1.イントロダクション
昨年の夏頃から筑波大学 准教授の落合陽一さんに興味をもち、彼の著書や講演,Twitter(@ochyai)を見ています。
彼の行動やその交友の広がりをみていると、エンターテーメントで面白く感化されます。
そんな落合さんが,8月上旬からTwitterでの攻撃的かつ悪意のある反応(ここでの”クソリプ”の定義)に対して、それを流すような空気ではなく、しっかりと対応・反論し、インターネット世界のネガティブな空気をなくそうとされています。
私はネットは善意の世界と思って(願って)おり、プログラムに関してネットの各種の質問箱にわからないことを聞くと、ほんの数時間で回答があり、世界中に仲間がいる気分です。そして、私からのコントリビューションが、このQiitaになります。
前置きはさておき、そういったリプ対応がどれほど効果があるのか、根っからの実験屋の私には高い関心があります。関心は学習の燃料となり、今回の考察につながりました。
では、Twitterのツイート数のトレンドから何がわかるのか、解析し考察してみます。
注意: この考察は個人の見解であり,不特定多数の同意ではありません
2. Twitter取得プログラム
TwitterのAPIを使ってツイートを取得します。
取得方法について、こちらの方のページを参考にしました。ありがとうございます。
Twitterのツイートの取得のためには、Twitterのアカウント登録(Consumer Key、Consumer Secret、Access Token、Access Token Secret)が必要です。取得方法は以下を参考にしました。
Twitter API Key を取得する方法
一度に取得できるツイートは15000件程度であり、そのあとは15分ほど接続を待つ必要があります。
Twitterのデータ取得のプログラムは、以下のページを参考にさせていただきました。
データで見るM1グランプリ2017 〜データ取得編〜
ここでは、ツイート内容を検索して、その条件に合致するものを取得します。
今回は落合さん自身のツイートも取得し、落合さんのツイートに対するリプライを見る必要があります。そのプログラムとして以下を追加しています。
class TweetsGetterByUser(TweetsGetter):
'''
ユーザーを指定してツイートを取得
'''
def __init__(self, screen_name):
super(TweetsGetterByUser, self).__init__()
self.screen_name = screen_name
def specifyUrlAndParams(self):
'''
呼出し先 URL、パラメータを返す
'''
url = 'https://api.twitter.com/1.1/statuses/user_timeline.json'
params = {'screen_name': self.screen_name, 'count': 200}
return url, params
def pickupTweet(self, res_text):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
results = []
for tweet in res_text:
results.append(tweet)
return results
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
remaining = res_text['resources']['statuses']['/statuses/user_timeline']['remaining']
reset = res_text['resources']['statuses']['/statuses/user_timeline']['reset']
return int(remaining), int(reset)
そして、取得したツイートデータから、5分間でのツイート数を積算カウント(Index)し、それを時系列のトレンドグラフを作成します。
# 各シリーズをデータフレーム化
m1_df = pd.concat([created_at, text], axis=1)
# カラム名
m1_df.columns = ['created_at', 'text']
# csvファイルとして保存。 ツイート内容も含む。
m1_df.to_csv('ochiai180819.csv', sep='\t', encoding='utf-16')
# 各シリーズをデータフレーム化
m2_df = pd.concat([created_at],axis=1)
# カラム名
m2_df.columns=['created_at']
# csvファイルとして保存。ツイート時の時刻のみを保存。
m2_df.to_csv('ochiai1808191.csv', sep = ',',encoding='utf-8')
# CSV ファイル (employee.csv) として読み込む
df2 = pd.read_csv('ochiai1808191.csv', sep=',', parse_dates=['created_at'], engine='python')
df3 = df2.set_index('created_at').resample('5T').count() #5Tが5分毎のパラメータ。
df3.columns = ['Index']
# csv ファイルとして出力。別のプログラムで使用するために別保存。
df3.to_csv('ochiai1808192.csv', sep =',', encoding='utf-8')
# matplotlibを使ってグラフ化する
df3.plot()
# df3.plot(logy=True) # Y軸を対数表示するときは有効にする
plt.title("Twitter Trend")
plt.xlabel("Date")
plt.ylabel("The number of twitter")
pylab.savefig('ochiai180819.png') # 保存するグラフのファイル名
これで、ツイート内容や発信時刻や、その時間トレンドへのデータの変換、グラフ化もできます。
ここで、プログラム全体を示します。
環境
Python 2.7
ライブラリ;
requests_oauthlib,jsondatetime, time, sys, abc, pandas, matplotlib.pyplot, pylab, dateutil.parser
注意事項
・時刻は世界標準時間(UST:Universal Standard Time) 日本時刻への変換は、この時刻に+9時間。
・下記のプログラムは、”キーワードでの検索”を実行する。対象のアカウント(今回は"ochyai")のときは、’ユーザを指定して取得’を有効にする。(キーワードで検索は、#で無効にする)
# coding:utf-8
from requests_oauthlib import OAuth1Session
import json
import datetime, time, sys
from abc import ABCMeta, abstractmethod
