この記事はWano Group Advent Calendar 2023の15日目の記事となります。
経緯
私は2023年2月にTuneCore Japan1人目のData Analyticsチームメンバーとして株式会社WANOに入社しました。
当時は、開発チームがMySQLのテーブルデータをS3へ格納したものを見たいメンバーがTableauで見るという状態で、適切な分析の為のテーブル環境が整っていませんでした。
そこで、みんながデータ活用できるような環境をAWSで作っています。
現時点でまだ足らない箇所もありますが、現時点の内容を紹介したいと思います。
構成図
旧
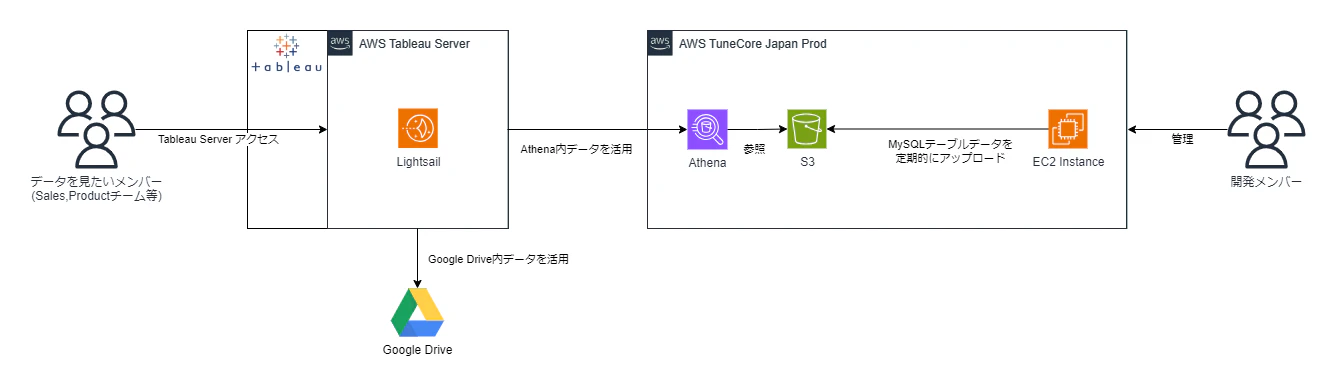
以前は
データを見たいメンバー -> Tableau ServerへアクセスしAthenaやGoogle Driveのデータを閲覧
開発メンバー -> MySQLテーブルデータをS3へアップロードしAthenaテーブルのデータを更新
する形でした。
ここでの問題点は以下です。
- テーブルが開発の為のものだからデータを見る側に適していない
- Tableauで集計するまでにいくつものテーブルを結合する必要がある
- データが重い
- Tableau Serverを実用面で管理する人がいない
新(20231202現在)

今は上記のような環境になっています。
行ったこととしては
- データを見る側に適したテーブルを作るためのAnalytics AWS環境を作成し、Tableauから接続
- S3に保存されているデータを
parquet.snappyへ変更しクエリ実行時間を短縮 - Tableau ServerのLB変更やインスタンスを追加し動作を快適に
- BigQueryのみで使用しているデータを、Tableauからログデータも見れるように設定
です。
AWS TuneCore Japan Analyticsについて
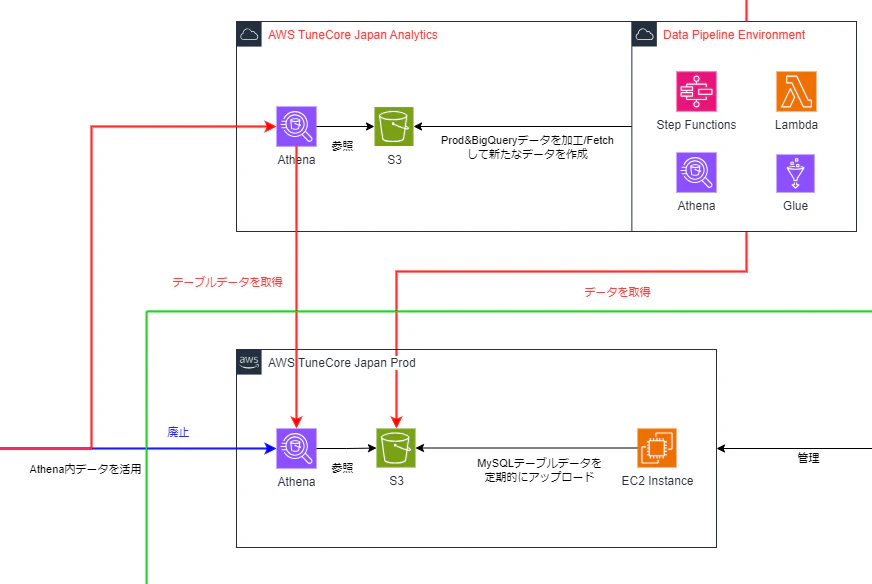
この部分についてのお話です。
私が入社時、新たにAWS TuneCore Japan Analyticsアカウントを作成していただきました。
以降このAWSアカウントでDWH/Datamartテーブルを作成するPipeline環境を作っています。
テーブル作成Pipelineについて
基本的にはAWS TuneCore Japan ProdアカウントにあるAthenaテーブルやS3データを定期的に読み込んでCTASクエリを実行し、Analytics AWSアカウントのテーブルを更新するスタイルにしています。
例えば、Production AWSアカウント Athenaテーブルを用いて、Tableauで描画する為の集計用KPI確認テーブルを作るとします。
その場合、流れはStep Functionsで構築していて、
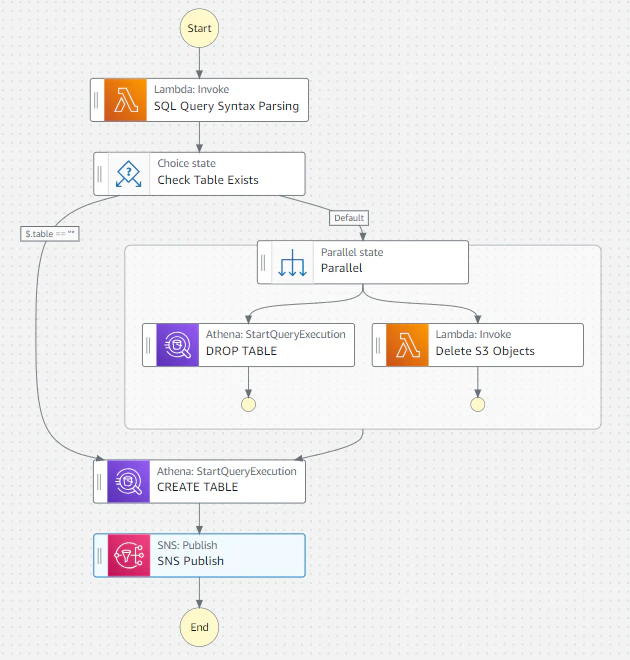
これが基本形になっています。
- クエリを解析し、CTASクエリかどうか・テーブルが存在するかどうか・S3の保存先URIはどこかを確認
- CTASクエリである場合、そのテーブルをDROP TABLEし、テーブルデータの保存先S3URI オブジェクトを削除します。
