内容
AWS Athenaへ用意されているテーブルのデータを、SQLを使って取得できるよう目指す方向け「Vol.2」です。
その他ボリューム
練習用データ
練習用データはこちらの3つのテーブルを用います。
Athenaコンソール上で実行すると作成できます。
複数検索
IN句を使うと、条件を複数書くことができます。
いずれかの条件に合致していれば取得できます。
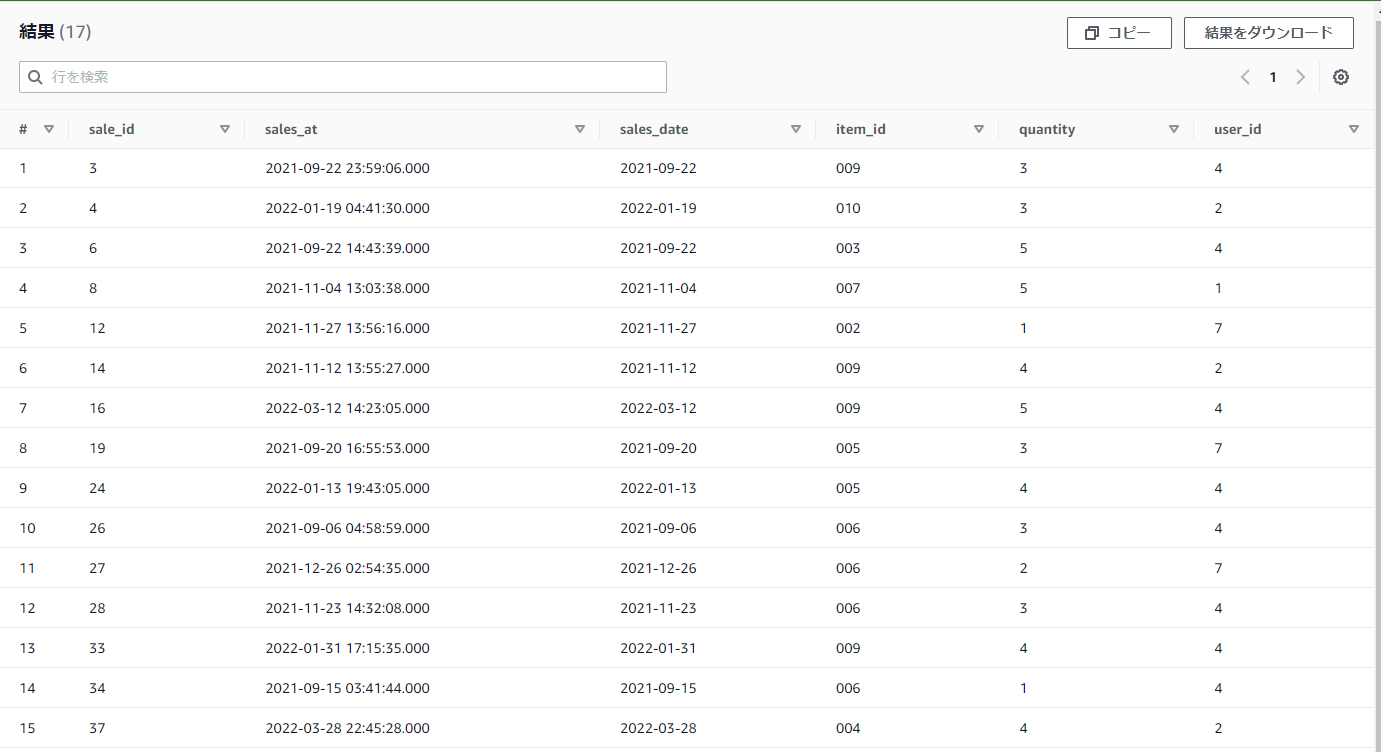
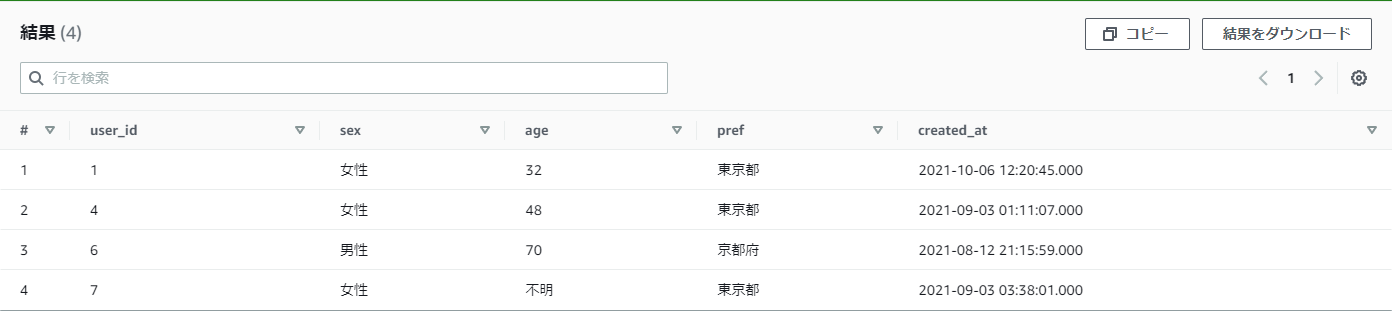
【例】practice_userテーブルから、pref(都道府県)が東京都もしくは大阪府もしくは京都府のデータを取得したい
SELECT
*
FROM
practice_user
WHERE
pref IN ('東京都', '大阪府', '京都府')
結果
条件が沢山ある場合は、ORを使わずに、IN句にして書くと良いと思います。
あいまい検索
LIKE句を使うと、部分的に一致するデータを取得することができます。
前方一致
LIKE 'ほにゃらら%'とすると、ほにゃららの後に何かしらついていても、最初にほにゃららがついている行を取得してくれます。
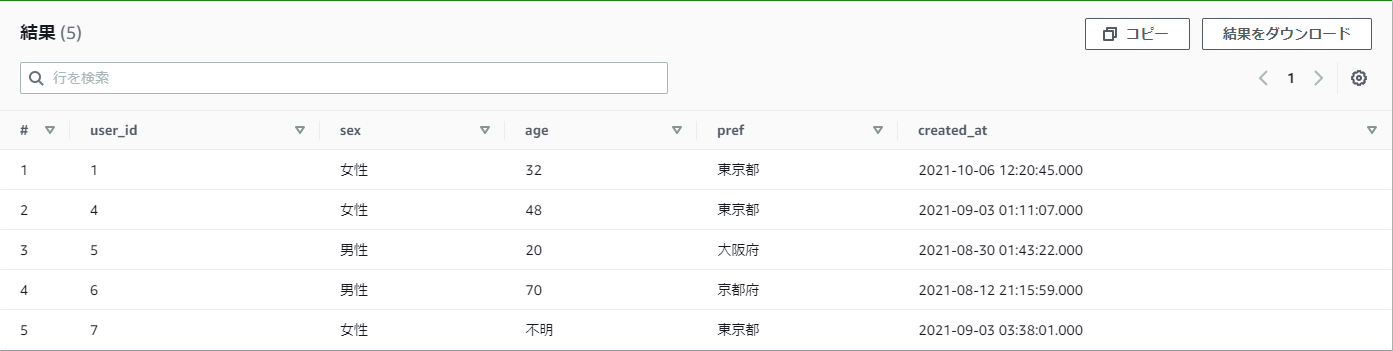
【例】practice_userテーブルからsex(性別)の最初に「男」が付くデータを取得したい
SELECT
*
FROM
practice_user
WHERE
sex LIKE '男%'
結果
後方一致
LIKE '%ほにゃらら'とすると、ほにゃららの前に何かしらついていても、最後にほにゃららがついている行を取得してくれます。
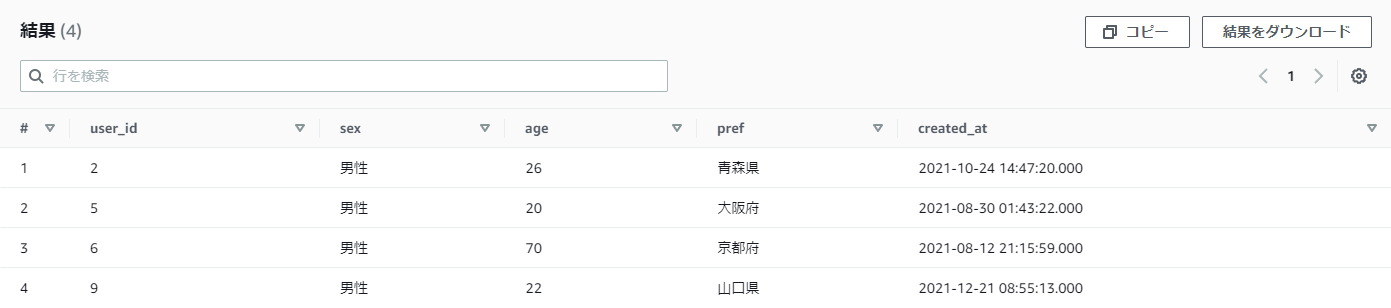
【例】practice_userテーブルからpref(都道府県)の最後に「県」が付くデータを取得したい
SELECT
*
FROM
practice_user
WHERE
pref LIKE '%県'
結果
部分一致
LIKE '%ほにゃらら%'とすると、データにほにゃららが含む行を取得してくれます。
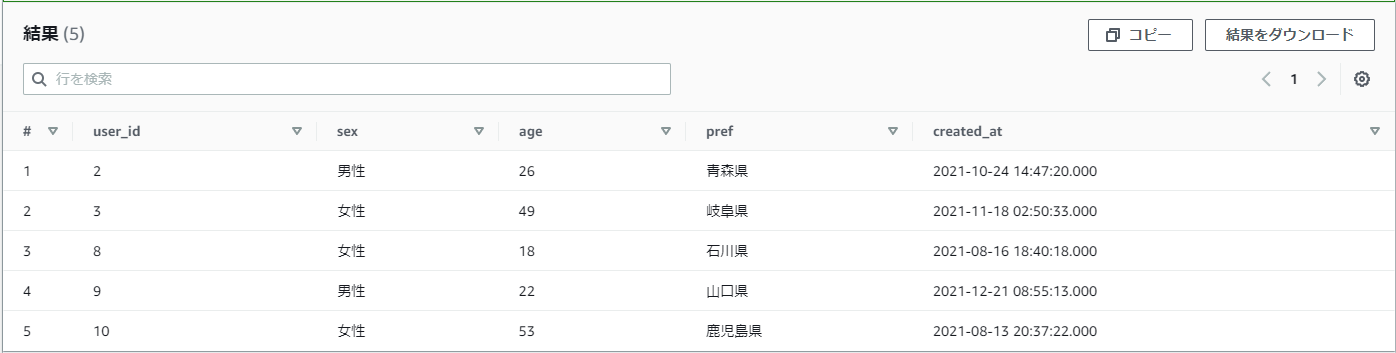
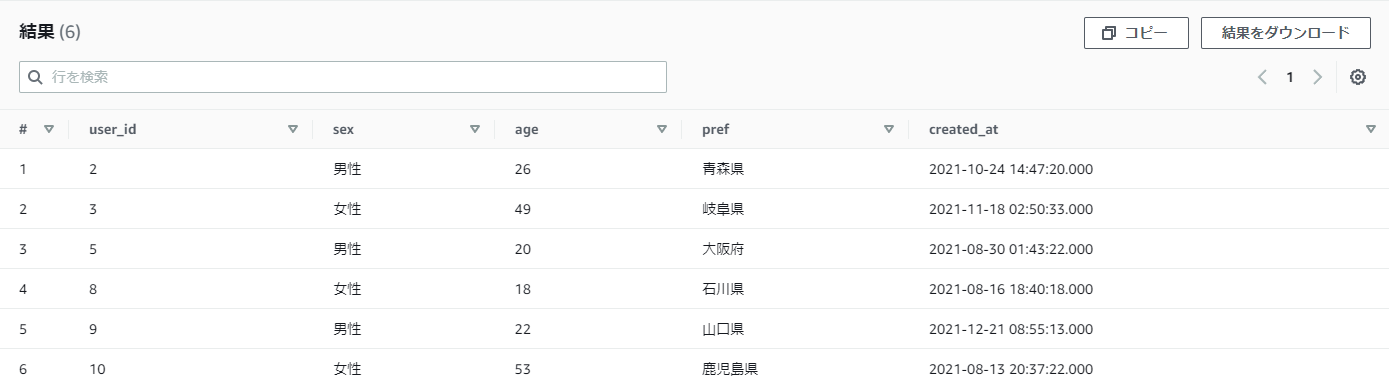
【例】practice_userテーブルからpref(都道府県)のに「都」が含むデータを取得したい
SELECT
*
FROM
