本の進捗状況を共有するWebサービス「この本読みやすい?」をリリースしました。
使ってみていただけると嬉しいです!
開発にあたって、「開設後3週間で収益10万円を得た個人開発サイトでやったことの全部を公開する」に大変刺激を受けました。
サービスの概要
このサービスでは、挫折してしまった人が多いのか、読了できた人が多いのかの傾向をグラフで見ることができます。また、どのページで挫折した人が多いのかを確認することができます。
読みやすい本を探したり、あえて難解な本を探して挑戦するといった使い方を想定しています。
以下のような傾向のグラフは、読了した人の割合が多く、読みやすい本であることを示しています。
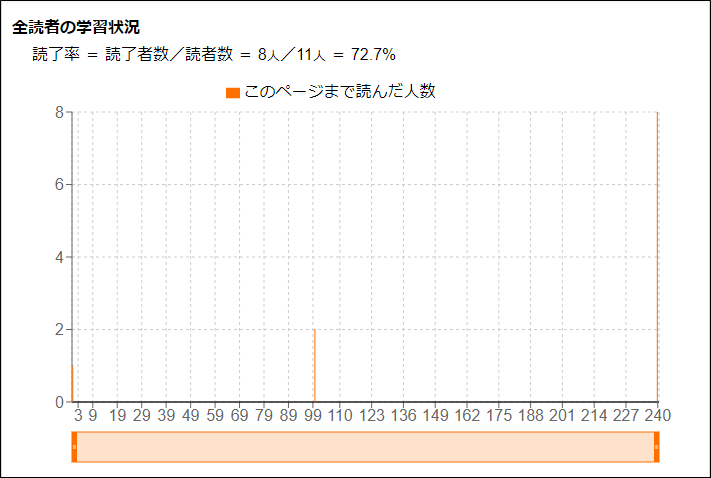
以下のような傾向のグラフは、序盤で挫折しやすい本であることを示しています。
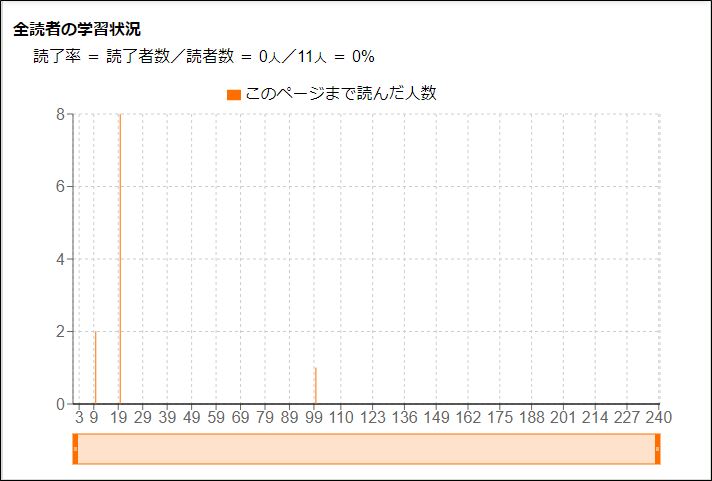
以下のような傾向のグラフは、中盤で挫折しやすい本であることを示しています。
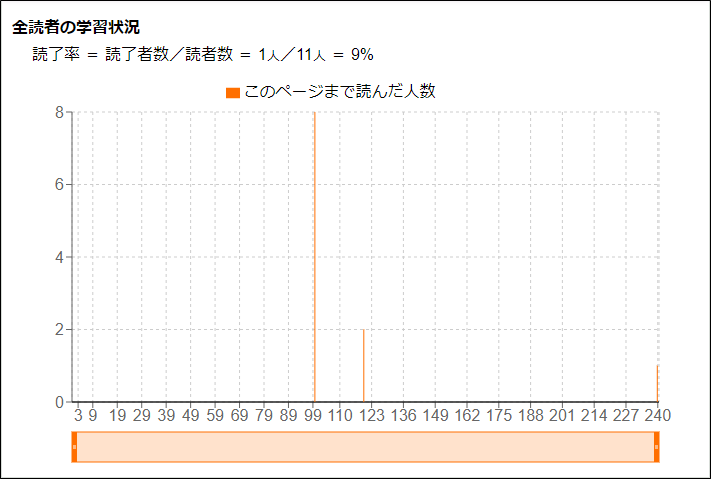
以下のような傾向のグラフは、中盤で挫折しやすいものの、そこを乗り越えると最後まで読める本であることを示しています。
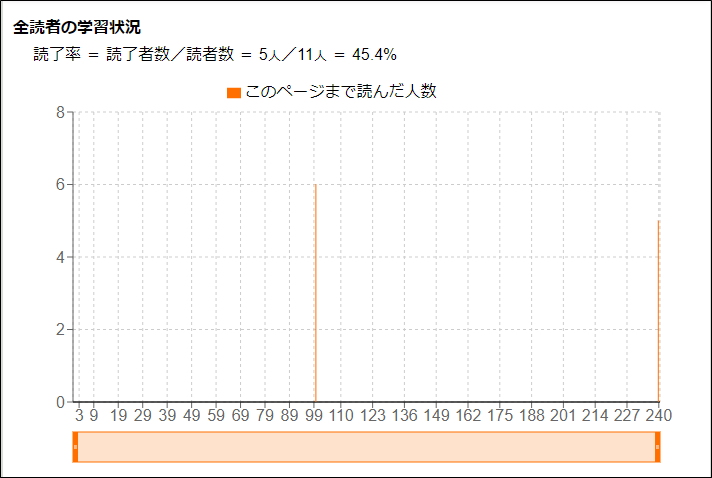
使い方
TOP画面です。
右上のボタンでユーザ登録&ログインができます。進捗を記録するにはログインが必要です。
本のリストは、更新順、読了率順、読者数順でソートすることができます。
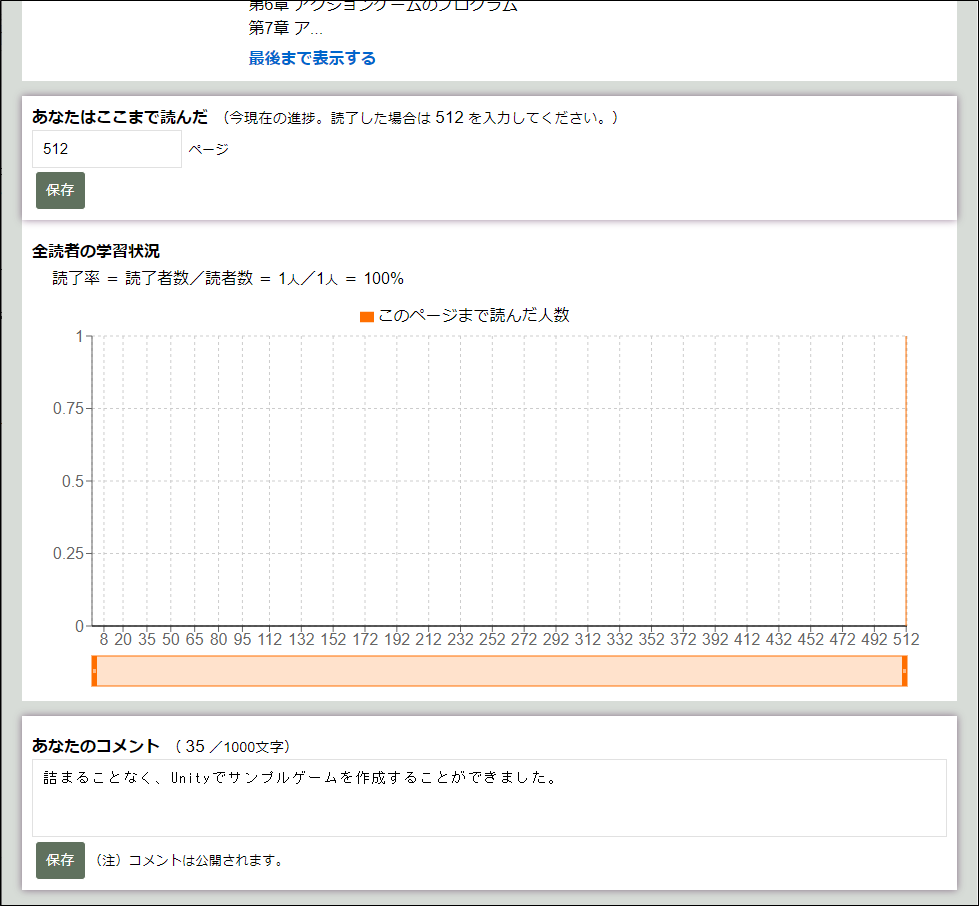
TOP画面などから本をクリックすると、以下のような本の詳細画面に遷移します。
ログインしていると、進捗やコメントを保存することができます。(見るだけならログイン不要です)
