でした。
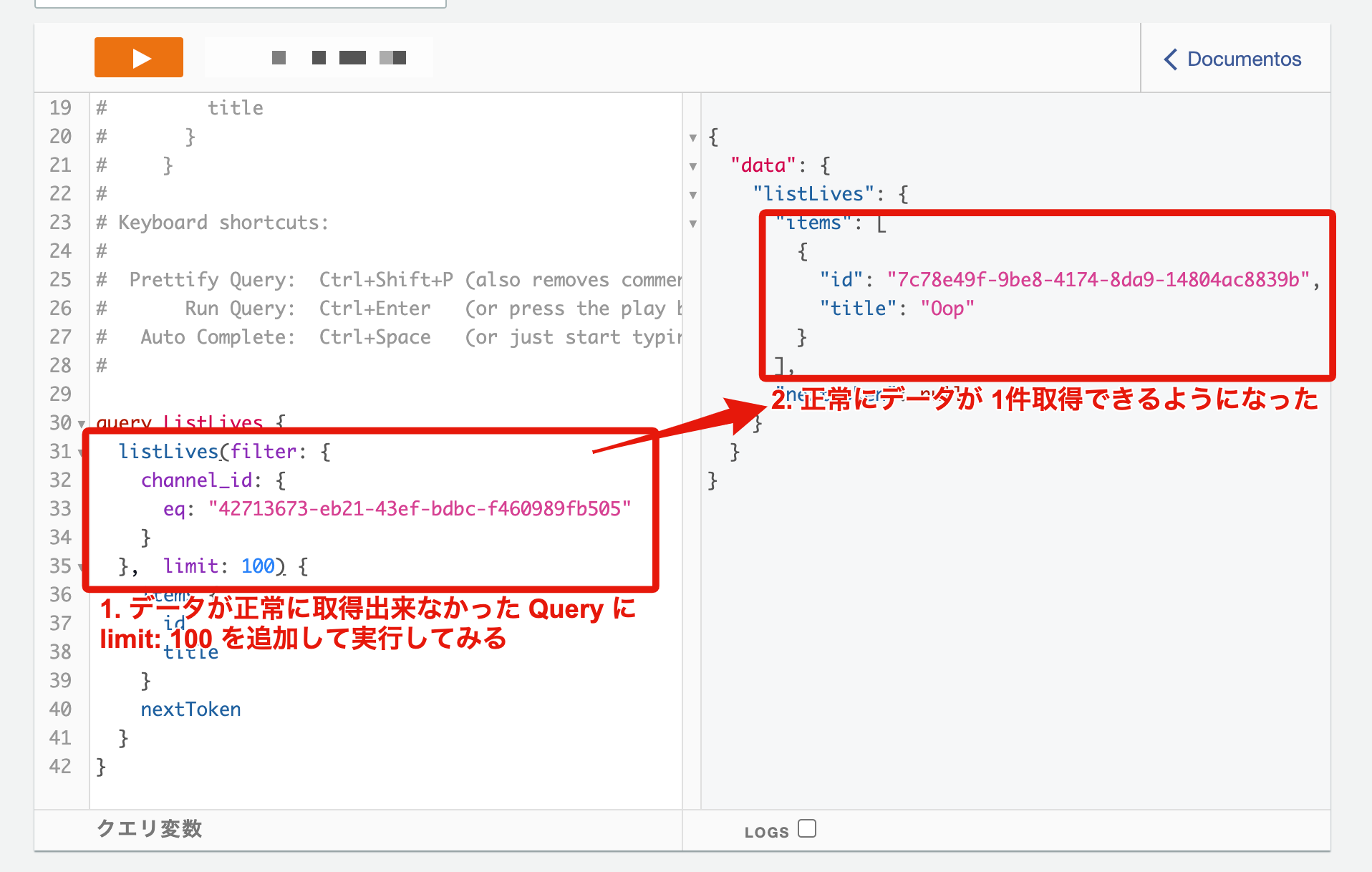
つまり、正常にデータが取得出来なかった AppSync の List Query を元に、
実際に実行された DynamoDB の Scan の挙動を推測すると、
データを 20件取得した中に該当する channel_id のデータが見つからなかったので空を返した
という挙動になりそうです ![]()
RDBMS の SQL の Where 句のような、
該当する channel_id のデータを 20件まで検索して取得する
という挙動を想定していましたが、それがそもそもの誤りだったようです... ![]()
スキャンの読み込み整合性
更にドキュメントを読み進めていくと スキャンの読み込み整合性 という項目も発見しました ![]()
Scan オペレーションは、結果的に整合性のある読み込みをデフォルトで行います。つまり、Scan 結果が、最近完了した PutItem または UpdateItem オペレーションによる変更を反映しない場合があります。詳細については、「Read Consistency」を参照してください。
強力な整合性のある読み込みが必要な場合は、Scan が開始する時に ConsistentRead パラメータを true リクエストで Scan に設定できます。これにより、Scan が開始する前に完了した書き込みオペレーションがすべて Scan 応答に含められます。