practice_user
WHERE
pref LIKE '%都%'
結果
部分否定
LIKEと否定のNOTは組み合わせて使うことができます。
【例】practice_userテーブルからpref(都道府県)のに「都」が含まないデータを取得したい
SELECT
*
FROM
practice_user
WHERE
pref NOT LIKE '%都%'
結果
データ型
データには型があり、集計や表の結合をするとき、見た目は同じでも型が違うと思い通りに実行できない場合があります。
前回の「データの整列」で文字列型に対してORDER BYをした例を出しましたが、ORDER BY以外にもこのような実行結果がおかしくなったり、エラーを吐くことがあります。
データ型には次のようなものがあります。
詳しくはAWS公式マニュアル「Amazon Athena のデータ型」を参照ください。
| データ型 | 説明 | 実行できる関数 |
|---|---|---|
| int/integer | -2147483648から2147483647までの整数を表現できる | 集計関数/四則演算や計算用関数等 |
| float/real | 1.40129846432481707e-45 から 3.40282346638528860e+38 の範囲の正または負の値を表現できる | 集計関数/四則演算や計算用関数等 |
| varchar | 1から65535までの長さの文字データを表現できる | LIKE句でのあいまい検索や文字の置き換え、切り取り等 |
| date | YYYY-MM-DD の日付データを表現できる | 日数を足す。月別に均す。年月日の好きな部分を取り出す等 |
| timestamp | YYYY-MM-DD HH:mm:ss[.f...]のミリ秒単位までの日付と時刻を表現できる | 時間を足す。時間別に均す。日時の好きな部分を取り出す等 |
データ型確認
コンソールから見る
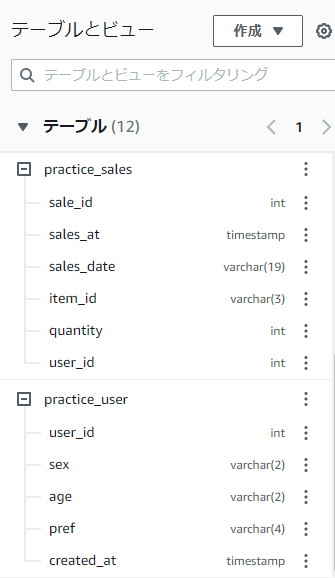
表の列ごとにデータ型は決まっていて、Athenaコンソールではそれをすぐに確認できます。
左側の「テーブル」→「+ボタンクリック」→列名の右側がデータ型です。
クエリで見る
typeof()で、型を見ることができます。
SELECT typeof(3) -- integer

SELECT typeof(3 + 0.01) -- double