- CTASクエリでない場合は基本的に想定していません。
- CTASクエリを実行
- SNSへPublish(Slack通知用途)
という流れです。トリガーはEventBridge Schedulerで行っています。
DROP TABLE→CREATE TABLEで一時的にテーブルが削除されるので、実行は影響の少ない時間に行っています。
ですが、作り直しをすることでINSERTによる増分更新などと比較して、失敗した時の対処が楽という利点があります。
また、全体の構成として基本サーバーレスのサービスを用いているため、更新時のみ動きます。
そのためEC2インスタンス等で更新を行うよりも安価に稼働することができます。
これ以外にもSQLだけでは処理が行えないようなテーブルを作る時がありますが、その際はLambdaを立ち上げPythonで処理しています。EC2インスタンスは1つも使用していません。
CTASクエリが複数ある場合
上記の基本形のStep Functionsの流れを、Step Functions Distributed Map機能を用いて並列実行しています。
実際の運用ではこちらを主に使っています。

さきほどのフローと比較するとMapがついています。
デフォルトで1000の子ワークフローを実行することができます。
(とはいえAthenaはActive DDL/DML queriesのQuotaがあるので、そこも確認する必要があります)
並列実行対象の.sqlファイルがどこに入っているかを表すcsvファイルを読み取り実行しています。
bucket,file_key
bucket-name,aggregate1.sql
bucket-name,aggregate2.sql
bucket-name,aggregate3.sql
リソース管理で後述しますが、このcsvファイルはGithubにあるResourceをAWS CodePipelineで読み取ってCodeBuildにより作成されます。
DWH/Datamartの階層化処理について
データソースの呼び名と用途や粒度の関係ですが、以下の様に私は認識しています。
| Data Lake | Data Ware House | Data Mart | |
|---|---|---|---|
| データ粒度 | 細 | 中 | 荒 |
| データ量 | 大 | 中 | 小 |
| どんなもの | 開発で用いているテーブルを書き出したもの。ログ。生データ | データ活用の視点で使いやすい形に非正規化等されたテーブルデータ | 単純な描画用。集計済みのテーブルデータ |
よって、Data Ware HouseやData Mart用のテーブルを作成する際、
- Data Ware Houseテーブルを作るとき、FROM句に他のData Ware House,Data Martテーブルを用いない
- Data Martテーブルを作る時、From句に他のData Martテーブルを用いない
ように、sqlファイルをAWSへ配置する前にGithubのGithub Actionsで制御しています。
