はじめに
RAGとファインチューニングしたAIを用いて回答を自動でシートに入力する自動化アプリケーションをサーバレスアーキテクチャで実現しました。
質問が入力されたスプレッドシートを人が確認、回答を入力するというどこにでもあるようなプロセス。これの完全自動化に挑戦しました。
実際、自動化してみると完璧とまではいかないもののそこそこの精度が出せました。
体感、悲観的に見積もって80%ぐらいの正答率でしょうか。とは言え、ボタン1つでいきなりレビュー前段階ぐらいにできる!程度の感覚です。
それでは具体的な実装概要です!
概要
アーキテクチャ
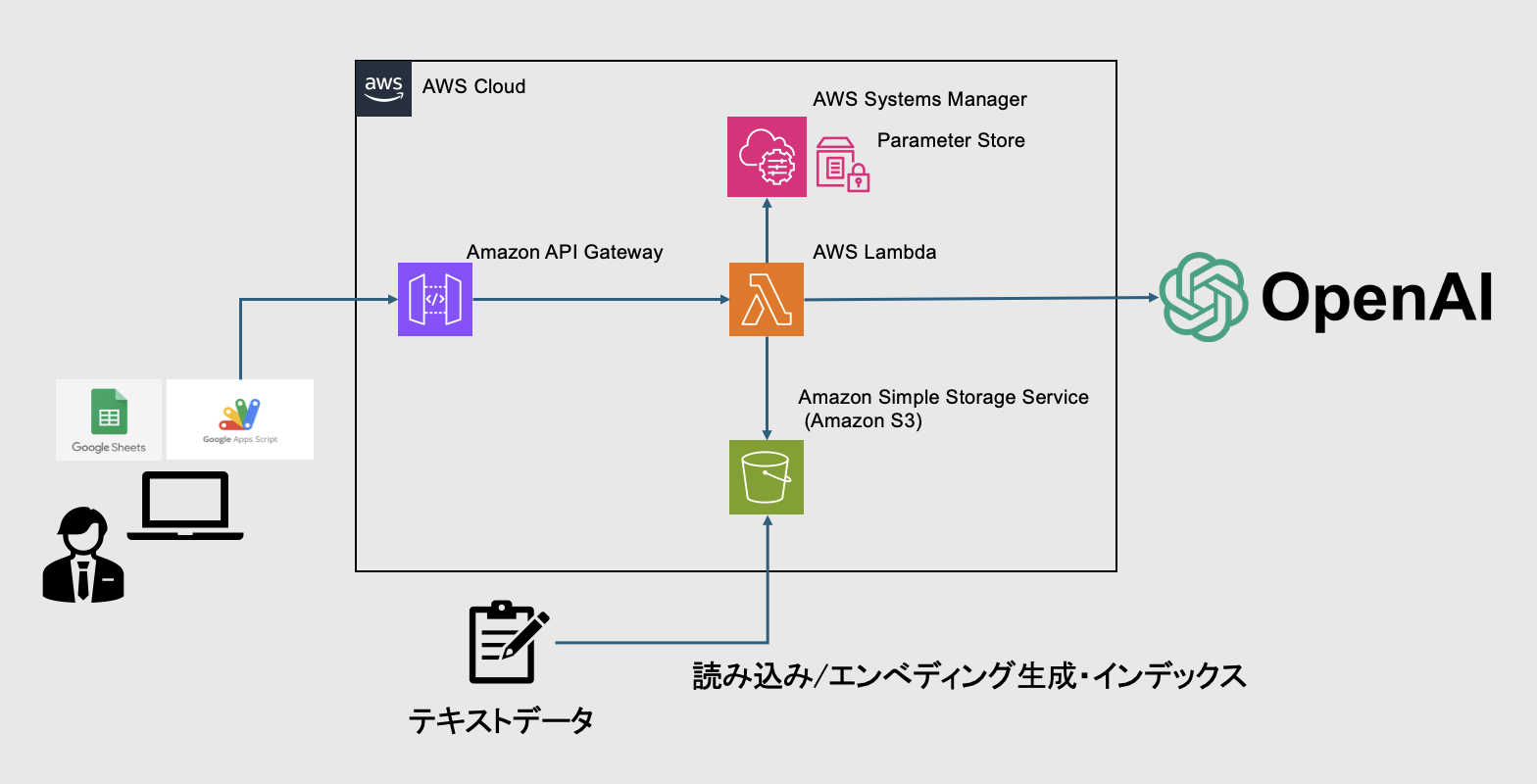
アーキテクチャは以上の通りです。
テキストデータのエンべディングに関してですが、色々と注意すべき項目があります。とは言いつつ、今回のテキストデータは「質問とそれに対応する回答」なので比較的綺麗な状態でした。1文章に多くのコンテキストを含んでいたり、1つの質問とそれに対する回答の組み合わせが長文になっていたりはしませんでした。
これが画像などの非構造化データを扱ったり、エンべディングするためのテキストデータが綺麗でなかったりする場合は話が変わってくるかもしれません。
ライブラリ・ツール
LlamaIndex
データ統合、インデックス作成が可能なライブラリで、データをベクトル化してくれます。
今回も回答生成の元になる情報をこのライブラリにてベクトル化し、インデックスとして生成AIに食わせています。
OpenAI
言わずと知れたchatGPTの生みの親。今回はLlamaIndexでベクトル化したデータを食べたchatGPTが判断を担っています。余談ですが、ファインチューニングだけでモデルをチューニングした結果は酷い有様でした...インターネットから拾ってこれない情報から回答させるにはインデックスないと厳しそうです。
GoogleAppScriipt
GASと略されることもあるGoogleスプレッドシート上でスクリプト実行が可能な拡張機能です。APIを叩くことも可能なので、今回はこいつでAPI Gatewayを叩いています。ローカルのAPIを直接叩くことはできませんが、個人的な実行であればngrock等で一時的にローカルのサーバを公開することでAWS等のインフラがなくても実行可能です。
