はじめに
PyAthenaを使うとPython3上でSQLを書き、それを実行してAthenaでのクエリ実行結果のデータを取得、Pandas.DataFrameで展開することができます。
ですが、取得する対象のデータが大きくなると、とても時間が掛かるので良い方法が無いか探してみました。
環境・使用ライブラリ
- windows 10 Home Edition
- Python 3.7.6
- Jupyter Notebook (jupyter 1.0.0)
- pip 20.3.3
- s3fs 0.4.2
- pandas 1.2.0
- pyathena 1.10.0
- boto3 1.16.63
結果
クエリ実行結果が50000000行 x 10列のデータを1分6秒で取得することができました。
PyAthena connect関数を使用しpd.read_sql()した場合は4時間11秒でした。
20210227 更新
Dask.DataFrameとして取得した場合は57.6秒でした。PCメモリ容量が足りない場合はこちらのほうが良さそうです。
Daskである程度操作したあとに、compute()するのが良いと思います。
コードはGistで公開しています。
20211127 更新
awswranglerを使えばこんなことしなくても同等に早くなりました(50.8秒)
【AWS Athena】クエリ実行結果を高速に取得する v2【Python】
PyAthenaについて
PyAthena はPython DB API 2.0 に準拠したAmazon Athena用のクライアントです。
PyAthenaを使うと、Athenaコンソール上でできる操作がPython上でできるようになります。
クエリを書いて実行したデータを取得したり、TABLEやVIEWを作ったりできます。
import pandas as pd
from pyathena import connect
# AWS アクセスキー、シークレットキーを使用してAthenaへ接続
conn = connect(
aws_access_key_id = 'アクセスキー',
aws_secret_access_key = 'シークレットキー',
s3_staging_dir = 'クエリ実行結果保管URL',
region_name = 'リージョン'
)
# conn変数を使用してクエリの結果をpd.read_sqlでDataFrame化
%%time
query = """