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
import pylab
from dateutil.parser import parse
CK = '********************'
CS = '**********************************'
AT = '**********************************'
AS = '**********************************'
class TweetsGetter(object):
__metaclass__ = ABCMeta
def __init__(self):
self.session = OAuth1Session(CK, CS, AT, AS)
@abstractmethod
def specifyUrlAndParams(self, keyword):
'''
呼出し先 URL、パラメータを返す
'''
@abstractmethod
def pickupTweet(self, res_text, includeRetweet):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
@abstractmethod
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
def collect(self, total=-1, onlyText=False, includeRetweet=False):
'''
ツイート取得を開始する
'''
# ----------------
# 回数制限を確認
# ----------------
self.checkLimit()
# ----------------
# URL、パラメータ
# ----------------
url, params = self.specifyUrlAndParams()
params['include_rts'] = str(includeRetweet).lower()
# include_rts は statuses/user_timeline のパラメータ。search/tweets には無効
# ----------------
# ツイート取得
# ----------------
cnt = 0
unavailableCnt = 0
while True:
res = self.session.get(url, params=params)
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
tweets = self.pickupTweet(json.loads(res.text))
if len(tweets) == 0:
# len(tweets) != params['count'] としたいが
# count は最大値らしいので判定に使えない。
# ⇒ "== 0" にする
# https://dev.twitter.com/discussions/7513
break
for tweet in tweets:
if (('retweeted_status' in tweet) and (includeRetweet is False)):
pass
else:
if onlyText is True:
yield tweet['text']
else:
yield tweet
cnt += 1
if cnt % 100 == 0:
print ('%d件 ' % cnt)
if total > 0 and cnt >= total:
return
params['max_id'] = tweet['id'] - 1
# ヘッダ確認 (回数制限)
# X-Rate-Limit-Remaining が入ってないことが稀にあるのでチェック
if ('X-Rate-Limit-Remaining' in res.headers and 'X-Rate-Limit-Reset' in res.headers):
if (int(res.headers['X-Rate-Limit-Remaining']) == 0):
self.waitUntilReset(int(res.headers['X-Rate-Limit-Reset']))
self.checkLimit()
else:
print ('not found - X-Rate-Limit-Remaining or X-Rate-Limit-Reset')
self.checkLimit()
def checkLimit(self):
'''
回数制限を問合せ、アクセス可能になるまで wait する
'''
unavailableCnt = 0
while True:
url = "https://api.twitter.com/1.1/application/rate_limit_status.json"
res = self.session.get(url)
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
remaining, reset = self.getLimitContext(json.loads(res.text))
if (remaining == 0):
self.waitUntilReset(reset)
else:
break
def waitUntilReset(self, reset):
'''
reset 時刻まで sleep
'''
seconds = reset - time.mktime(datetime.datetime.now().timetuple())
seconds = max(seconds, 0)
print ('\n =====================')
print (' == waiting %d sec ==' % seconds)
print (' =====================')
sys.stdout.flush()
time.sleep(seconds + 10) # 念のため + 10 秒
@staticmethod
def bySearch(keyword):
return TweetsGetterBySearch(keyword)
@staticmethod
def byUser(screen_name):
return TweetsGetterByUser(screen_name)
# キーワード検索でツイートを取得します。以下の通り、キーワード検索によるツイート取得関数を定義します。
class TweetsGetterBySearch(TweetsGetter):
'''
キーワードでツイートを検索
'''
def __init__(self, keyword):
super(TweetsGetterBySearch, self).__init__()
self.keyword = keyword
def specifyUrlAndParams(self):
'''
呼出し先 URL、パラメータを返す
'''
url = 'https://api.twitter.com/1.1/search/tweets.json?'
