皆さんこんにちは
最近Laravel触っててEloquentめっちゃ使いやすいやん!とか、composerも名前空間もないけど、Active Recordの仕組みが良くできているYii Framework1.1 をベースにしておきながら、Active Recordをガン無視する暴挙に出た生ゴミに出会ったりとかしました。
そんな感じで、新旧のいいものとそれを使いこなせずに醜悪なゴミにしている事例を間近に見ているので、イライラを原動力にORMって何がいいんだっけってところを見直してみようかと思います。
オブジェクト関係マッピング (ORM: Object-relational mapping)
原語も訳語も違和感しかないのですが、ここで言う「関係」とは、別にモノ同士のつながりとかではなく、単純に「リレーショナルデータベース」のことを指しているようです。
Wikipediaにある説明は案の定よくわからんものになっています。
そこで、とりあえず自分なりに理解した範囲で、ORMの意味と意義について振り返ってみます。
ORMの概要
ORM以下の機能のまとまりのことをいいます。
- データベースからデータを取得する
- 取得したデータをオブジェクト化する
- データの更新・変更などをデータベースに格納する
私のように、業界に来てから2年以上ORMに触っていなかった人間にとって、データをわざわざオブジェクト化する理由がしばらく理解できませんでした。
cake1.3の時代はORMと言うなの連想配列だったし、codeigniter ではクエリビルダの機能しか使っておらず、データはすべて配列で取っていました。
ではなぜデータをオブジェクト化するのかの理由を、順に見ていきましょう。
テーブルデータの構造
リレーショナルデータベース(RDB)は、インデックスとか外部キーの構造を除けば、基本的には以下のような表型のデータ構造を持っています。
mysql> select * from boards;
+----+--------+----------+---------------------+---------------------+
| id | title | content | created_at | updated_at |
+----+--------+----------+---------------------+---------------------+
| 1 | title1 | content1 | 2016-10-08 00:00:00 | 2016-10-08 00:00:00 |
| 2 | title2 | content2 | 2016-10-08 00:00:00 | 2016-10-08 00:00:00 |
| 3 | title3 | content3 | 2016-10-08 00:00:00 | 2016-10-08 00:00:00 |
+----+--------+----------+---------------------+---------------------+
3 rows in set (0.00 sec)
このデータを扱うのに、PHP的に最も直感的なのは連想配列でしょう
$record[1] = [
'id' => 1,
'title' => 'title1',
'content' => 'content1',
'created_at' => '2016-10-08 00:00:00'
'updated_at' => '2016-10-08 00:00:00'
]
これで十分だと思っていた時期が私にもありました。。。
オブジェクト
オブジェクト指向じゃなくて、オブジェクトです。
オブジェクトの説明って、各所にあるのですが、「オブジェクトとはモノだ!」という説明を見ると、ちょっと首をひねってしまうのですよね。
プログラム的にはただのテキストだし、それがモノだって言われてもねぇ。。。
個人的に最もしっくり来た説明は、情報処理試験の教科書にあった、「データと処理のまとまり」ですかね。
あるデータがあったとき、そのデータに対する処理の方法も大体決まっている、という考えると、わりと自然な概念かなとか思います。
で、この最も単純な概念からすると、まさにデータの塊であるデータベースを、オブジェクトを使って処理したいという欲望が出てくるのは、自然なことだと思います。
しかし、テーブルデータは単純な連想配列みたいなものなので、オブジェクトとして使うには自前でオブジェクト化するための仕組みを作らなければならなかったのですが、そういう知見が溜まってきて、一般化したのがORMです。