SELECT * FROM "main_data"."riiid_train_data"
limit 10
"""
df = pd.read_sql(query, conn)
display(df)
実行結果
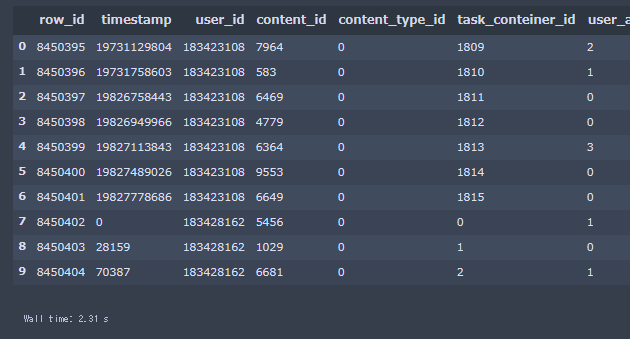
上記画像の様にクエリの実行結果をDataFrameとして取得することができました。
このように、Athenaコンソール画面を使わなくても、データを取得してここから分析や集計等することができます。とても便利です。
取得するデータ量が多い場合
limit句の数字を50000000にして、再度取得してみます。
10行取得→50000000行取得になるので、とても大きいデータになります。
%%time
query = """
SELECT * FROM "main_data"."riiid_train_data"
limit 50000000 -- 10から50000000に変更
"""
df = pd.read_sql(query, conn)
display(df)
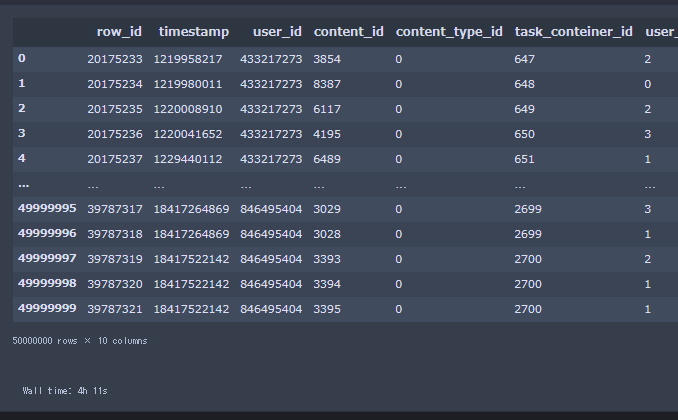
なんと4時間11秒かかりました。とても遅いです。
ちなみに、PyAthenaから実行したクエリもコンソールの履歴タブから見れますので、履歴を追ってDownload the results in CSV formatボタンからデータを落としてみましたが、ダウンロード時間は約8分と表示されました。
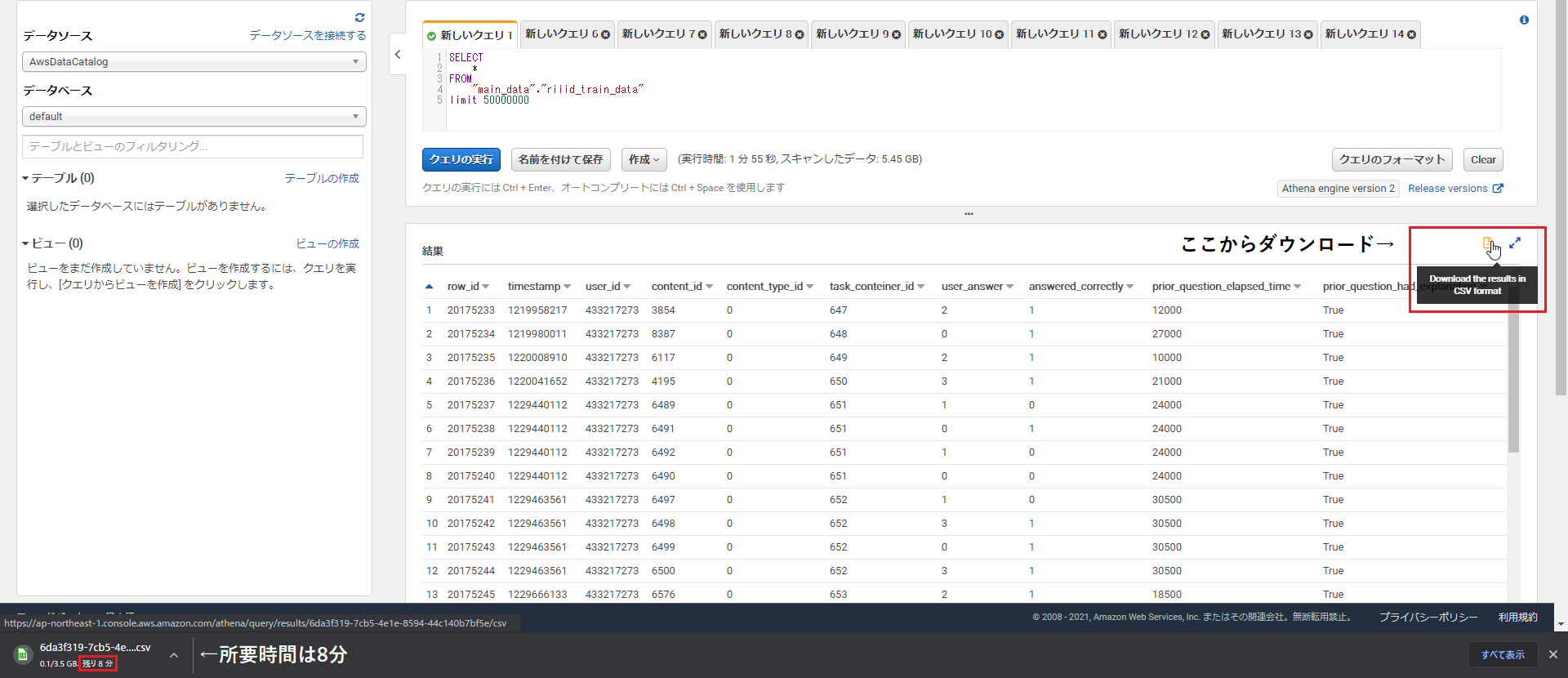
どの部分が問題で、所要時間の乖離が起きているのか詳しくは分からないですが、個人的にはクエリ実行結果が数百万行あたりから取得時間の遅さが目立ってきます。
高速に取得する方法
S3からクエリ実行結果のデータを直接取得します。
テーブルを作成する
実行するクエリのテーブルを作成します。
取得するデータ量が多い場合のクエリをCREATE TABLE ASして、まずはテーブルを作ります
cursor = connect(
aws_access_key_id = 'アクセスキー',
aws_secret_access_key = 'シークレットキー',
s3_staging_dir = 'クエリ実行結果保管URL',
region_name = 'リージョン'
).cursor() # conn変数と違うのは、最後に.cursor()が付きます。
