こんにちは皆さん
機械学習が流行っているわけですが、自分で実装するのって、けっこう大変なんですよね。
人真似を書くことはできても、オリジナルの問題を作るのってどうすればいいのだろう?ってなります。
そこで、今回は機械学習もしくはそれに類似した方法で適当な問題を解いてみようと考えたわけです。
蓋を開けてみると、よくわからない最適化問題になってしまいましたが。。。
とりあえず問題設定
カードバトル
レガシーなカードバトルを考えてみましょう。
- プレーヤには属性があり、3つの中から選べる
- カードにもプレーや同様に属性があり、各カードごとに固定である
- プレーヤは攻撃側と防御側に別れ、それぞれカード5枚からなるデッキを作る
- 各々のカードはスキルを持っていることがあり、それぞれ確率でデッキのパラメータを変動させる
- スキルの発動率はデッキの先頭のカードから判定が始まり、初めは100%だが、一回発動するごとに25%ずつ下がる
- プレーヤの属性と自分のデッキにあるカードの属性が一致すると、そのカードはパラメータが強化される
- 最終的に攻撃側の攻撃力(attack)と防御側の防御力(defence)の値を比較し、攻撃側の攻撃力のほうが大きければ攻撃側の勝利とし、そうでなければ防御側の勝利とする
回りくどい書き方ですが、要は5vs5のカード対戦です。昔のソシャゲでは割とポピュラーな部類のルールだと思います
目的
はじめに述べたとおり、今回の目的は最強のデッキを組むことです。
とはいえ、何を持って最強というのかはなかなかに難しい問題です
そこで、次のように目的を設定しましょう
「自分の属性と相手の属性を入力とし、300種類のカードの中から5枚( 重複含む )選んで、最も勝てそうなデッキを組んでもらう」
こんな感じで、相手に応じてベストなデッキを組んでもらいましょう
訓練方針
訓練方法
訓練方法は至って簡単です
- 攻撃側と防御側の属性をランダムで生成する
- それに従い、攻撃側と防御側のデッキをエージェントに生成してもらう
- 生成されたデッキで対戦をし、勝敗をエージェントにフィードバックする
これだけです。
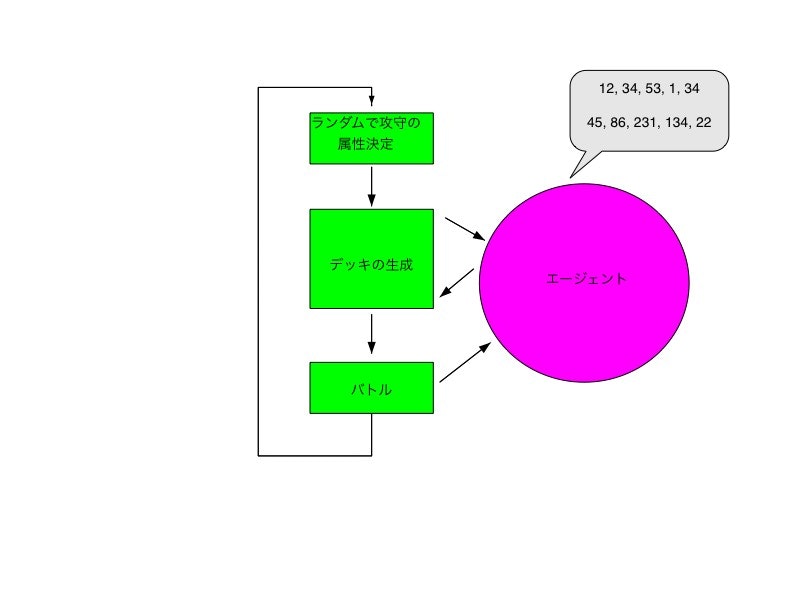
これだけだと簡単なのですが。。。
パターンの多さ
ここで問題になるのはデッキのパターンの多さです。
今回の問題設定で、カードの枚数は300枚あるわけですから、その組み合わせは単純に$300^5$となり、さらに入力の属性パターンが$3 \times 3$あるので、21兆9千億通りのパターンが有ります。
流石にこれを全部網羅するのは無理です。
少なくとも私のPCにそんな能力はないです。。。
単純化
そこで、問題を単純化します。
今回はカードの組み合わせをあえて考えず、
「デッキのn番目のカードがどれであれば勝ちやすいか」
を求めることにしました。
つまり、デッキの各位置のカードがそれぞれ勝ちやすいカードであれば、そのデッキは勝ちやすいと見ていいんじゃないか、という安易な思考になります。
一応、ランダムな組み合わせ相手であれば、生成したデッキの勝率は95%程度でした。
カード自体もランダム生成で作っているので、性能が似通ったものが多いのですが、割といい確率かなと思います
実装
実装は以下のリポジトリにおいてあります
https://github.com/niisan-tokyo/cardagent
糞コード乙ですな。。。
PHP7 以降でないと動かないです
今回は事細かな実装の解説はせず、要点だけ見ていきます
訓練
エージェントの訓練メソッドは以下のとおりです
public function train($myType, $enType)
{
$this->random = true;
$this->temp = [
'myType' => $myType,
'enType' => $enType
];
if ($this->count > $this->training_count and $this->epsiron > $this->min_epsiron) {
$this->epsiron -= $this->diff_epsiron;
}
$this->count++;
if (mt_rand(1, $this->max_epsiron) < $this->epsiron) {
return $this->random($myType, $enType);
}