params = {'q': self.keyword, 'count': 100}
return url, params
def pickupTweet(self, res_text):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
results = []
for tweet in res_text['statuses']:
results.append(tweet)
return results
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
remaining = res_text['resources']['search']['/search/tweets']['remaining']
reset = res_text['resources']['search']['/search/tweets']['reset']
return int(remaining), int(reset)
created_at = []
text = []
# ユーザを指定して発信したツイートを取得します。
class TweetsGetterByUser(TweetsGetter):
'''
ユーザーを指定してツイートを取得
'''
def __init__(self, screen_name):
super(TweetsGetterByUser, self).__init__()
self.screen_name = screen_name
def specifyUrlAndParams(self):
'''
呼出し先 URL、パラメータを返す
'''
url = 'https://api.twitter.com/1.1/statuses/user_timeline.json'
params = {'screen_name': self.screen_name, 'count': 200}
return url, params
def pickupTweet(self, res_text):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
results = []
for tweet in res_text:
results.append(tweet)
return results
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
remaining = res_text['resources']['statuses']['/statuses/user_timeline']['remaining']
reset = res_text['resources']['statuses']['/statuses/user_timeline']['reset']
return int(remaining), int(reset)
# キーワードで取得
getter = TweetsGetter.bySearch(u'@ochyai AND -filter:retweets AND until:2018-8-19_00:00:00_UST')
# ユーザーを指定して取得 (screen_name)するときは、ここを有効にします。ユーザ名でデータ取得は、取得日から前1ヶ月間のツイートが取得できます。
# getter = TweetsGetter.byUser('ochyai')
cnt = 0
for tweet in getter.collect(total=1000000):
# cnt += 1
# print ('------ %d' % cnt)
# print ('{} {} {}'.format(tweet['id'], tweet['created_at'], '@'+tweet['user']['screen_name']))
# print (tweet['text'])
created_at.append(tweet['created_at'])
text.append(tweet['text'])
created_at = Series(created_at)
text = Series(text)
# 各シリーズをデータフレーム化
m1_df = pd.concat([created_at, text], axis=1)
# カラム名
m1_df.columns = ['created_at', 'text']
# csvファイルとして保存
m1_df.to_csv('ochiai180818E.csv', sep='\t', encoding='utf-16')
# 各シリーズをデータフレーム化
m2_df = pd.concat([created_at],axis=1)
# カラム名
m2_df.columns=['created_at']
# csvファイルとして保存
m2_df.to_csv('ochiai180818E1.csv', sep = ',',encoding='utf-8')
# CSV ファイル (employee.csv) として読み込む
df2 = pd.read_csv('ochiai180818E1.csv', sep=',', parse_dates=['created_at'], engine='python')
df3 = df2.set_index('created_at').resample('5T').count()
df3.columns = ['Index']