AWS
インフラはAWSです。こちらももうお馴染みですね。
今回はAWS SAMを使用しています。コード流すだけで一撃インフラ構築は快感です。
技術選定
アプリケーションについて
アプリケーションについては、LlamaIndexを利用することから言語はPythonを使用しています。Pythonを使用することには、他にもいくつか利点があります。「インフラ乗せる前の簡易実行としてFastAPIが使える」、「Poetryを使用してPythonライブラリインストールを仮想環境で行い、ローカル環境の影響を受けずに実行ができる」などがその恩恵です。
インフラについて
今回はリクエスト頻度からサーバレスアーキテクチャでの実装としました。
無料利用枠を使用出来ますし、常時稼働するサーバを用意するよりコストが抑えられます。機械学習系のライブラリを使用するとソースコード膨らむし、果たしてLambdaで管理し切れるかは懸念点としてありました。これに関しては後述します。
実装手順
①ベクトルデータの準備
を参考にさせていただきました🙇
今回は.txt形式で質問に対する回答を用意し、jsonl形式に変換したものをS3にアップロードしました。
②アプリケーションの用意
app.pyの中でmyModelを使用して問い合わせを行なっています。
main_app.py
import os
import json
from mymodel import MyModel
import boto3
ssm_client = boto3.client('ssm')
def set_env_from_ssm():
try:
parameter_name = os.getenv("SSM_API_KEY_PARAM", "DEFAULT_PARAM_NAME")
response = ssm_client.get_parameter(
Name=parameter_name,
WithDecryption=True
)
os.environ["API_KEY"] = response["Parameter"]["Value"]
except Exception:
raise Exception("Failed to fetch API key from SSM.")