SELECT typeof('こんにちは') -- varchar(5)

データ型を変換する
CASTやTRY_CASTでデータ型を変更することができます。
CAST
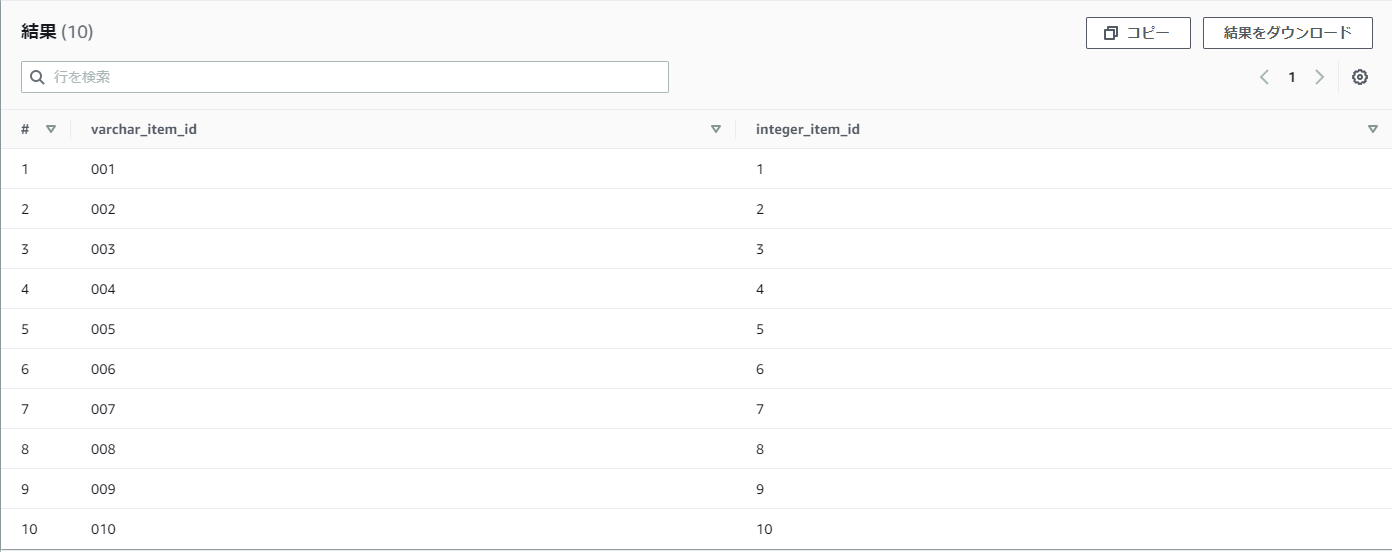
【例】practice_productのitem_idをintegerへ変換したい
SELECT
item_id as varchar_item_id,
cast(item_id as integer) as integer_item_id
FROM
practice_product
TRY_CAST
TRY_CASTは、データ型を変換できるものは変換し、変換できないものはNULLとする関数です。
【例】practice_userのage(年齢)を変換できるものはintegerへ変換し、できないものはNULLとしたい
SELECT
age as varchar_age,
try_cast(age as integer) as integer_age
FROM
practice_user
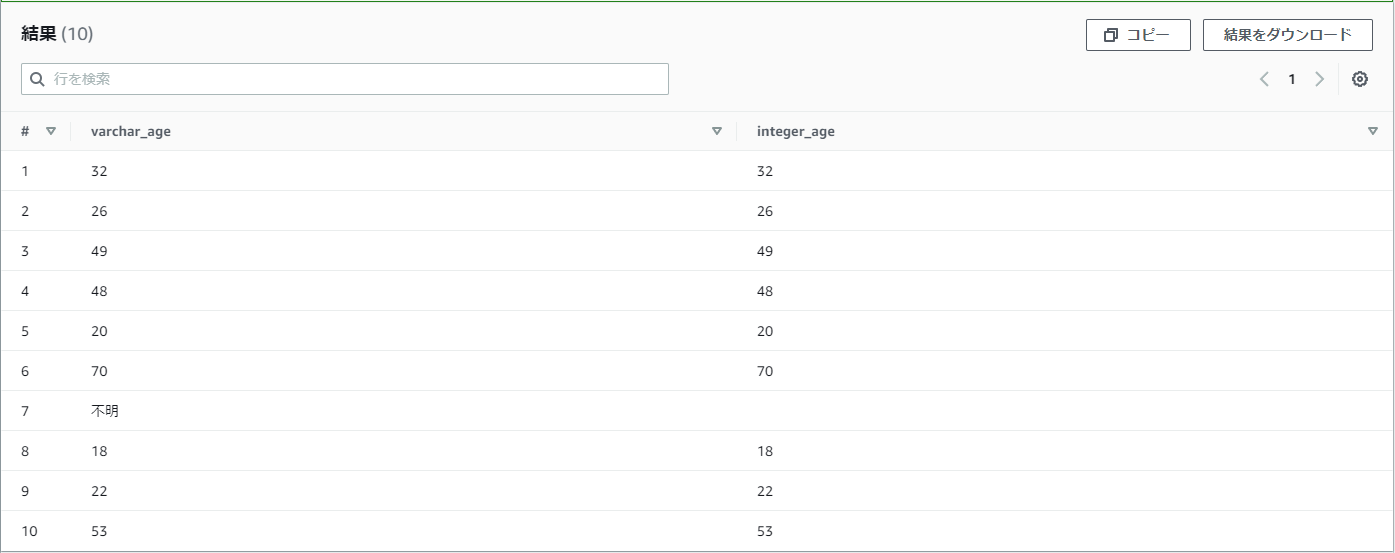
「不明」はintegerへは変換できないので、NULLになりました。
TRY_CASTではなくCASTで、このクエリを実行すると、変換できずエラーになります。

NULL
NULLとは、「データが無い」ことを示します。
前回のLEFT JOINでの結合をした結果、列の右側がほとんど空白になっていましたが、あれがNULLです。
赤枠がNULL
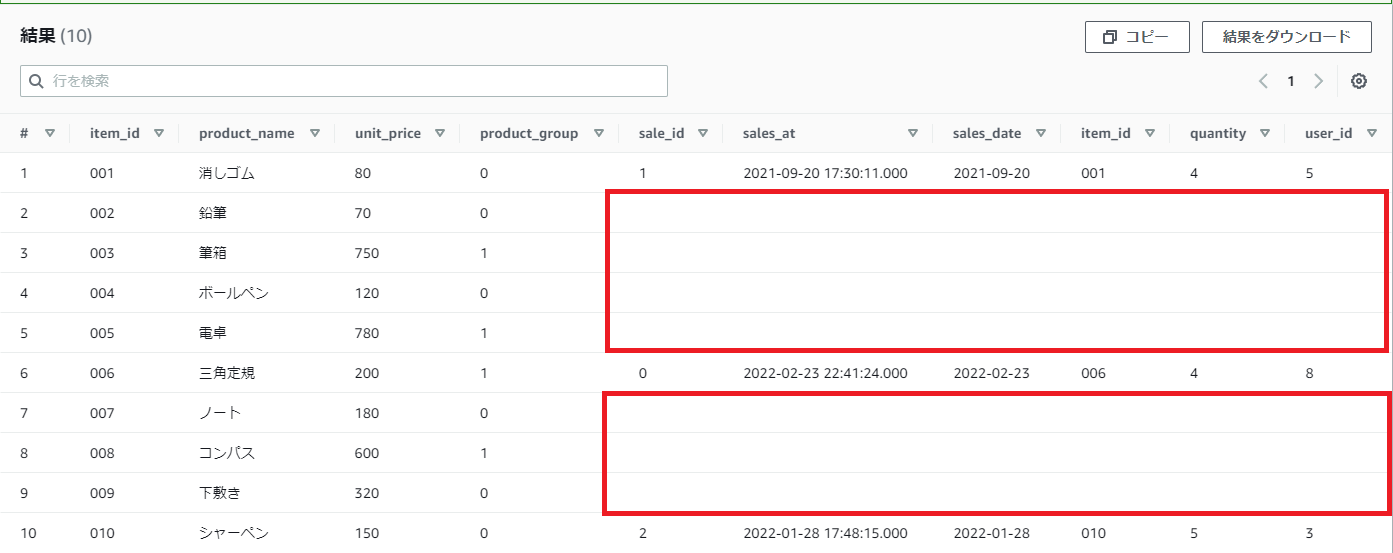
「データが無い」ので、集計関数でも対象とされません。上の画像の表からproduct_nameとsale_idをそれぞれカウントしてみます。
WITH left_join_table AS -- LEFT JOINをした画像の表
(SELECT
*
FROM
practice_product
LEFT JOIN
(SELECT * FROM practice_sales limit 3) as practice_sales -- practice_salesから先頭3行取得した表をpractice_salesと定義
ON
practice_product.item_id = practice_sales.item_id
)
SELECT
count(product_name) as count_product_name,