さて、PHPにも当然ながらORMはあります。
最近私が使っているのはLaravelが提供しているEloquentですので、Eloquentを例にしてORMの使い所を探っていきましょう。
ORMの便利なところ
1. SQLを書かなくていい!
全部がそうじゃないのかもしれませんが、あらかたのORMは、SQLを直に書かなくとも、データベースからデータを引っ張ってこれます。
むしろ、SQLを書いちゃうと、オブジェクト化ができなかったりします。
例としてEloquentを使ってデータを一つ取得してきて、更新するやり方を見てみましょう。
$id = $_POST['id'];
$board = Board::find($id);
$board->title = 'テスト';
$board->content = 'テスト本文';
$board->save();
とても単純なコードですが、ログを見ると、ここでは以下の2つのSQLが走っています。
"statement":"select * from `boards` where `boards`.`id` = ? limit 1","binds":["1"]
"statement":"update `boards` set `title` = ?, `content` = ?, `updated_at` = ? where `id` = ?","binds":["テスト","テスト本文","2016-10-10 02:31:29",1]
今回はEloquentを例に使っていますが、PhalconやCakePHPのORMでも同じようなSQLが走ると思います。
ここで重要なことが2つありますので、少しだけ解説します。
1.1 SQLという「別言語」を混在させずに済む
まず、SQLはPHPとは違う言語です。
SQLを直書きするということは、PHPの中に別言語が紛れ込むことを意味しており、可読性が落ちやすくなります。
IDEを使っている場合、PHPのチェックや予測はしてくれるけど、SQLのチェックはしてくれないとか、開発時点でも割と不便だったりします。
あと、個人的な所感ですが、SQLの直書きが許されている場合、似たようなSQLが量産される傾向にあるように思います。
当然ORMを使うことで、SQLはORMが組み立ててくれるので、SQL文字列をこちらで作る必要がなくなります。
1.2 「よい」SQLを作ってくれる
出力されたSQLを見ると、バインド変数を使ってクエリを生成しています。
これはSQLインジェクションに対する対処としては定石となる手法ですが、手で書こうとすると割と面倒だったりします。
OSS製のORMだと、だいたいこのような定石に沿ったSQLを作ってくれるので、例えば私のようにSQLド素人がコソコソ書くようなクソSQLに比べ、質の良いSQLが生成されます。
2. ゲッター・セッターの仕組みを利用できる
例えば、データが作成された日付が、データベース上は'2016-10-15'だったとき、日本人的には'2016年10月15日'と表示したいものです。
もしくは、自前でパスワードの方式を作るとき、データを格納するときには自動的に暗号化してほしいという欲求が出てきます。
そんなときはセッターやゲッターを使うと、データの使用者がデータの形式を気にすることなく値の処理を行うことができます。
以下はEloquentでセッター・ゲッターを使った例です(Laravel的にはmutator: 変異)
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
use Carbon\Carbon;
class Member extends Model
{
protected function getCreatedAtAttribute($value)
{
$date = Carbon::parse($value);
return $date->format('Y年m月d日');
}
protected function setPassAttribute($value)
{
$this->attributes['pass'] = bcrypt($value);
}
}
これに対して、以下のコードを見てみます
$member = new Member();
$member->pass = 'superman!';
// ここでセッター
echo $member->pass;// $*******$5KFRsOhtBR3v****r12SBeK.nna****oLR8****I8*********KO6
$member->save();// ちなみに、ここで$memberにidプロパティがセットされている
$test = Member::find($member->id);
// ここでゲッター
echo $test->created_at;// 2016年10月15日
ここで実行コード中では、データに対してメソッドではなくプロパティでアクセスしています。
つまりユーザー( ここでは開発メンバー )はデータに対して特に処理を意識することなく、データの入出力を単純なプロパティの読み込み・書き込みで済ますことができるわけです。
ここで得られる恩恵は以下のとおりです。
- ユーザーがデータの扱い方を意識しなくて良い
- データの処理を省略できるので、コード量を節約できる
- ORM定義に処理をまとめることができる
ちなみに、このようなゲッター・セッターの仕組みをPHPで提供するには、 マジックメソッドという独特の仕組み を使います。
3. 所有関係を定義できる
例えば、あるメンバーが複数のアイテムを持っているとしましょう。
このとき、両者の関係は以下のようになっています。
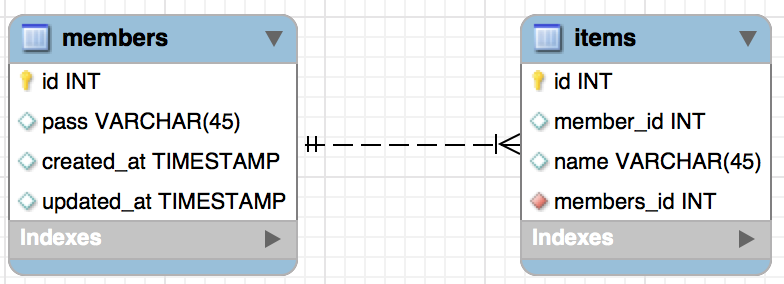
この関係のもと、誰が何を持っているのかを取得することを考えてみます。