また、「CTASクエリが複数ある場合」のStep Functionsも、以下の様に別のStep Functionsステートマシンを用いてData Ware House→Data Martの順番で実行されるようにしています。
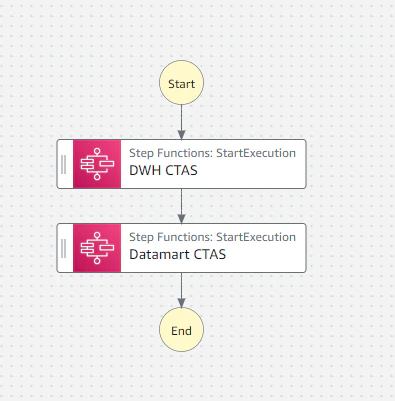
高速化されたテーブルの作成
MySQLからProduction AWSアカウントへ置かれるデータは、一部Tableauで用いるにはクエリ実行速度の面で使いづらいものでした。
また、2023年8月頃に極端にクエリ実行速度が遅くなる事象が発生していたため、Analytics AWSアカウント側で、列指向のデータファイル形式であるparquet.snappyに差し替えたテーブルを作成しました。
単一オブジェクトの場合
Athenaテーブルで参照しているオブジェクトが単一である場合、Lambda S3 Trigger機能を用いて
CREATE TABLE tunecorejapan.parquet_snappy_table_xxx WITH (
format = 'PARQUET',
external_location = 's3://bucket/parquet_snappy_table_xxx/',
parquet_compression = 'SNAPPY'
) AS
SELECT * FROM table_xxx
のような拡張子だけ変更しテーブルを作成するクエリを単一クエリをDROP→CTASし更新するStep Functionsで実行し更新しています。
複数オブジェクトの場合
ものによっては、HIVEスタイルのパーティション分割を利用し、1つのテーブルに対して複数のオブジェクトからなるものがあります。
この場合、Lambda S3 Triggerではオブジェクトの分だけトリガーが発生してしまうので、AWS Glue ETL Jobsで以下のようなジョブを作成して定期実行しています。

- Data Source - S3 BucketにはProduction AWS アカウントのHIVE式パーティションされているS3 URIを指定
- Change Schemaを定義
- AWS Analytics S3にparquet.snappyでデータを書き出しテーブルも作成
の流れです。
Change Schemaについては、型によって間違った定義をするとデータが消えたりしますので慎重に行っています。
最後のData TargetでS3にオブジェクトを置くのと同時にAthenaへテーブルも作ることができるので、テーブルを作成します。
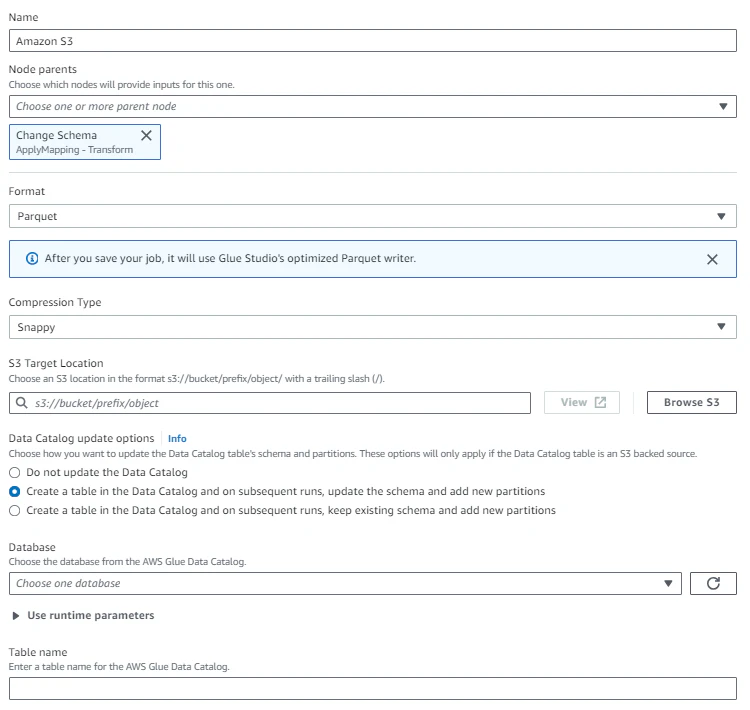
Bookmark機能をONにすれば、一度処理したデータについては再度処理されませんので、それで高速化テーブルを更新しています。
(初回で過去分データを一気に拡張子変換し、その後は更新分だけ変換できる)
リソース管理
リソース管理は全てGitHubを用いています。
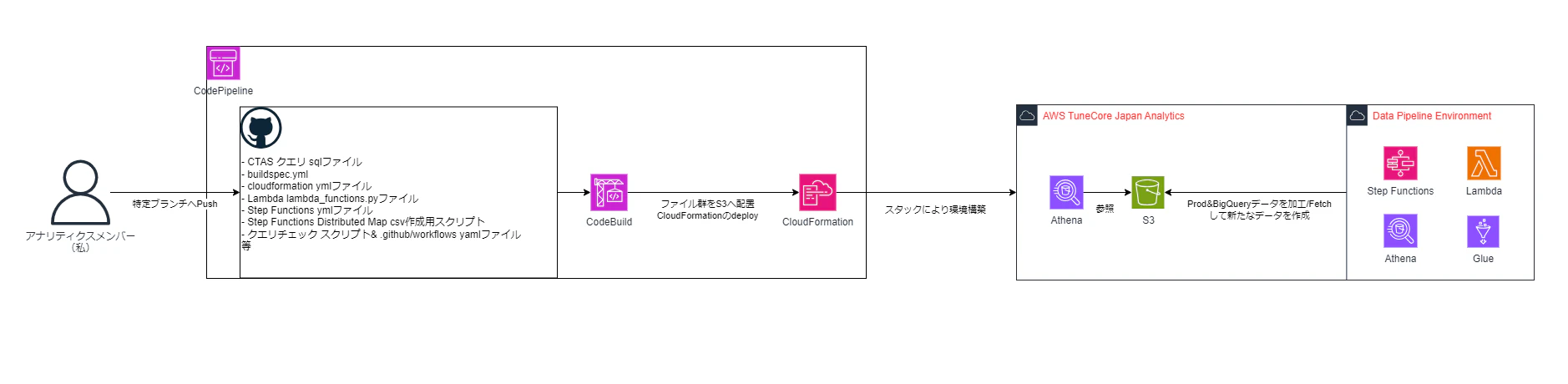
Githubで特定ブランチへPushした時、AWS CodePipelineがそれをResourceとして、AWS Codebuildが走るようになっています。