count(sale_id) as count_sale_id
FROM
left_join_table
結果

product_nameは10,sale_idは3と出てきました。NULLはデータが無いことを示すので、集計の対象になっていないことが分かります。
xxx is NULL
「データが無い」NULLを条件として、結果を取得することもできます。
【例】LEFT JOINしたテーブルからsale_idがNULLのデータを取得する
WITH left_join_table AS -- LEFT JOINをした画像の表
(SELECT
*
FROM
practice_product
LEFT JOIN
(SELECT * FROM practice_sales limit 3) as practice_sales -- practice_salesから先頭3行取得した表をpractice_salesと定義
ON
practice_product.item_id = practice_sales.item_id
)
SELECT
*
FROM
left_join_table
WHERE
sale_id is NULL
結果
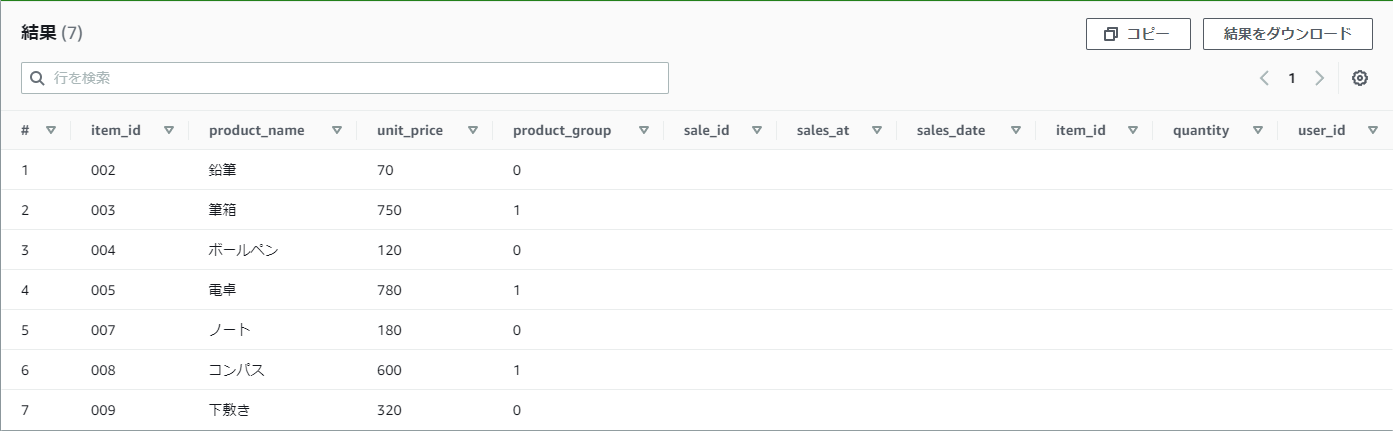
COALESCE
NULLになってしまったデータを、何かに置き換えたい場合があります。
その場合はCOALESCE関数を使います。
【例】practice_userのageをTRY_CASTでintegerへ変換する際、NULLになってしまったデータは40としたい
SELECT
age as varchar_age,
COALESCE(try_cast(age as integer), 40) as integer_age
FROM
practice_user
結果
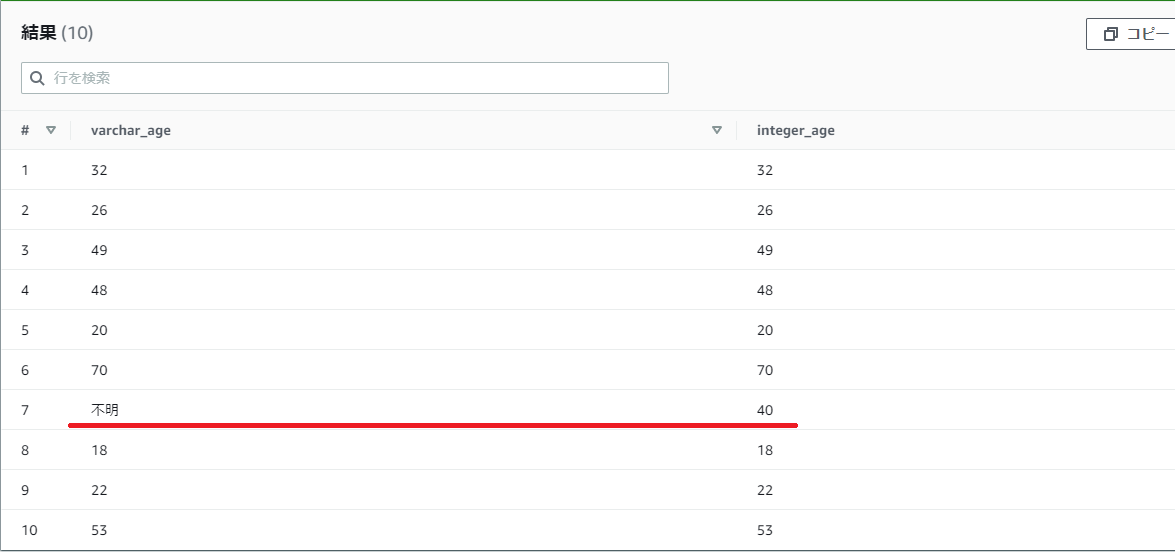
先ほどは変換できずにNULLになりましたが、40で置き換えることができました。
条件式
IF
IFのあとに条件を書き、その条件に合致している場合と合致していない場合の値を書くことができます。
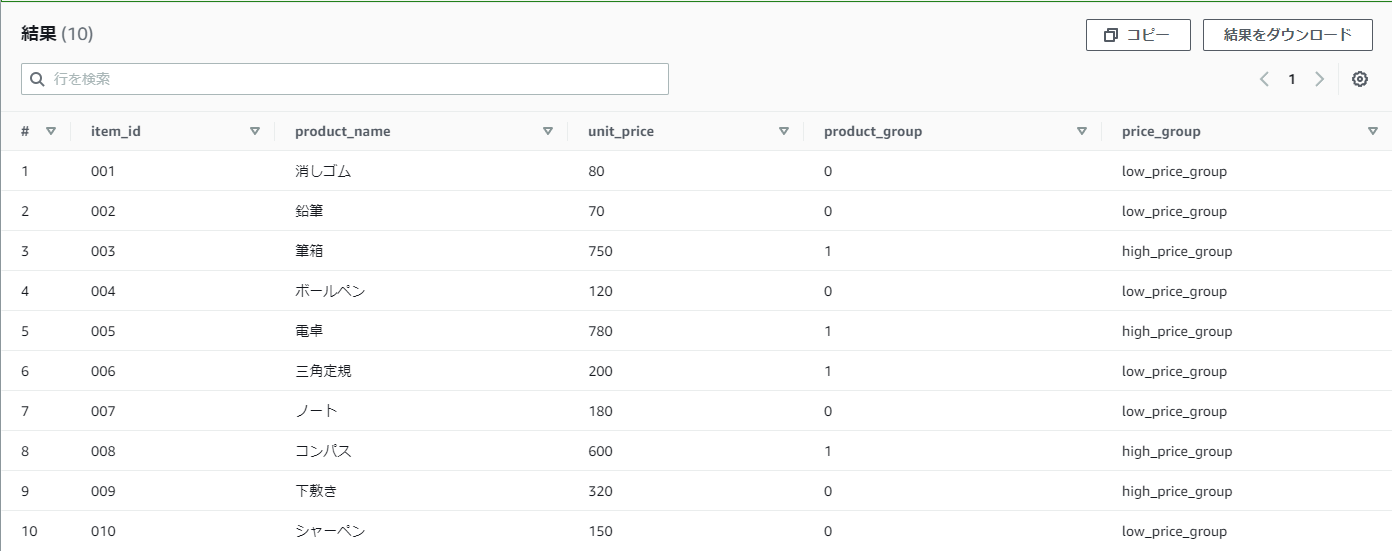
【例】practice_productテーブルのunit_priceが200以下のものはlow_price_group,そうでないものはhigh_proce_groupという値を付与したい
SELECT
*,