# csv ファイルとして出力
df3.to_csv('ochiai180818E2.csv', sep =',', encoding='utf-8')
# matplotlibを使ってグラフ化する
df3.plot()
# df3.plot(logy=True) # Y軸を対数表示するときは有効にする
plt.title("Twitter Trend")
plt.xlabel("Date")
plt.ylabel("The number of twitter")
pylab.savefig('ochiai180818E.png') # 保存するグラフのファイル名
3. データの取得結果と考察
では,前項のプログラムを実行結果していきます。
これは落合さんへのリプライのトレンド(縦軸は5分間のリプライ数)になります。
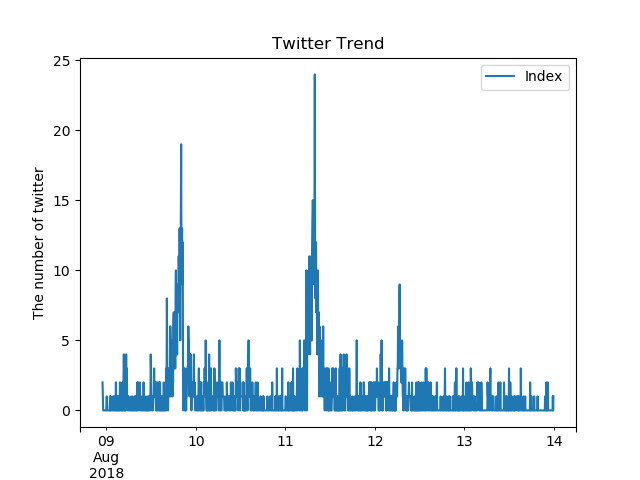
ここから、8月9日の午後、および8月11日の午前に落合さんへのリプライが増えているのがわかります。
本来は、リプライの中でも”クソリプ”とそうでないものを区別し、”クソリプ”のみの反応数をみて、落合さんからのアクションに対してどのように変化するのか(増えるのか、減るのか)注目したかったのですが、”クソリプ”の文章(キーワード)が共通していないため、よいキーワードが選べず抽出することができませんでした。
そこで、よい反応も含まれますが、リプライ数のみで評価し、その結果を考察します。
まず、8月9日のリプライ数の変化を細かく見ていきます。
これをみると、8月9日の16時(UT)、日本時間だと9時間プラスして8月10日の午前1時ごろにツイートがきっかけと思われます。
このきっかけとなったであろう落合さんのツイートは以下になります。
深夜でしたが、落合さんへのリプライに対して,落合さんが極端なまでに反応されているのがわかります。
落合さんのツイートおよび落合さんへのリプライの関係(相関)を確かめるため、同じグラフで並べてみます。
普段は、エクセルやカレイダグラフを使ってグラフ化しているのですが、ここでははじめてSuperMjographを使ってみました。個人使用である限り無料で使うことができ、直感的にグラフ化できるのでおすすめです。
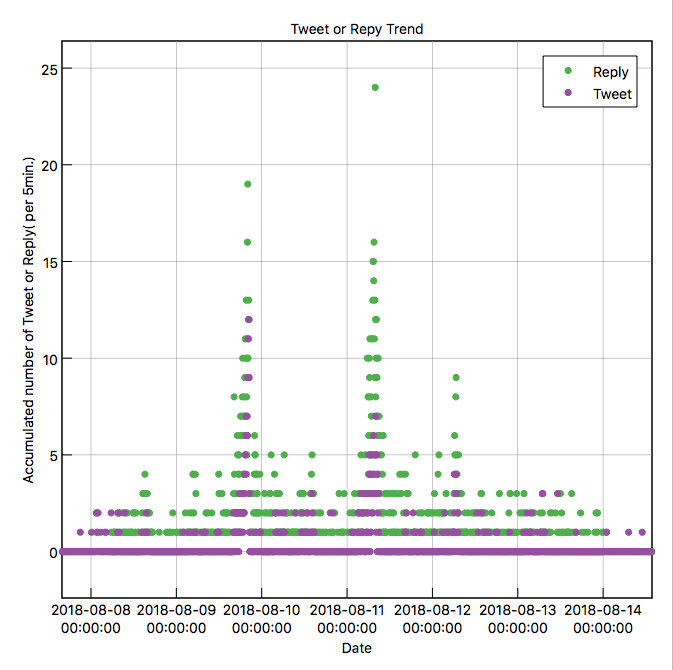
緑が落合さんへのリプライ数、紫が落合さんのツイート数になります。
まず、8月9日を注目してみます。
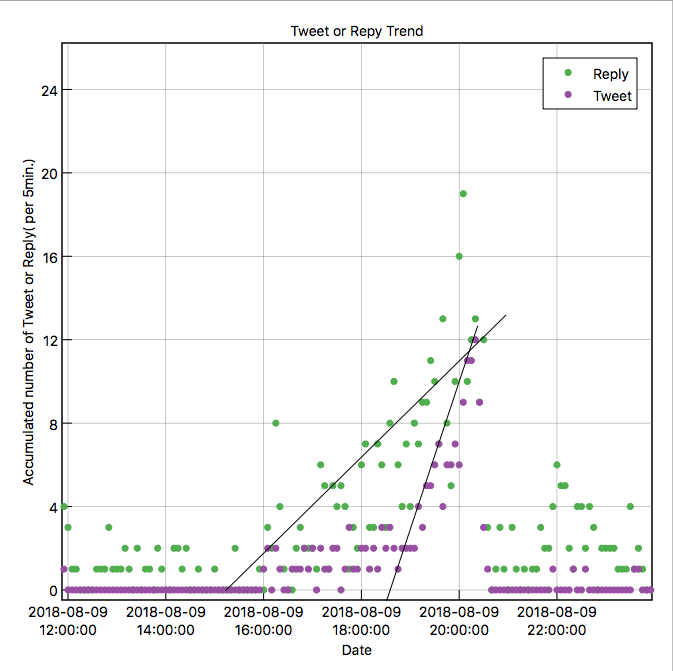
ここで面白いのは、落合さんへのリプライが増えると、それに対して落合さんが反応のツイートを行い、そのイタチごっこがつづいています。
1時間ほどこの状態が続き、リプライ数とツイート数がほぼ同数になった後(ここは”重要”)、両者とも同じタイミングでリプライ数およびツイート数が大きく減少しています。