![]() を見ると RDBMS では保証されている一貫性は無いので、
を見ると RDBMS では保証されている一貫性は無いので、
Scan を実行するタイミングによって取得可能なデータは変動する可能性がある
ということを Scan を用いたデータ取得を行う際は考慮する必要がありそうです ![]()
対策方法
まず、AppSync の limit がデフォで 20 なので GraphQL クエリの limit を 100 等の、
一度の Query で filter で絞り込むデータが十分に取得出来そうな数に設定しておきます1 ![]()
また、Web アプリケーション等でよく使用される、画面最下部までスクロールした際にロードを行う処理の実装等を考慮した場合、nextToken を用いたページネーションの実装も考慮しておく必要があります ![]()
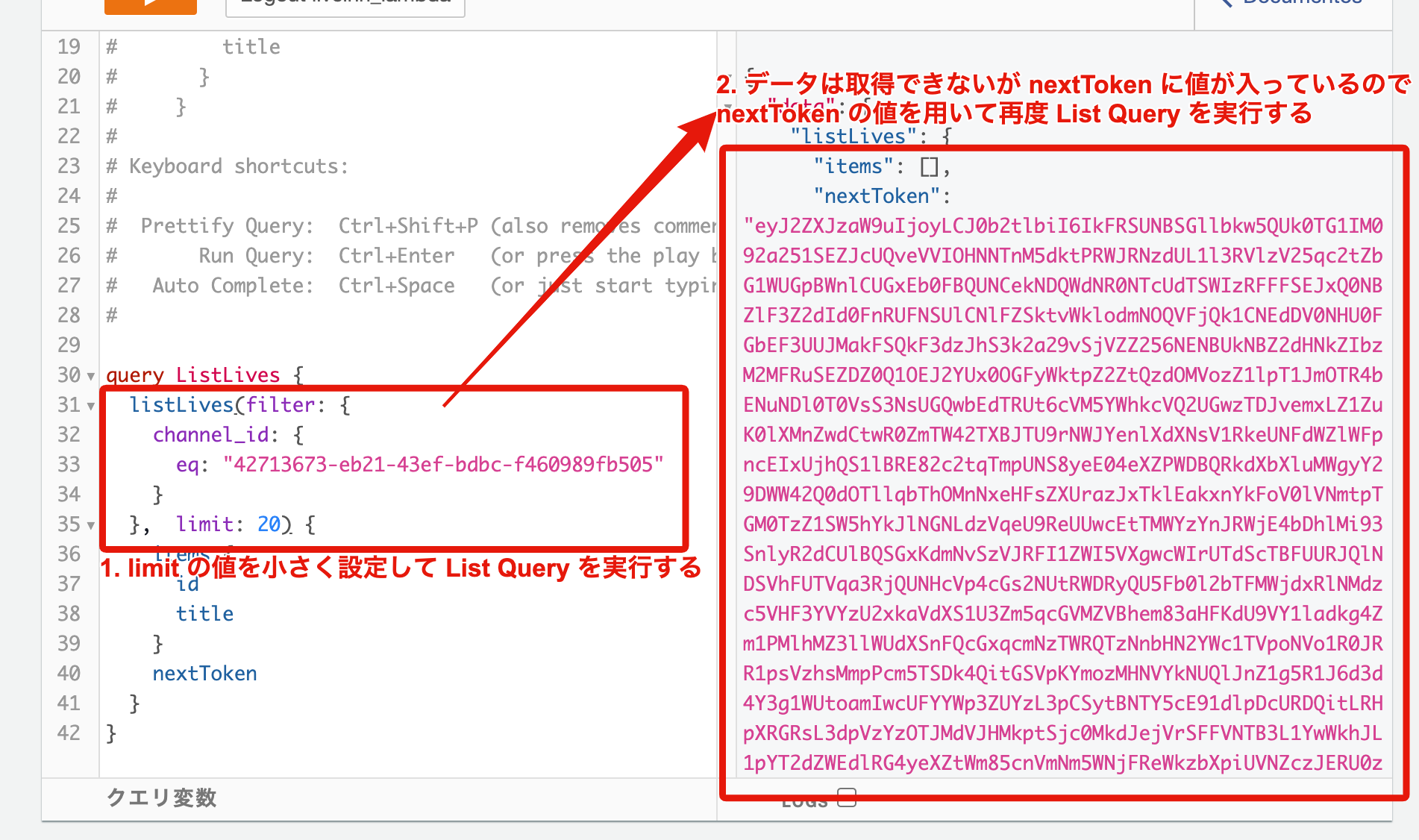
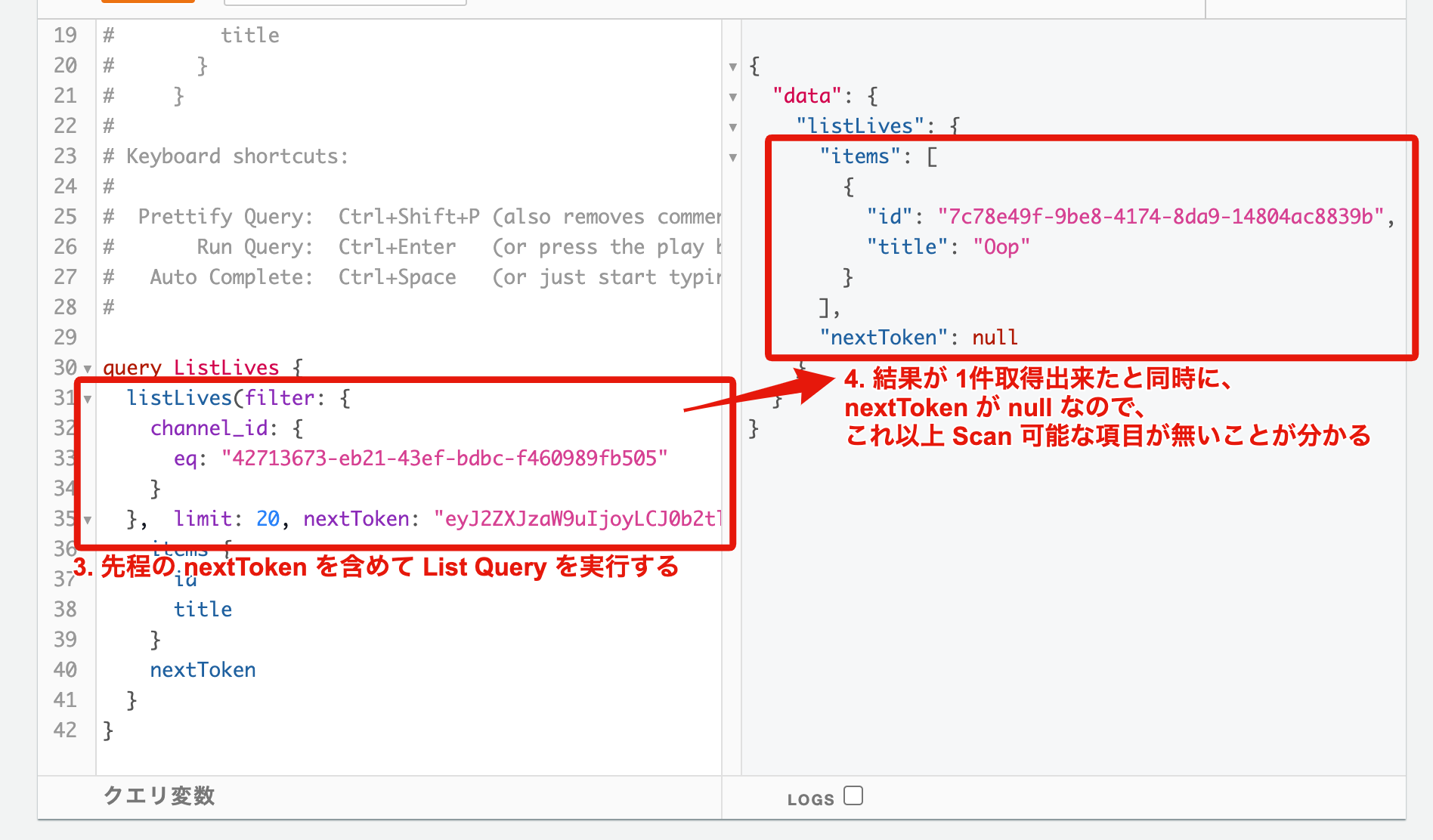
![]() の流れで List Query を実行するようにしておけば、
の流れで List Query を実行するようにしておけば、
画面最下部までスクロールした際のロード処理が実装可能です ![]()
おわりに
結果 AppSync というよりも DynamoDB の仕様にフォーカスに当たった記事内容になりました ![]()
AppSync の DynamoDB リゾルバを雰囲気で扱っていたため起きた問題で、
ステージング環境で実際にデータがある程度追加されてきてから問題が発覚したため、
個人でデバッグしているときには全く気づくことが出来ませんでした... ![]()
![]()
また保守運用の観点から予め DynamoDB の設計についても考慮しておいたほうが良いと思われます ![]()
公式ドキュメントに DynamoDB の設計のベストプラクティス についての解説ページがあるので読んでおいた方が良さそうです ![]()
以上 AppSync を用いる際に DynamoDB リゾルバを自動生成して利用する際は十分にご注意ください ![]()
参考リンク
- DynamoDB のリゾルバーのマッピングテンプレートリファレンス - AWS AppSync
- DynamoDB でのスキャンの使用
- Amazon DynamoDBのNextTokenを使ったページネーションの挙動を調査した
- DynamoDB を使用した設計とアーキテクチャの設計に関するベストプラクティス
-
大量のデータが登録されている状況であれば
Scanの Query からlimitは無くしてしまい、一度の Scan で最大の 1.0MBまでのデータを取得するようにして良いかも知れません ↩