IF(unit_price <=200, 'low_price_group', 'high_price_group') as price_group
FROM
practice_product
結果
CASE WHEN
IFのような条件をいくつも書きたいとき、CASE WHENが役に立ちます。
年齢から年代を作るような時に使えますね。
最初にCASEを書き、その後にWHENで条件式、THENへ条件が合致したときの値を。
最後すべての条件に合致しなかった場合の値をELSEで書き、ENDで閉じます。
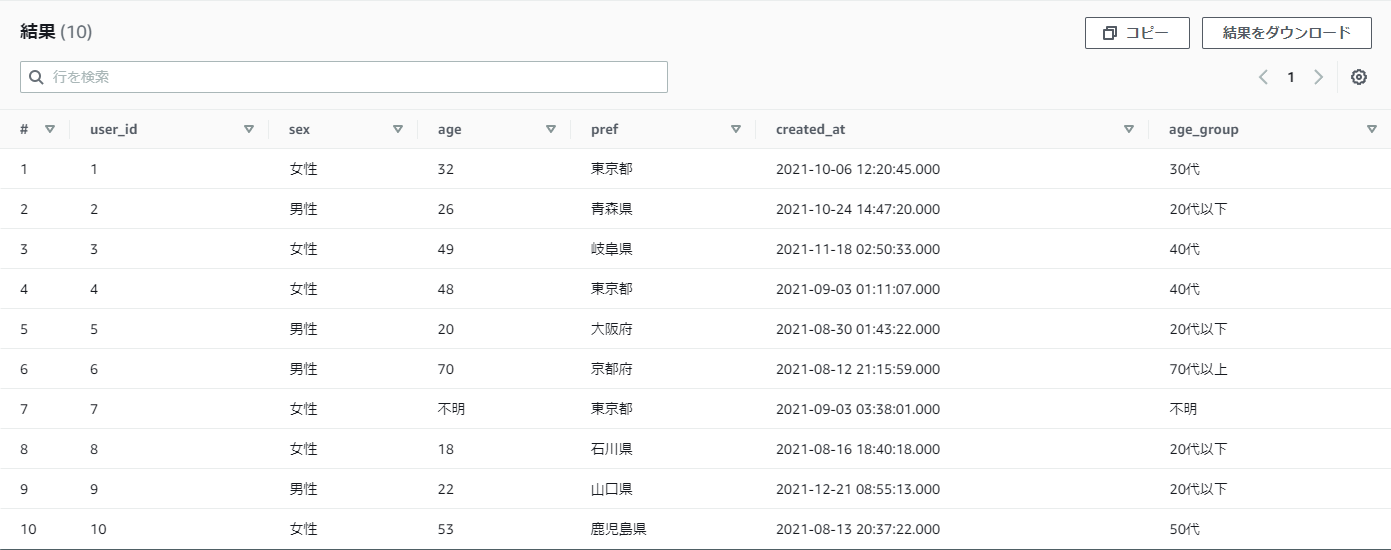
【例】practice_userテーブルのageを以下のように振り分けたい
| 年齢 | 振り分け |
|---|---|
| 29歳まで | 20代以下 |
| 30 ~ 39歳 | 30代 |
| 40 ~ 49歳 | 40代 |
| 50 ~ 59歳 | 50代 |
| 60 ~ 69歳 | 60代 |
| 70歳以上 | 70代以上 |
| 不明 | 不明 |
SELECT
*,
CASE
WHEN try_cast(age as integer) <= 29 THEN '20代以下'
WHEN try_cast(age as integer) BETWEEN 30 AND 39 THEN '30代'
WHEN try_cast(age as integer) BETWEEN 40 AND 49 THEN '40代'
WHEN try_cast(age as integer) BETWEEN 50 AND 59 THEN '50代'
WHEN try_cast(age as integer) BETWEEN 60 AND 69 THEN '60代'
WHEN try_cast(age as integer) >= 70 THEN '70代以上'
ELSE '不明' END as age_group
FROM
practice_user
結果
集計関数と合わせて書くこともできます。
【例】practice_productテーブルのunit_priceが200以下の商品とそうでない商品の個数をカウントしたい
SELECT
count(
CASE
WHEN unit_price <= 200 THEN unit_price
ELSE NULL END
) as low_price_item_count,
count(
CASE
WHEN unit_price > 200 THEN unit_price