# テーブルを作成
cursor.execute("""
CREATE TABLE main_data.fifty_million_data -- fifly_million_dataという名前でテーブルを作成する
WITH (format ='PARQUET') -- デフォルトでPARQUETですがわかりやすいように
AS SELECT * FROM "main_data"."riiid_train_data" limit 50000000 -- クエリは先程と同じ
""")
# テーブルプロパティを確認
query = """
SHOW CREATE TABLE main_data.fifty_million_data
"""
p_df = pd.read_sql(query, conn)
display(p_df)
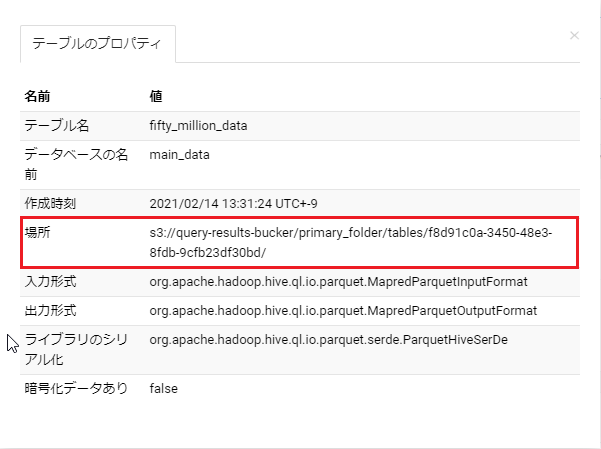
テーブルプロパティ
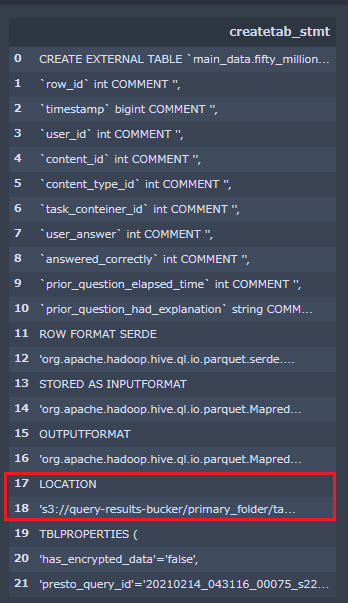
テーブルプロパティは、コンソールでも確認できます。
コンソールで指定したテーブルの3つ点マークをクリック→プロパティの表示

場所のURLにCREATE TABLE AS のクエリ実行結果のデータが入っています。
S3のデータを見てみる
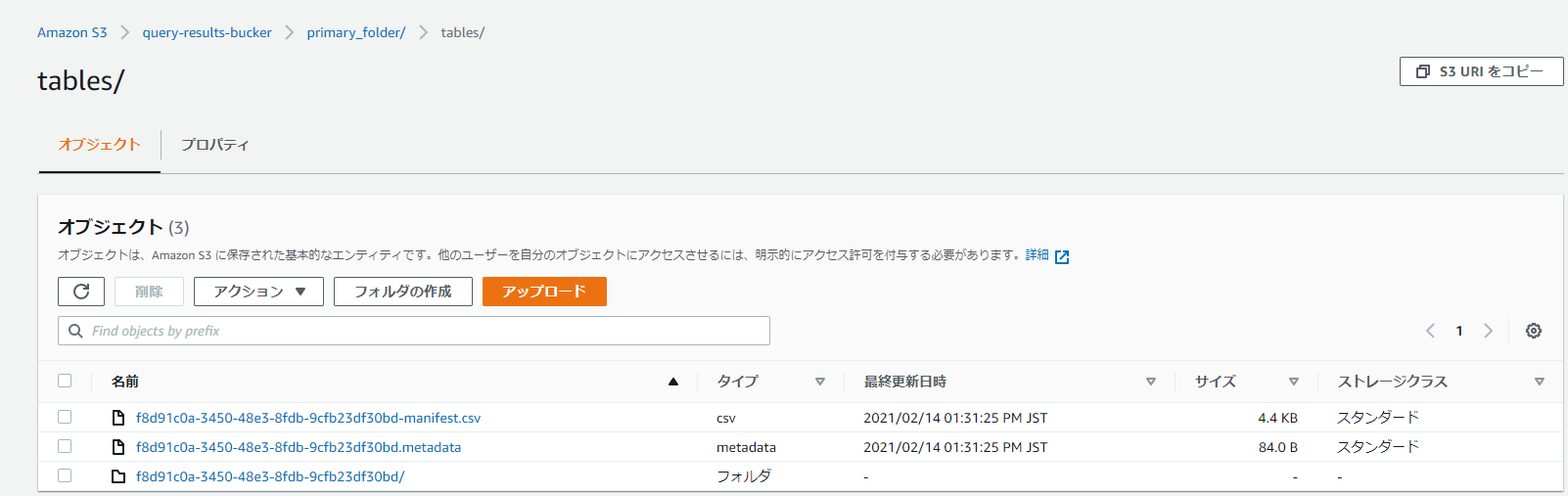
場所に記載されたURLにアクセスすると、manifest.csv,metadata,フォルダが格納されています。
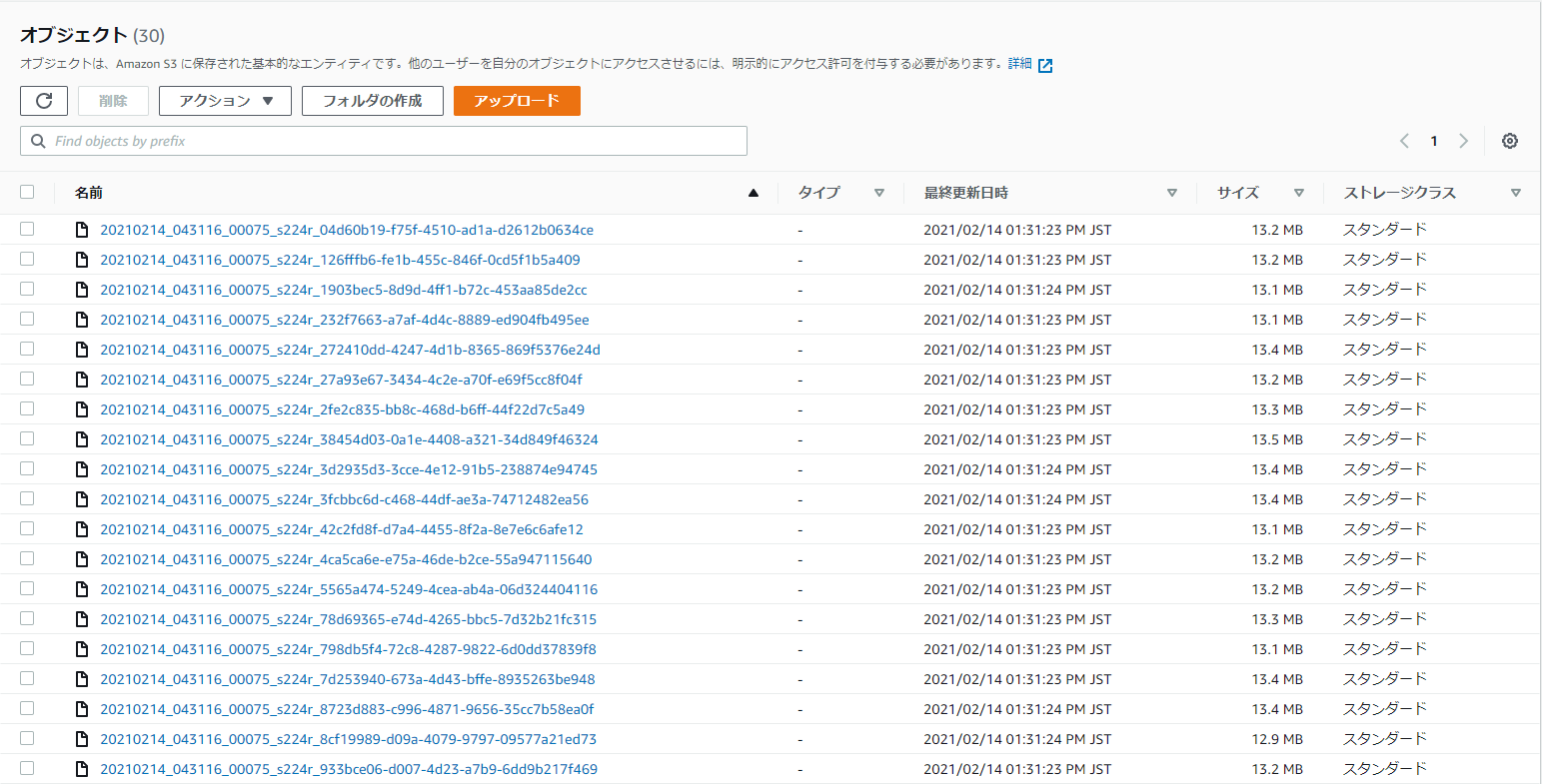
フォルダ内を見てみると、たくさんのparquetデータがあります。(拡張子の表示がないですがparquetです)
クエリの実行結果のデータは30個のparquetデータに分けられて、S3に保存されてるみたいです。
S3に保存されたデータを取得する
S3に保存されたデータを取得するには、まずそのURLが必要です。
先程も書きましたが SHOW CREATE TABLEでテーブルのプロパティデータを取得します。
query = """
SHOW CREATE TABLE main_data.fifty_million_data
"""
p_df = pd.read_sql(query, conn)