$this->random = false;
return $this->recommend($myType, $enType);
}
ここでエージェントは、ランダムなデッキを生成するか、現在の訓練モデルに従って推薦デッキを生成します。
訓練初期はモデルが未熟なので、必ずランダムなデッキを生成します
訓練中期になると、ある程度モデルが出来上がってきているので、そのモデルに従って、推薦デッキを生成するようになります。
訓練後期では基本的にモデルに従ってデッキを生成するようになります。ただし、いくらかの割合でランダムにデッキを生成するようにしてあります。
フィードバック
戦闘の勝敗に従い、フィードバックを行います。
フィードバックのコードは以下のとおりです。
public function feedback($result)
{
$myType = $this->temp['myType'];
$enType = $this->temp['enType'];
$res = ($result > 0)? 1 : 0;
foreach ($this->temp['cards'] as $key => $val) {
$tmp = $this->model[$myType][$enType][$key][$val];
$tmp[1]++;
$tmp[0] = ($tmp[0] * ($tmp[1] - 1) + $res) / $tmp[1];
$this->model[$myType][$enType][$key][$val] = $tmp;
}
}
フィードバックで行われているのは、ちょっとわかりにくいですが、勝率の更新です。ここで使用しているモデルは、以下の様な構造をしてます
print_r($this->model);
[1] =>[// 自分の属性が1の時
[1] => [// 相手の属性1の時
[1] => [// デッキの1番目の位置が
[1] => [// 1番のカードである場合に勝つ確率は
[0] => 0.13// 13%
[1] => 34// このカードが今まで選ばれた回数は34回
],
[2] => [
...
結構複雑な感じに見えますが、実際はそんなに大したものではないです。
ただ、要素数が非常に多いので、実際にprint_rなんてやると、非常に時間がかかります
訓練の実行
訓練は以下のようにして開始します
$ composer dump-autoload
$ php train.php
ループ回数を変えることで、精度を変えられるかもしれません
現時点では1000000回ループを回しています
デッキの生成
訓練後、エージェントにデッキを生成してもらうには以下のようにします
$ php recommend.php
1 # 攻撃側の属性
1 # 防御側の属性
攻撃側
Array
(
[0] => 144
[1] => 249
[2] => 137
[3] => 28
[4] => 247
)
...
防御側
Array
(
[0] => 113
[1] => 22
[2] => 210
[3] => 263
[4] => 105
)
...
attacker: 同属性補正による攻撃力アップ!! -> 3089
defender: 同属性補正による防御アップ!! -> 14603
defender: 敵属性防御力低下 -> -32129
defender: 敵属性防御力低下 -> -32129
defender: 全体防御力低下 -> -19472
defender: 自属性防御力強化 -> 29207
defender: 自属性防御力強化 -> 29207
result: 104188 VS 86645 ->
自分の属性と相手の属性を入れると、それに応じて攻撃側、防御側それぞれのデッキを生成してくれます。
最後に、攻撃側と防御側のエージェント同士によるエキシビジョンマッチが行われます。
今回は攻撃側が勝ちました。
ついでにランダム戦闘で勝敗を見てみます
$ php randomBattle.php
47404 VS 2596
50000回中47404回勝っているので勝率は95%程度です
もう少し高くなって欲しかったけど、運が絡むのだろうか。。。
まとめ
もう少し改良の余地がありそうですが、今回はこの辺りで。
機械学習の話は色んなところ出ているのですが、実際に実装するとなると、どうしたら良いかわからなくなるので、このあたりの簡単な問題で練習してみるのはありかなと思いました