ELSE NULL END
) as high_price_item_count
FROM
practice_product

ELSE NULLとすることで条件に合致しないものはNULLとして、集計対象から外すことができます。
それぞれの価格に合致する商品の個数をカウントすることができました。
GROUP BYっぽいですが、列を分けてそれぞれ集計することができるので、違った使い道があります。
文字列データ操作
データ型でいう、varcharを対象として使える関数の一部を紹介します。
全ては、マニュアルの6.9. String Functions and Operatorsに載っています。
| 関数 | 説明 |
|---|---|
| CONCAT() | 文字をくっつけることができる (||でも代用できる) |
| LENGTH() | 文字数をカウントできる |
| REPLACE() | 選択した文字を置き換え、削除できる |
| SUBSTR() | 文字列の好きな部分を表示できる |
CONCAT
CONCAT()の括弧の中に、対象となる列や文字を入れると、くっついた新たな列ができます。
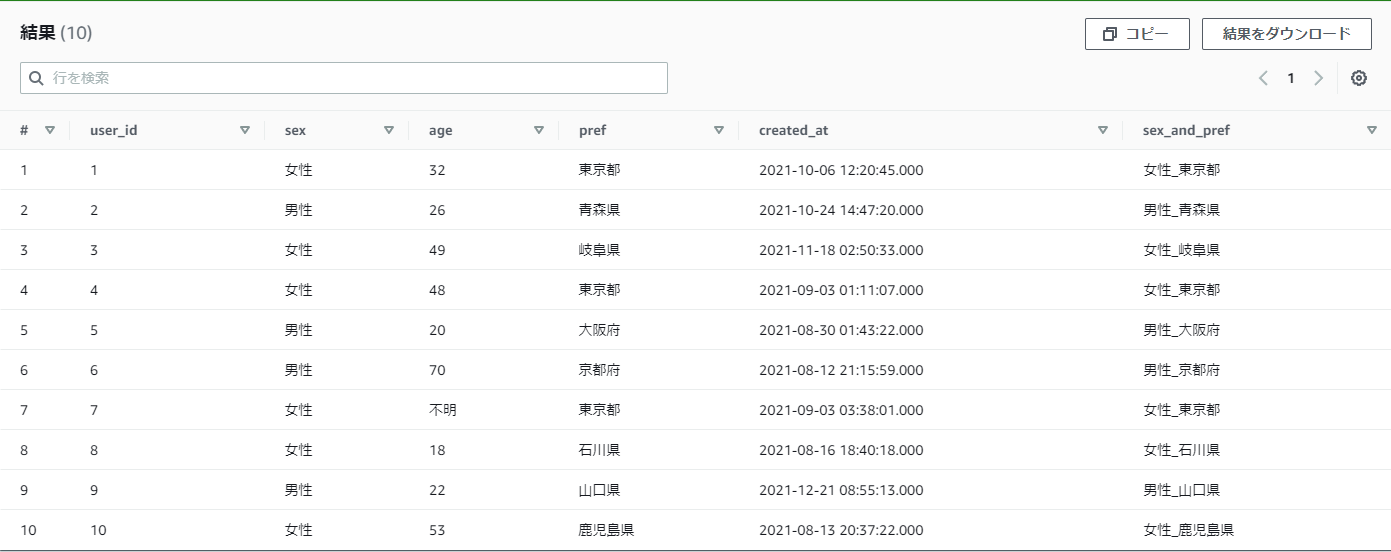
【例】practice_userのsexとprefをくっつけて、新しい列を作りたい。結合時は_を間に挟みたい
SELECT
*,
CONCAT(sex, '_', pref) as sex_and_pref
FROM
practice_user
結果
また、||でも代用することができます
SELECT
*,
sex || '_' || pref as sex_and_pref
FROM
practice_user
LENGTH
LENGTH()の括弧の中に、対象となる列や文字を入れると、文字数をカウントできます。
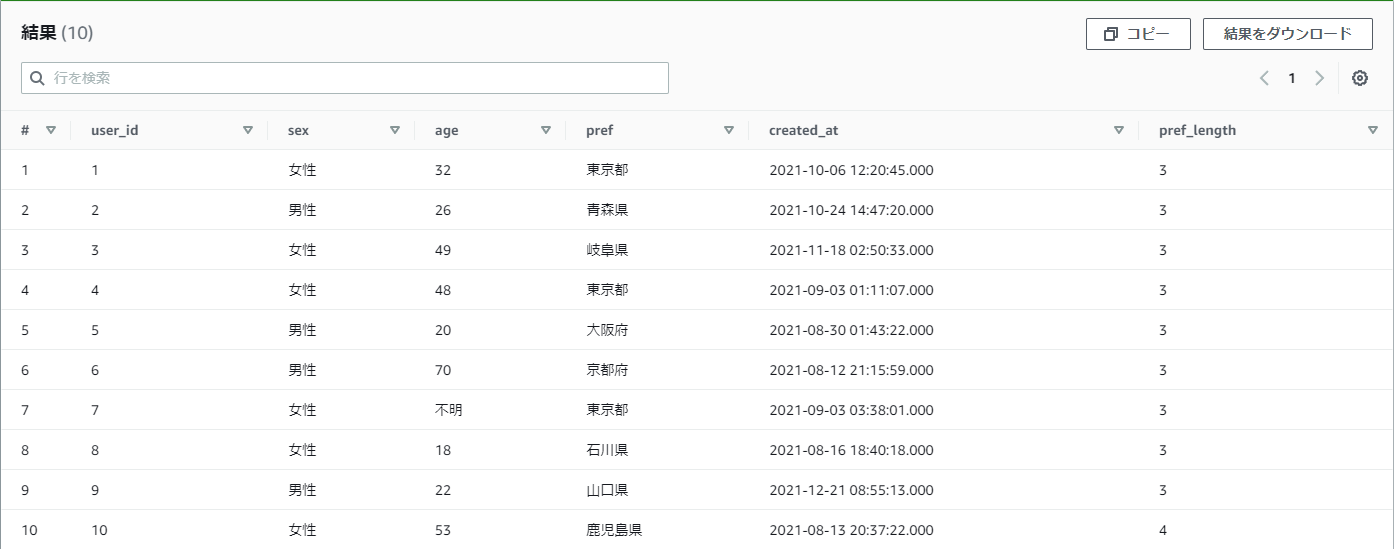
【例】practice_userテーブルのprefの文字数をカウントしたい
SELECT
*,
LENGTH(pref) as pref_length
FROM
practice_user
結果
REPLACE
REPLACE()は、括弧の中に、「対象となる列や文字」「置き換えたい文字」「置き換え後の文字」を入れます。「置き換え後の文字」は省略することができ、省略すると「置き換えたい文字」に合致するものは消えます。