そして、buildspec.ymlから、実行に必要なリソースをS3へ配置したり、aws cloudformation package,aws cloudformation deployコマンドを実行しAWSリソースを作成・更新しています。
Lambda,Step Functionsの更新
CloudFormationでLambda Zipファイル内のlambda_functions.pyの中身を変更してもCloudFormationスタックから見ると「更新がある」と判定されない為、工夫が必要です。
私が行った工夫はリソースを配置するS3バケットに対してバージョニングを有効にし、Buildspecが走るたびに置かれるリソースの最新バージョンIDを取得し、それを用いてaws cloudformation deployを実行しています。
簡単な例としては以下のような形です。
Parameters:
DeleteS3ObjectsParam:
Type: String
Default: '' -- オブジェクトの最新バージョンIDが入る
Resources:
DeleteS3Objects:
Type: AWS::Lambda::Function
Properties:
Code:
S3Bucket: !Sub ${ResourceBucket}
S3Key: lambda/src/delete-s3-objects.zip
S3ObjectVersion: !Ref DeleteS3ObjectsParam -- S3keyの最新バージョンIDが入る
FunctionName: delete-s3-objects
Handler: lambda_function.lambda_handler
Role: !GetAtt CommonServiceRole.Arn
Runtime: python3.9
Timeout: 900
version: 0.2
phases:
pre_build:
commands:
- echo check aws cli version
- aws --version
build:
commands:
- echo Create Lambda Function zip
- bash aws/script/create_zip_files.sh -- lambdaのzipファイルを作成するスクリプト
- echo get Lambda Zip Version ID -- zipファイルの最新オブジェクトバージョンIDを取得
- DELETE_S3_OBJECTS=$(aws s3api list-object-versions --bucket bucket-name --prefix lambda/src/delete-s3-objects.zip | jq -r '.Versions[0].VersionId')
post_build:
commands:
- echo deploy dwh/datamart environment cloudformation
- aws cloudformation package --template-file aws/cloudformation/dwh-operation-environment.yml --s3-bucket $target_bucket --s3-prefix cloudformation/package --output-template-file /tmp/cloudformation-$dwh_stack_name.yml --force-upload