def lambda_handler(event, context):
try:
body = json.loads(event["body"])
query = body.get("qry", "")
except (KeyError, json.JSONDecodeError):
return {"statusCode": 400, "body": json.dumps({"error": "Invalid request body"})}
model = MyModel(query)
answer = model.ask().response
return {"statusCode": 200, "body": json.dumps({"response": answer})}
class MyModel:
def __init__(self, qry):
self.qry = qry
self.s3_bucket_name = "<S3_BUCKET_NAME>"
self.local_storage_dir = "/tmp/storage"
def download_storage_from_s3(self):
s3_client = boto3.client("s3")
storage_files = [
"docstore.json",
"graph_store.json",
"index_store.json",
"vector_store.json"
]
if not os.path.exists(self.local_storage_dir):
os.makedirs(self.local_storage_dir)
for file in storage_files:
try:
local_file_path = os.path.join(self.local_storage_dir, file)
s3_client.download_file(self.s3_bucket_name, file, local_file_path)
except Exception as e:
raise RuntimeError(f"Failed to download {file} from S3: {e}")
def ask(self):
import time
from storage_context import StorageContext # ストレージ関連のモジュール(仮名)
from query_engine import load_index_from_storage # クエリエンジン関連のモジュール(仮名)
from prompt_templates import ChatMessage, ChatPromptTemplate # プロンプトテンプレート関連(仮名)
start_time = time.time()
try:
# ストレージからデータをダウンロード
self.download_storage_from_s3()
# ストレージコンテキストの初期化
storage_context = StorageContext.from_defaults(persist_dir=self.local_storage_dir)
index = load_index_from_storage(storage_context)
# プロンプトの設定
TEXT_QA_SYSTEM_PROMPT = ChatMessage(
content=(
"あなたは世界中で信頼されているQAシステムです。\n"
"事前知識ではなく、常に提供されたコンテキスト情報を使用してクエリに回答してください。\n"
"従うべきいくつかのルール:\n"
"<INSTRUCTIONS>" # ファインチューニングの指示
),
role="SYSTEM", # システムメッセージ
)
TEXT_QA_PROMPT_TMPL_MSGS = [
TEXT_QA_SYSTEM_PROMPT,
ChatMessage(
content=(
"コンテキスト情報は以下のとおりです。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"事前知識ではなくコンテキスト情報を考慮して、クエリに答えます。\n"
"Query: {query_str}\n"
"Answer: "
),
role="USER",
),
]
CHAT_TEXT_QA_PROMPT = ChatPromptTemplate(message_templates=TEXT_QA_PROMPT_TMPL_MSGS)
CHAT_REFINE_PROMPT_TMPL_MSGS = [
ChatMessage(
content=(
"あなたは、既存の回答を改良する際に2つのモードで厳密に動作するQAシステムのエキスパートです。\n"
"<REFINEMENT_DETAILS>" # 回答調整内容
),
role="USER",
)
]
CHAT_REFINE_PROMPT = ChatPromptTemplate(message_templates=CHAT_REFINE_PROMPT_TMPL_MSGS)
# クエリエンジンの初期化とクエリ実行
query_engine = index.as_query_engine(
similarity_top_k=5,
text_qa_template=CHAT_TEXT_QA_PROMPT,
refine_template=CHAT_REFINE_PROMPT,
)
response = query_engine.query(self.qry)
end_time = time.time()
return response
except Exception as e:
return {"error": f"An unexpected error occurred while processing the query: {e}"}
③AWS SAMの準備とデプロイ
テンプレートは下記の通りです。使用量の制限などはお好みのパラメータに調整いただければと思います。
APIKeyの設定等は任意ですが、デプロイした環境をしばらく放置するなら用意しておいた方が良いと思います。
アプリケーションのソースコード含めたフォルダ構成は以下のとおりです
project_name/