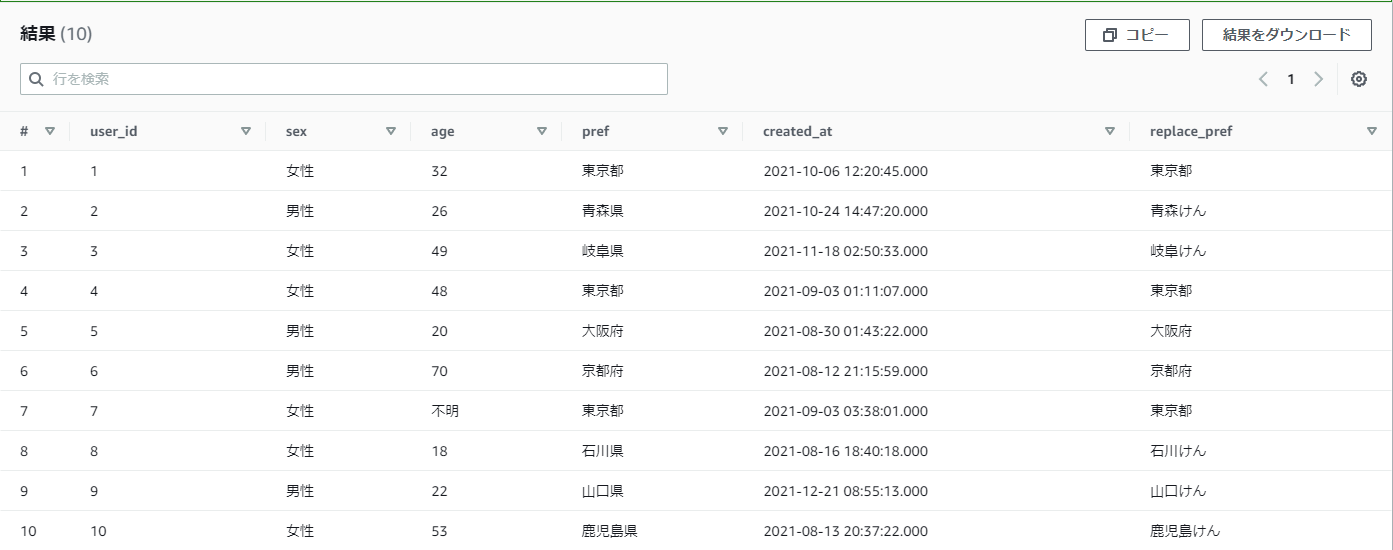
【例】practice_userテーブルのprefの「県」を「けん」にしたい
SELECT
*,
REPLACE(pref, '県', 'けん') as replace_pref
FROM
practice_user
結果
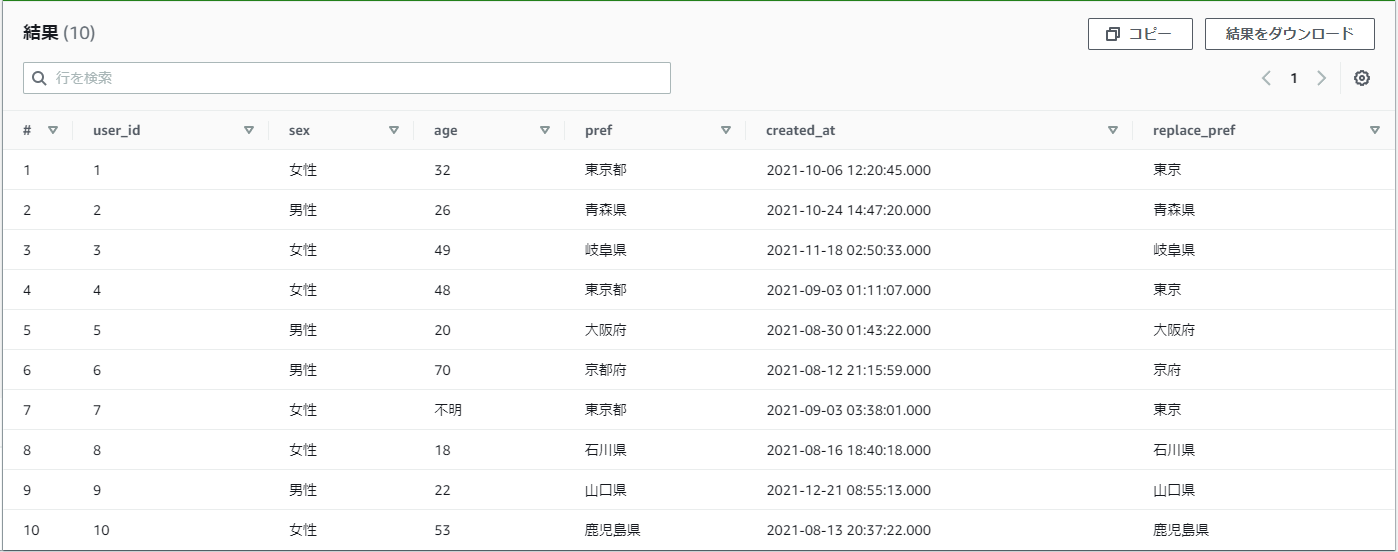
「置き換え後の文字」を省略してみます。
【例】practice_userテーブルのprefの「都」を消したい
SELECT
*,
REPLACE(pref, '都') as replace_pref
FROM
practice_user
SUBSTR
SUBSTR()は、括弧の中に、「対象となる列や文字」「取得開始したい位置」「取得開始したい位置から何文字取得するか」を入れます。
「取得開始したい位置から何文字取得するか」は省略することができ、省略すると残りの文字全てを取得対象とします。
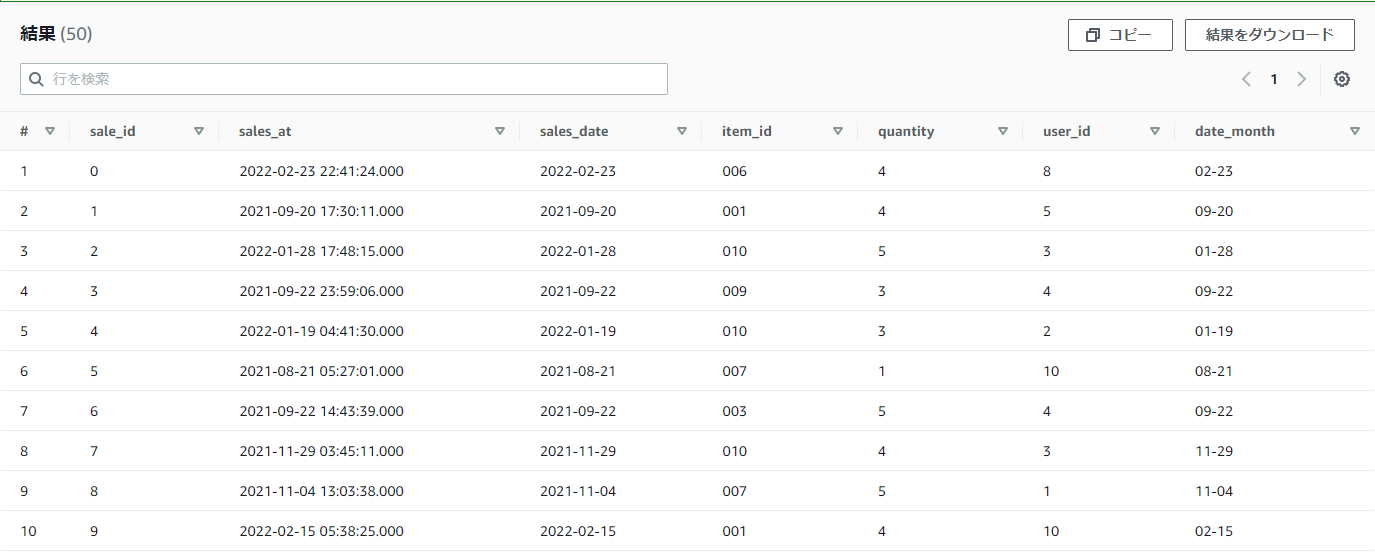
【例】practice_salesテーブルのsales_date列を月日だけの表記にしたい
SELECT
*,
SUBSTR(sales_date,6) as date_month
FROM
practice_sales
結果
【例】practice_productのproduct_nameの4文字目から2文字取得したい
SELECT
*,
SUBSTR(product_name,4, 2) as product_name_substr
FROM
practice_product
結果
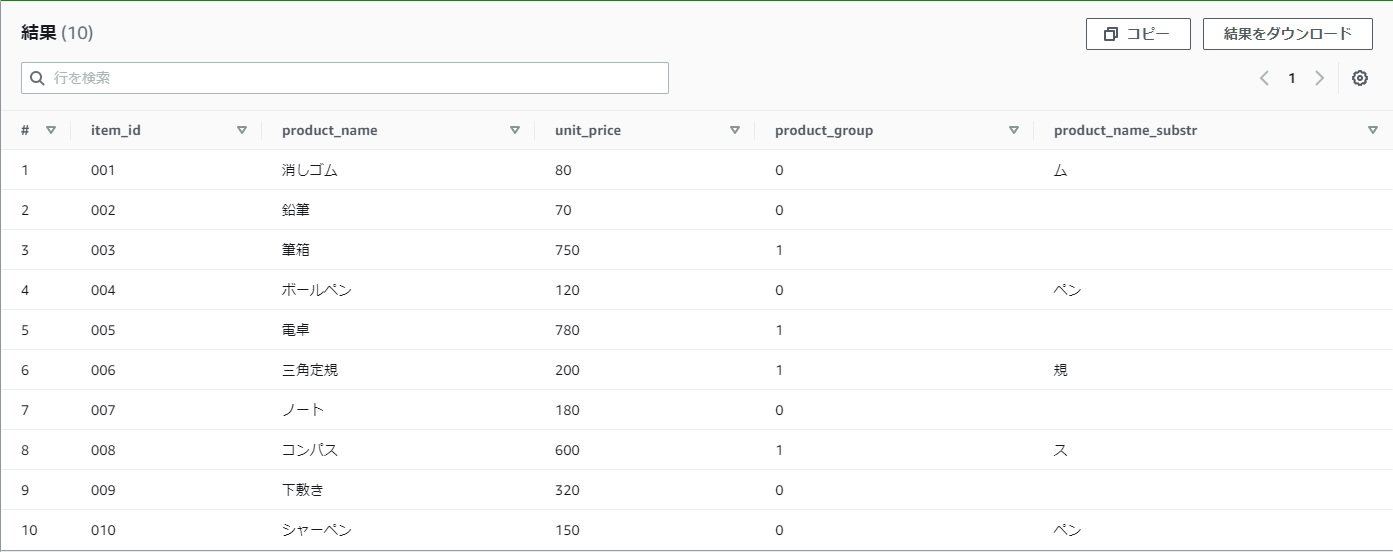
4文字目まで存在しないproduct_nameのデータは、空白になりました。
紛らわしいですがこれはNULLではなく、''(空白というデータがある)です。
副問合せ
副問合せは、SELECT,FROM,WHERE等データを取得したい条件を書くとき、その条件にSELECT,FROM,WHEREを用いた結果を使うことです。
【例】practice_userテーブルのprefが東京都の人のみのデータをpractice_salesから取得したい
SELECT
*
FROM
practice_sales
WHERE
user_id IN (SELECT user_id FROM practice_user WHERE pref = '東京都')
結果