- |
aws cloudformation deploy --no-fail-on-empty-changeset --template-file /tmp/cloudformation-$dwh_stack_name.yml --stack-name $dwh_stack_name --capabilities CAPABILITY_NAMED_IAM CAPABILITY_IAM \
--parameter-overrides \
"DeleteS3ObjectsParam=$DELETE_S3_OBJECTS" -- パラメータを最新バージョンIDでoverride
これにより、Githubで管理しているLambda,Step Functionsのコードを変更し、CloudFormationのスタック更新で反映させるようにしています。
Tableau Serverについて
この部分についてのお話です。
Tableau Server Version
2021.1を使用していたので、2023.1にアップグレードしました。
アクションやパラメータがServerで使えなかったのと、Tableau app for Slackを導入したかったのでアップグレードを実施しました。
その他変更点で良かったものは、
- 「データに聞く」がViewerでも使用可能
- 「アクション」がServerでも使用可能
- 「パラメータアクション」がServerでも使用可能
- 「セットアクション」がServerでも使用可能
- 「上位 or 下位」フィルタがServerでも使用可能
- Tableau ServerのSlackワークスペース連携
- 「ダッシュボードオブジェクトの並べ替え」がServerでも使用可能
- ライブ接続における更新頻度を設定可能(データ鮮度ポリシー)
- Viewの読み込み時間高速化
- ワークブックオプティマイザーによるパフォーマンスの評価が使用可能
- シートの詳細が使用可能
- アクセラレーション機能が使用可能
です。
Load Balancer
Lightsail Load Balancerを通じてインスタンスを動かしていましたが、ConnectionのTimtout設定が60秒から変更できず、Tableau ServerでのAthena接続時に60秒経過するとエラーを吐くためnginxのLoad Balancingに切り替えました。
Tableau ServerとAthenaの接続
AWSアカウントが2つ存在することにより、TableauからAthenaへの接続用アクセスキーが2つ存在していて、使いづらくなっていました。
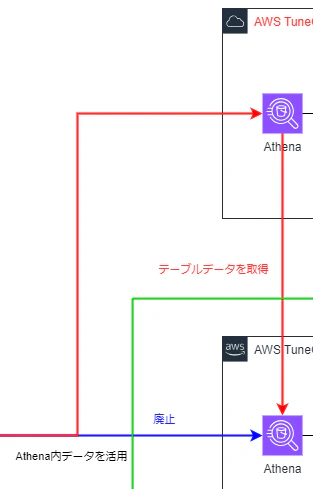
これを1つにする対処として、まずはAnalytics AWSアカウント側からProduction AWSアカウントのAthenaテーブルを読み取れるようにしました。
これにより、Analytics AWSアカウントへ接続した場合には、Production AWSアカウント側で見れるデータを包含できます。