# LOCATIONの次のindexのデータを取得して、空白やシングルクォーテーションを除きます
data_location = p_df.iat[(p_df[p_df['createtab_stmt'] == 'LOCATION'].index + 1)[0], 0]
data_location = data_location.replace(' ','').replace("'","")
print(data_location)
data_locationの中身は's3://query-results-bucker/primary_folder/tables/f8d91c0a-3450-48e3-8fdb-9cfb23df30bd/'です。
作成したテーブルのデータが保存されている場所ですね。
urlparseを使用して、netlocとpathに分けます。
import urllib
scheme, netloc, path, params, query, fragment = urllib.parse.urlparse(data_location)
print(netloc)
print(path)
query-results-bucker(netloc)
/primary_folder/tables/490c0c37-5e0e-4bdf-9590-37b6a4f19204/(path)
boto3でS3へアクセス、ioでデータをPandas.read_parquetで読めるようにして、データを取得します。
import boto3
import io
def read_s3_multiple_parquets(filepath, bucket_name, athena_access_key, athena_secret_key):
# boto3.client,boto3.resourceにそれぞれアクセスキー、シークレットキーを入れて変数にします。
s3_client = boto3.client(service_name = 's3', aws_access_key_id = athena_access_key, aws_secret_access_key = athena_secret_key)
s3_resource = boto3.resource(service_name = 's3', aws_access_key_id = athena_access_key, aws_secret_access_key = athena_secret_key)