この間のリプライおよびツイート内容をみてみると、当初はリプライは”クソリプ”に分類されるものが多かったのですが、後半になるとその分類のものは大きく減少しています。これは、落合さんによる反応速度がクソリプ反応に勝った結果、見事に撃退できていると推測します。(クソリプの持続時間はせいぜい1時間程度?)
次にリプライ数が増えているのが、8月11日の午前5時40分、日本時間だと9時間プラスして、同じ8月11日の午後2時40分ごろになります。
きっかけになったのと思われるのが、落合さんのこのツイートです。
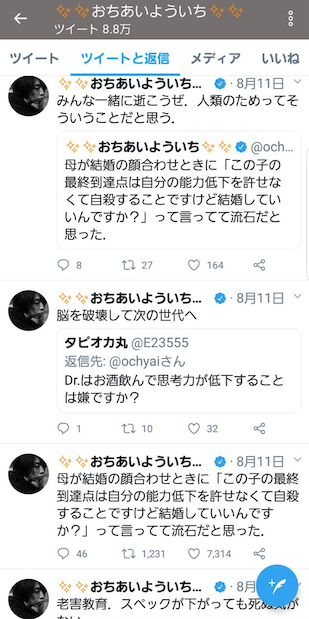
母が結婚の顔合わせのときに「この子の最終到達点は自分の能力低下を許せなくて自殺することですけど結婚していいんですか?」って言ってて流石だと思った. Tweet @ochyai
そして、それに対するリプライの一部がこちらです。
このときのリプライの内容をみると、”クソリプ”に分類する内容よりも、多くは”驚き”のリアクションになっています。
そのため、落合さんはそれらに対してい大きく反応することがなかったためか、リプライ数のトレンドは8月9日のものと大きく異なっています。
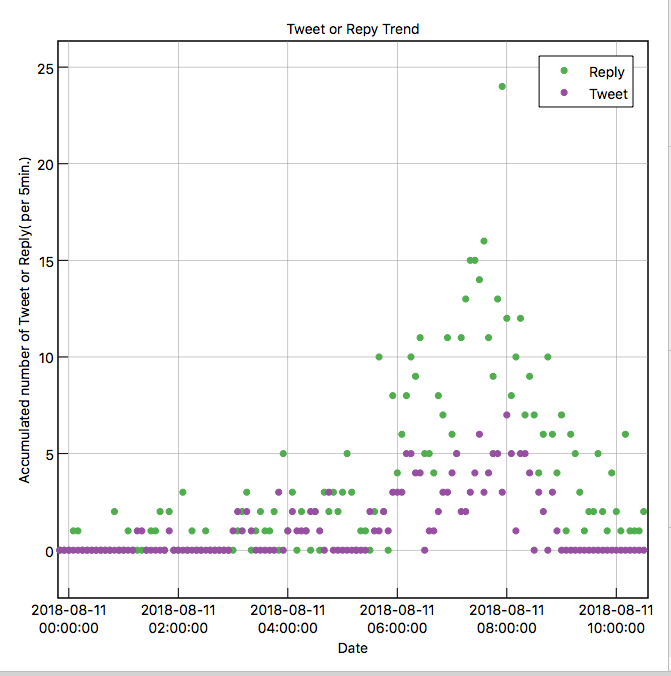
8月9日と比べて、リプライ数に対して落合さんのツイート数がそれほど大きくなっていません。またリプライ数も徐々に低下しています。
話題となって、その熱量が自然と下がっていった、と見られます。
こういったトレンドをみると、クソリプを撃退しているとき、ツイートが話題となっているときが、トレンドから推測できるのではないかと思いました。
ここで、そもそも世間一般に言われる”クソリプ”ってどれだけツイートされているのか、その傾向から考察できないかと思いました。
ただ、どういった言葉が”クソリプ”と分類されるツイートかはケースバイケースであるため、ここは”クソリプ”というキーワードでそのトレンドを調べてみました。
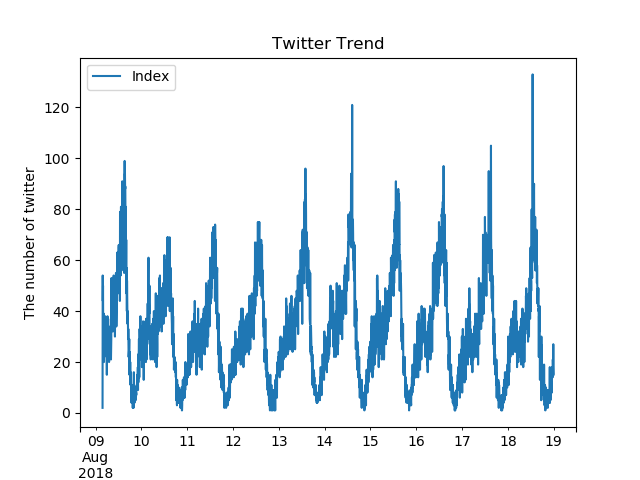
びっくりな結果です。”クソリプ”は毎日規則正しく行われています。営みです。
この傾向は人間の活動量がそのまま表されているのだと思います。
”クソリプ”することが目的であって、自分の主義・主張・反論・意見を述べる”手段”ではないのでしょう。
4. まとめ
長くなりましたが、以下に今回の検証結果をまとめます。
クソリプに意思はなく、その行為そのものが目的であるため、対象に意思を持って圧倒されれば消えていく。
今後は別のケースや対象でもツイートのトレンドから考察していきたいと思います。
注意
プログラムにより取得したデータそのものは客観的な結果ですが、そこからの推測は個人の考察です。