ただし、注意点としてAthena データソースをTableau側で変更するには、athena.propertiesファイルを作成し所定の場所に置く必要があります。
これはTableau Server,Desktop,Prep Builder全て該当するので、Desktop,Prep Builderを用いるユーザーには、ローカルPCにathena.propertiesファイルを所定の場所に置いてもらうという案内が必要です。
最後に、Production AWSアカウント側のアクセスキーを既に使っているTableauワークブックについて対処する必要があります。
これについては対象ワークブックの数も50程度であり、数が少なかったので全て手作業で移行しました。
Tableau REST APIを用いて接続情報を変更するという手もありますが、ワークブックによってはアクション機能が失われたり、接続の関係が失われたりするので、手作業は免れませんでした。
GCP BigQueryについて
一部、BigQueryにもテーブルを作成している為、これをTableauでも使えるようにしています。
Tableau Serverへの接続
TableauはBigQueryとの接続もサポートされているので、接続用の権限を設定し使えるようにしました。
Amazon Athenaとの接続
Amazon Athena Google BigQuery Connectorの環境を作成し、Athenaへデータソースを作成しています。
これにより、BigQueryのデータとAthenaのデータを突合することができます。
ですが内部的にはLambdaを動かしているためクエリの実行時間は15分までの制約があります。
さいごに
以上が現在のデータ分析環境の概要です。
環境構築の部分で未だ問題だと思っている点は
- Production AWSアカウント、Analytics AWSアカウント、Tableau 抽出機能でデータ更新タイミングを完全同期していない
- 求められるデータ鮮度の要件にもよりますが、スケジューラによる日次更新を行っているだけなので、Tableau上では1日~最悪2日程度データ更新にラグが発生します。
- Tableau 抽出機能については、Tableau REST APIを用いてAnalytics AWSアカウントのテーブル更新時に対象データソースの抽出を更新するようすればできなくはないと思っています。
-
高速化されたテーブルの更新が
DROP TABLE -> CREATE TABLEの為、実行中にクエリ実行されるとエラーになる- UNLOADを用いることで回避できますが、そうするとMySQLテーブルのスキーマが変更されたときに対応できません。いい方法を探しています。
です。今後はこの環境をもとにデータ利活用の促進をしていこうと思います。
ここまで閲覧いただきありがとうございました。何かしら参考になれば幸いです。
人材募集
現在、Wanoグループでは人材募集をしています。興味のある方は下記を参照してください。
Wano | Wano Group JOBS
TuneCore Japan | TuneCore Japan JOBS