# 指定されたディレクトリからファイル名を取得します。30個のparquetファイルのことです。
s3_keys = [item.key for item in s3_resource.Bucket(bucket_name).objects.filter(Prefix = filepath)]
# それぞれpd.read_parquetして、DataFrame化します。
dfs = []
for key in s3_keys:
obj = s3_client.get_object(Bucket = bucket_name, Key = key)
dfs.append(pd.read_parquet(io.BytesIO(obj['Body'].read())))
# すべて結合した状態で返します。
return pd.concat(dfs)
# read_s3_multiple_parquets関数を実行します。
df = read_s3_multiple_parquets(path[1:], netloc, athena_key.access(), athena_key.secret())
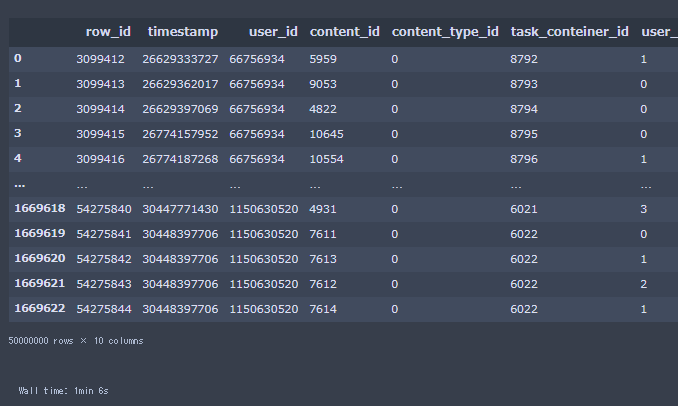
display(df)
取得できました。かかった時間は1分6秒です。
データを削除する
最後に、CREATE TABLE AS して作成したテーブルと、テーブルのために作成されたS3のデータを削除します。
# テーブルを削除
cursor.execute("""
DROP TABLE main_data.fifty_million_data
""")
# S3上のデータは消えないので、それも消します
import s3fs
fs = s3fs.S3FileSystem(key = 'アクセスキー', secret = 'シークレットキー')
# データフォルダと、metadata, manifest.csvを削除
fs.rm(data_location, recursive = True)
fs.rm(data_location[:-1] + '.metadata')
fs.rm(data_location[:-1] + '-manifest.csv')
所要時間結果
テーブルを作成する~データを削除するまでの実行時間で、1分6秒になりました。
すべてを連結して時間を計測したコードはGistに乗せていますので、気になる方は見てみてください。
最後に
大幅に短縮できたので個人的には嬉しいですが、もっとスマートなやり方があれば教えてほしいですm(__)m