使用した技術
- Next.js
- Vercel
- Heroku
- Redis(★)
- Cloud Firestore(★)
- Firebase Authentication(★)
- Cloud Functions(★)
- Cloud Scheduler(★)
- Cloud Storage(★)
- CloudFlare(★)
★は、今回の開発で初めて取り組みました。
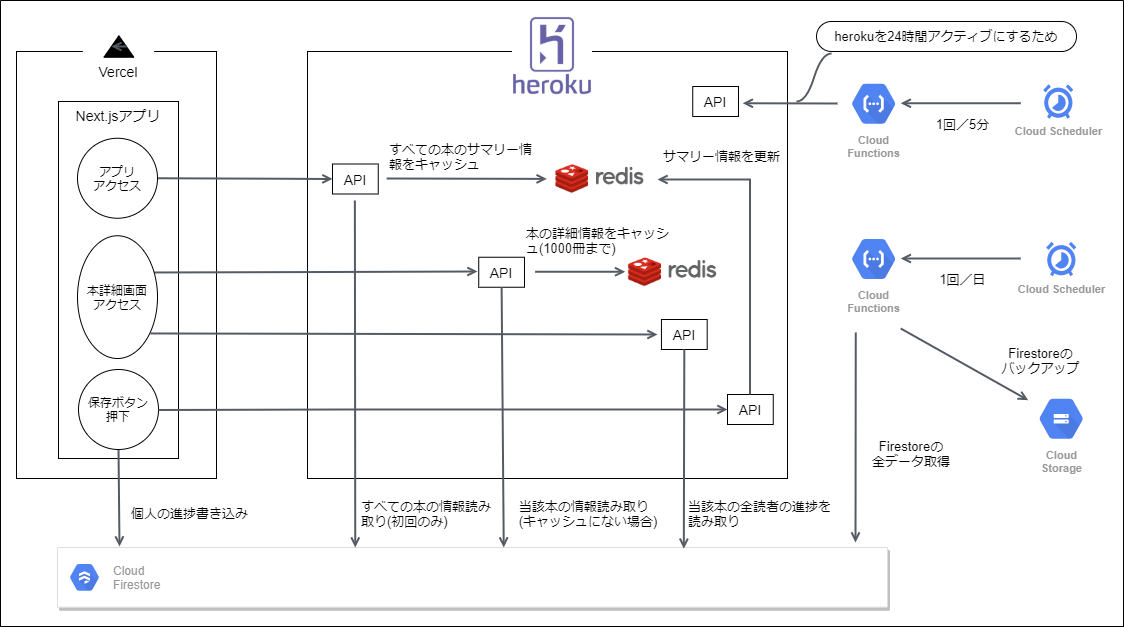
システム構成
初期データ
Qiitaの記事で紹介されている本を取得し(Amazonリンクを抽出しました)、目視で本サービスに該当しないものを除外して、初期データとして登録しました。
苦労した点
サービスにアクセスすると、まず、すべての本のサマリー情報(タイトル、更新時刻、読者数、読了率など)を入手します。1
直接Firestoreから読み取ってしまうと、すべての本を読み取るため、読み取り回数が本の数だけ増えてしまいます。(ドキュメント:本=1:1 でデータを管理しています)
そこで、API経由で取得するようにし、Firestoreから読み取るのは初回のAPI呼び出し時のみで、以降はキャッシュを返すことを考えました。
当初、APIはCloud Functionsで実現しようとしたのですが、以下が解決できなかったため、Heroku+Redisで実現することにしました。
問題点1
Cloud FunctionsでFirestoreから読み取ると、6秒以上かかる。![]()
const t1 = new Date();
db.collection('...').get().then(snapshot => {
const t2 = new Date();
console.log("経過時間(ミリ秒) t2-t1:", t2.getTime()-t1.getTime());