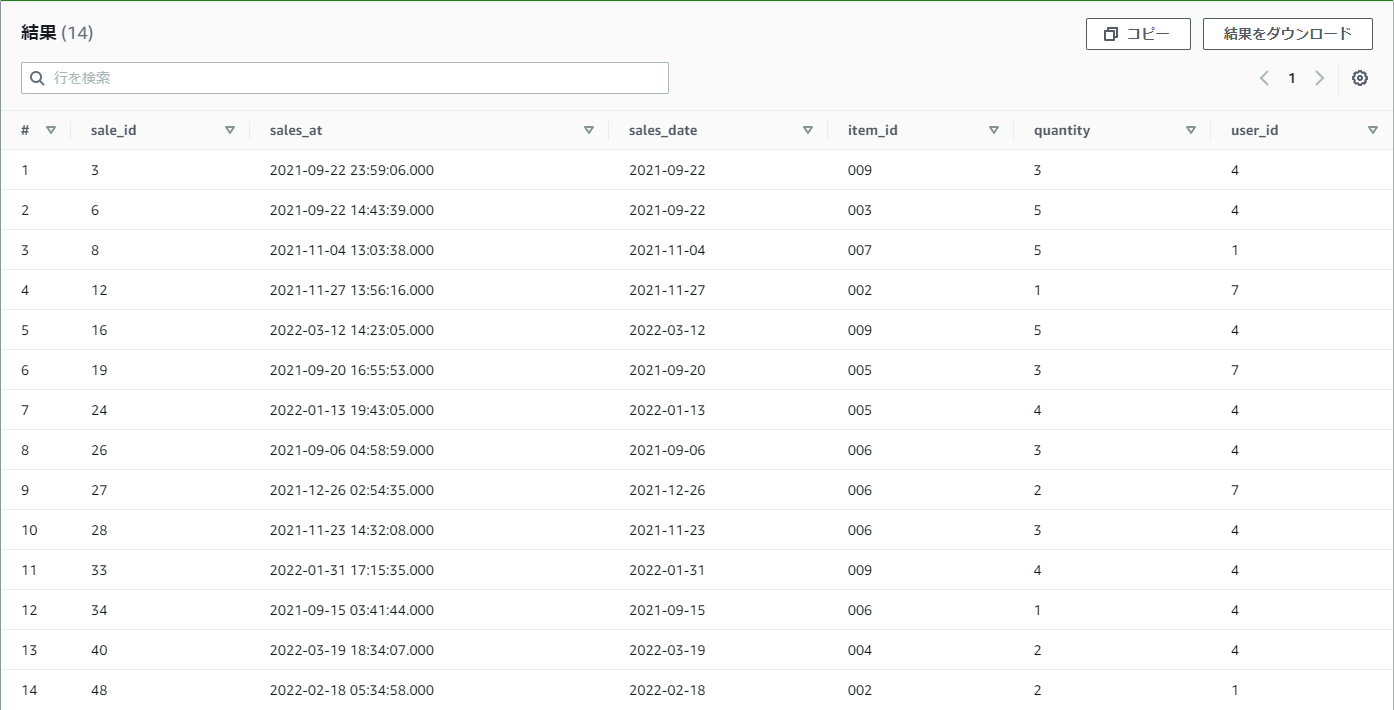
user_id INの条件に
SELECT user_id FROM practice_user WHERE pref = '東京都'というクエリが更に入っています。
このようにして、他のテーブルから条件を持ってきたりすることが可能です。
前回のFULL JOINでは、FROMとFULL JOIN部分にも副問合せを用いています。
クエリ内テーブル
WITHを使うと、クエリの中だけで使えるテーブルを作ることができます。
副問合せで使った
SELECT user_id FROM practice_user WHERE pref = '東京都'を一つのテーブルとして作ってあげることで、可読性を高めることができます。
【例】WITH句を使って、practice_userテーブルのprefが東京都の人のみのデータをpractice_salesから取得したい
WITH tokyo_users AS
(SELECT * FROM practice_user WHERE pref = '東京都')
SELECT
*
FROM
practice_sales
WHERE
user_id IN (SELECT user_id FROM tokyo_users)
結果
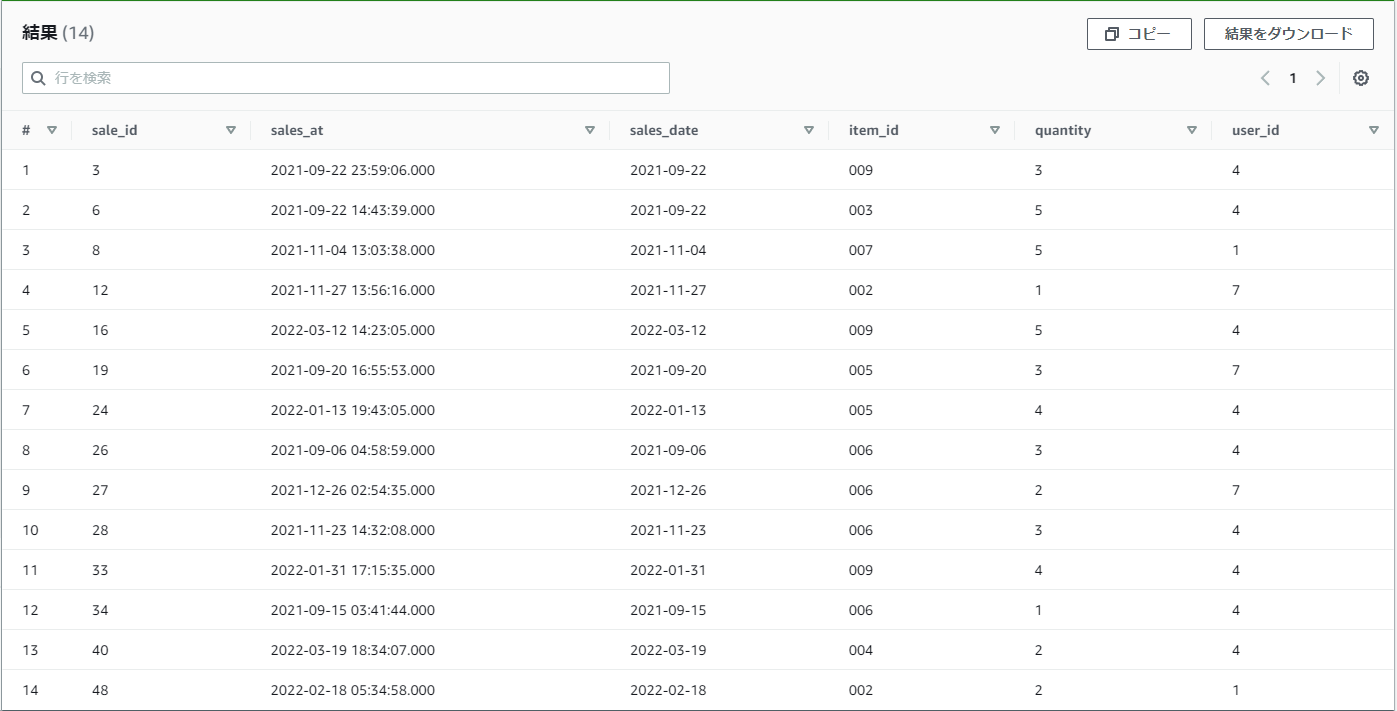
tokyo_usersテーブルとして、practice_userテーブルからprefが東京都のユーザーだけを取得した後に、tokyo_usersテーブルをuser_id INの条件として使用しています。
複数作成する場合
クエリ内テーブルですが、2つ目以降にはWITH句は不要です。
更に、最後以外のクエリ内テーブルの終わりにカンマをつける必要があります。
【例】クエリ内テーブルを2つ作成
WITH tokyo_users AS
(SELECT
*
FROM
practice_user
WHERE
pref = '東京都'
), -- カンマを付ける
aomori_users AS -- WITHは不要
(SELECT
*
FROM
practice_user
WHERE
pref = '青森県'
)
SELECT
*
FROM
practice_sales
WHERE
user_id IN (SELECT user_id FROM tokyo_users) or user_id IN (SELECT user_id FROM aomori_users)