まず、普通のSQLで取得してみましょう。
SELECT members.id AS memid, items.id AS itemid, items.name
FROM items LEFT JOIN members ON items.member_id = members.id;
+-------+--------+----------+
| memid | itemid | name |
+-------+--------+----------+
| 5 | 1 | nihil |
| 5 | 2 | non |
| 5 | 3 | nam |
| 6 | 4 | vel |
| 6 | 5 | possimus |
| 6 | 6 | voluptas |
+-------+--------+----------+
6 rows in set (0.00 sec)
当然ですが、SQLで取得できる結果は単なる表データですので、ここから直接所有関係を見ることはできません。
つまり、コードの中で直にSQLを書くと、ついでにデータの所有関係構造を追加で書く必要があるというわけです。
一方、ORMの多くはこのような関係構造を予め定義しておくことで、所有関係を簡単に表せるような仕組みを持っています。Eloquentにもそのような機能があります。
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
use Carbon\Carbon;
class Member extends Model
{
// 中略
public function items()
{
return $this->hasMany(Item::class);
}
}
一行hasManyメソッドを使用することで、関係性を定義しています。ここでは「Itemクラスのデータを複数所持している」を表しています。
では、データの例を見てみましょう。以下のようなコードを書いてみます。
$members = Member::with('items')->get();
foreach ($members as $member) {
echo $member->id . " has fallowing items:\n";
foreach ($member->items as $item) {
echo ' ' . $item->name . "\n";
}
}
これを実行すると
5 has fallowing items:
nihil
non
nam
6 has fallowing items:
vel
possimus
voluptas
となります。
ここで見てわかるように、$membersの各要素$memberには、itemsというプロパティが存在していて、これの正体はapp\Itemのインスタンスになっています。つまり、Member -> Item という階層構造がここに実現できていることになります。
もちろん、生のSQLで取得したデータを自分で組み直せば、同様の構造は作れますが、ORMの仕組みを使ったほうが簡単だと思います。
ORMのデメリット
1. SQL問題
ORMで取得したオブジェクトは、その後内容を編集し、再びDBに保存することを念頭に置いていますので、なるべくテーブルデータに即したデータ構造であってほしいわけですが、オリジナルのクエリで取得されるデータはそうなっていない可能性が高いので、SQLを自作すると、ORMのオブジェクトが使えなかったりします。
よって、SQLの使用はかなり制限されます。
これに伴い、以下の問題が発生します。
1.1 SQLを書かない
これは利点でもありましたが、難点でもあります。
要するに、SQLをバリバリ書ける人にとっては、SQLが勝手に生成されるORMは自由度がないと思うかもしれません。
1.2 JOINを使わないかもしれない
正確には使わないORMもあるという感じです。
ORMの便利な点で述べた所有の概念ですが、Eloquentの裏でどのようなSQLが走っているのかを見てみましょう。
"statement":"select * from `members`","binds":[]
"statement":"select * from `items` where `items`.`member_id` in (?, ?, ?, ?, ?)","binds":[2,3,4,5,6]
このようにクエリが2つ走っていますし、バインド変数を使っているので、通信回数に関してはもとのJOINを使った場合に比べて4倍になってしまっています。
このあたりは性能を気にする人にとってはかなり引っかかる部分かもしれません。
CakePHPだとJOINを使うかもしれません
とはいえ、これが絶対に悪いかというと、実はそうとも言い切れません。
各SQLは一つのテーブルに対する検索を行っているので、DBに対してはそれほど大きな負荷をかけていません。
一方でJOINを使うと、2つのテーブルを走査することになるので、感覚的には掛け算で負荷が大きくなるように思います。
ゲーム系とかのアクセス数が多いサイトの運営をしていたときは、JOIN禁止だったりしました。
ちなみに、PhalconはこのようなSQL書きたい派の人たちにも配慮した、PHQLという独自クエリ言語を用意したりしています。
2. 嫌ってる人がいる
こんなものを書いている人もいます。
ORMは不快なアンチパターン
外国人のyegorって人の書いたやつを翻訳したものらしいです。
まあ、彼らが使っているORMは、PHPerから見ればコード量が多くてややこしいとしか思えないんじゃないかと思います。
ゲッターやセッターは特別な処理が必要であるときだけ書いて、それ以外はそのまま格納できるということにしてくれれば楽なんですが、PHPのマジックメソッドみたいなことはできないのかしら?