...
t2 - t1 で6秒以上かかってしまいます。
FirestoreとCloud Functionsのリージョンを同じにしてもダメでした。
ローカル実行した場合は1秒程度で取得できたため、Cloud Functions側に要因があるとは思うのですが、解決できませんでした。
問題点2
まあ、Firestoreの読み取りに時間がかかっても、キャッシュを利用すれば問題ないかと考えていました。が、うまくいきませんでした。
let summary_books = {};
exports.books = functions.region('asia-northeast1').https.onRequest((request, response) => {
上記のように、グローバル変数を用意すれば、次の呼び出し時に利用できます。
できたのですが...20分程度でリセットされてしまいました...。
Cloud Schedulerを使って5分間隔で上記APIを叩き続けてもダメでした。
ここで諦めてHeroku+Redisで実現することにしました。
・・・Heroku+Redisで実現したあとにこの記事「Cloud Functions for Firebaseのコールドスタート対策を実施した」を見つけました。試せてないですが、これで解決するのかもしれません。
最後に
本サービスを開発するにあたって、初めて扱った技術も多く、またドキュメントを読んでも難解で頭に入ってこず難儀しました。更にGCPについては下手のことをして莫大な課金が発生しないかびくびくしました...。
今回、とりあえず動かせるレベルまではいけたので、次のサービス開発はもう少し早く進められそうです。
-
本の検索は、端末側でこのサマリー情報を検索しています。Firestoreが部分一致検索に対応していないため、このような仕組みにしました。 ↩