|-hello_world/
|-core_logic/
- main_app.py # メインのアプリケーションロジック
- mymodel.py/ # コア機能を提供するモジュール
- dependencies.txt # 必要なライブラリを記載したファイル
|-.aws-sam/
|-events/
|-tests/
|-template.yaml
|-samconfig.toml
requirements.txt(バージョンは依存関係が解決できる任意のものを選んでください)
openai
requests
llama-index
langchain
python-dotenv
template.yaml
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: >
serverless_project
Globals:
Function:
Timeout: 3
LoggingConfig:
LogFormat: JSON
Resources:
MyApi:
Type: AWS::Serverless::Api
Properties:
Name: ServerlessApi
StageName: Prod
EndpointConfiguration: REGIONAL
Auth:
ApiKeyRequired: true
# HelloWorldFunction (疎通確認用)
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello_world/
Handler: app.lambda_handler
Runtime: python3.11
Architectures:
- x86_64
Events:
HelloWorld:
Type: Api
Properties:
RestApiId: !Ref MyApi
Path: /hello
Method: get
# MainFunction
MainFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: core_logic/
Handler: app.lambda_handler
Runtime: python3.11
Architectures:
- arm64
Timeout: 30
MemorySize: 1536
Events:
MainEvent:
Type: Api
Properties:
RestApiId: !Ref MyApi
Path: /main
Method: post
Policies:
- Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:ListBucket
Resource:
- "arn:aws:s3:::project_bucket"
- "arn:aws:s3:::project_bucket/*"
- Effect: Allow
Action:
- ssm:GetParameter
- ssm:GetParameters
- ssm:DescribeParameters
Resource:
- "arn:aws:ssm:region:account-id:parameter/api_key_name"
ApiKey:
Type: AWS::ApiGateway::ApiKey
Properties:
Name: ApiKey
Enabled: true
UsagePlan:
Type: AWS::ApiGateway::UsagePlan
Properties:
UsagePlanName: UsagePlan
ApiStages:
- ApiId: !Ref MyApi
Stage: Prod
Throttle:
RateLimit: 30
BurstLimit: 30
Quota:
Limit: 1500
Period: MONTH
UsagePlanKey:
Type: AWS::ApiGateway::UsagePlanKey
Properties:
KeyId: !Ref ApiKey
KeyType: API_KEY
UsagePlanId: !Ref UsagePlan
Outputs:
HelloWorldApi:
Description: Hello World API Endpoint
Value: !Sub "https://${MyApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello"
MainFunctionApi:
Description: Main Function API Endpoint
Value: !Sub "https://${MyApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/main"
requirements.txtからインポートするとメインモジュールのフォルダ内には結構なライブラリが入ってきます。Lambdaレイヤーに必要なライブラリを移そうと試みたものの、250MBの制約によりできず...もし出来たよという方がいたら教えてください🙇それぞれのライブラリごとにレイヤーに分けることも試みたんですけどねー....自分が下手くそなだけかもしれない。
ここまで定義できたら
$ sam build
$ sam validate
でbuildを試行、template.ymlをvalidateコマンドで確認すれば、事前にミスを修正できます。
良さそうだったら
$ sam deploy --guided
これでS3内にCloudFormationテンプレートがアップロードされてデプロイ完了です。
④Google App Scriptの用意
GASの仕様上、ボタンによる非有効化ができないため、ポップアップを出してユーザーに待機を促すようにしています。
質問、回答などヘッダーが1行目にあるので2行目から認識して回答を入力してもらうようにしています。SpreadsheetApp.flush();は任意です。質問が多い場合に動いているか動いていないか分からなくなりそうという懸念から入れています。GoogleAppScriptは実行すると下記画像のポップアップから"キャンセル"を押すといつでもスクリプトが中断できてしまう仕様のため、動いていることが可視化できるようにしておいた方が良いと思います。