あと、オブジェクト指向崇拝主義者なのか、オブジェクト指向とORMについて力説していますが。。。その辺もよくわからんというか、私はオブジェクト指向言語ではないPHPerなので、そんなもんにこだわってないだけかもしれんですな。
他にもDBAからしてみれば生のSQLを書いていないので、どのようなSQLが吐き出されているのかわからんとも思うかもしれません。
この辺はSQLのログは吐き出すようにしておきましょうってことですかね。
3. N+1問題
先程所有の問題で出したコードにはさり気なく対策があったのですが、例えば次のようなコードでも同様の動作をしてくれます。
$members = Member::all();
foreach ($members as $member) {
echo $member->id . " has fallowing items:\n";
foreach ($member->items as $item) {
echo ' ' . $item->name . "\n";
}
}
コードも短くなっていいようにみえるのですが、吐き出されているSQLが問題です。
"statement":"select * from `members`","binds":[]
"statement":"select * from `items` where `items`.`member_id` = ? and `items`.`member_id` is not null","binds":[2]
"statement":"select * from `items` where `items`.`member_id` = ? and `items`.`member_id` is not null","binds":[3]
"statement":"select * from `items` where `items`.`member_id` = ? and `items`.`member_id` is not null","binds":[4]
"statement":"select * from `items` where `items`.`member_id` = ? and `items`.`member_id` is not null","binds":[5]
"statement":"select * from `items` where `items`.`member_id` = ? and `items`.`member_id` is not null","binds":[6]
大量のSQLが発行されてしまいました。
これはプロパティitemsが呼び出されるたびに、各オブジェクトごとにhasManyに従ったSQLが発行されているからです。
もし、membersのデータ数が100ことかあれば、101個のクエリが発行されることになります。
これがN+1問題というらしいです。
先に答えが出ちゃってますが、Eager Loardingという仕組みを使うことにより、itemsについてのクエリを一つにまとめることができます。
Eloquentではこれはwithメソッドで解決しています。
CakePHPのORMだと、そもそもEager Loadingになっているらしいです。
まとめと個人的な所感
ORMはデータベース上のデータをオブジェクトとして扱うことのできる仕組みで、OSS製のORMであればセキュリティや負荷の面でも十分な品質と性能を持っていると思います。
個人的にはアプリでDBを扱うのなら、ORMを使うのが無難だと思います。
例えSQLを書くのに自信があったとしても、データの取り扱い方をORMで一括で定義したほうが管理しやすいし、プレースホルダ付きのクエリをいちいち書くのも私のようなズボラな人間にとっては面倒くさいです。
ORMはまた、沢山の種類があります。
我々PHPerはcomposerという強力なツールで、ライブラリを簡単に落とせるので、使い比べるのもありかなぁとか思っています。
PhalconのORMはエクステンションなんで、だめですが。。。
今回はこんな感じです。
エンジニアにとって、コード量を少なく可読性をよくできることが、ソフトウェアの品質を上げる有効な手段でありますので、ORMで品質が良くなるのであれば、ガンガン導入していきたいです。
参考
https://laravel.com/docs/5.2/eloquent-relationships
http://book.cakephp.org/3.0/ja/orm/entities.html
https://docs.phalconphp.com/ja/latest/reference/models.html