メインの関数は下記です。
function askModel() {
// ポップアップを表示
const html = HtmlService.createHtmlOutputFromFile("Loading")
.setWidth(300)
.setHeight(200);
const ui = SpreadsheetApp.getUi();
ui.showModalDialog(html, "処理中");
try {
const spreadsheet = SpreadsheetApp.getActiveSpreadsheet();
const sheet = spreadsheet.getActiveSheet();
const apiUrl = "https://api.example.com/endpoint"; // API URL
const apiKey = "YOUR_API_KEY_HERE"; // APIキー
const data = sheet.getDataRange().getValues();
let startRow = data.length + 1;
for (let i = 1; i < data.length; i++) {
if (data[i][0]) {
startRow = i + 2;
break;
}
}
for (let i = startRow - 1; i < data.length; i++) {
const query = data[i][0];
if (query) {
const options = {
method: "post",
contentType: "application/json",
headers: {
"x-api-key": apiKey,
},
payload: JSON.stringify({ qry: query }),
};
try {
const response = UrlFetchApp.fetch(apiUrl, options);
const jsonResponse = JSON.parse(response.getContentText());
const answer = jsonResponse.competition || "No response";
// レスポンスを2列目に書き込み
sheet.getRange(i + 1, 2).setValue(answer);
// 更新を即時反映
SpreadsheetApp.flush();
} catch (error) {
sheet.getRange(i + 1, 3).setValue(`Error: ${error.message}`);
SpreadsheetApp.flush();
Utilities.sleep(100);
}
}
}
} catch (error) {
SpreadsheetApp.getUi().alert(`エラーが発生しました: ${error.message}`);
} finally {
// Loadingモーダルを消す
const htmlClose = HtmlService.createHtmlOutput('<script>google.script.host.close();</script>');
SpreadsheetApp.getUi().showModalDialog(htmlClose, "閉じる");
SpreadsheetApp.getUi().alert("処理が完了しました!");
}
}
上記の中でポップアップとして表示しているHTMLファイルは下記です。
<!DOCTYPE html>
<html>
<head>
<style>
body {
font-family: Arial, sans-serif;
text-align: center;
padding: 20px;
}
.spinner {
margin: 20px auto;
width: 40px;
height: 40px;
border: 4px solid rgba(0, 0, 0, 0.1);
border-left-color: #000;
border-radius: 50%;
animation: spin 1s linear infinite;
}
@keyframes spin {
to {
transform: rotate(360deg);
}
}
</style>
</head>
<body>
<div class="spinner"></div>
<p>処理中です。<br>しばらくお待ちください...</p>
</body>
</html>
あとはGoogleスプレッドシートでアイコンを用意し、そのボタンを押したらスクリプトが実行されるようにします。スプレッドシート内にアイコン置くのは下記を見ていただけると良いと思います。
あとはボタンを押して実行するだけ!
おわりに
振り返り
反省点としては、Lambdaレイヤーにライブラリを入れられずLamndaで起動するコンテナがライブラリでもりもりになってしまっています(本当に重たい)。Lambdaはコールドスタート状態で起動する場合、10秒以内に立ち上がり切らないとリクエストが失敗するという制約があります。今回はもりもりコンテナ立ち上げに1200MBのメモリはマストでした(安全係数をかけてデプロイは1500MBにしている)。一旦デプロイして使用できることがマストだったので今後対応してみたいと思います。
逆に良かった点としては、データクレンジングを繊細に実行しなかったのにも関わらず比較的正答率が高かったことです。ただどうしても聞き方によって回答がブレてしまうことがあったため、同じ回答でも複数の聞き方を用意しておくと類似する言い回しに対応できるかもしれません。
展望
学習データの更新を自動化したいです。今回、S3内に参照するデータをおいておけるのが非常に良かったです。ローカルで動かせる環境を用意して、mainマージ時にGitHubActionsでベクトル化したjonlだけ自動でS3にアップロードするような仕組みづくりをすることでデータを自動で最新版に更新できるな〜とか作りながら考えていました。また過去データはバックアップ用のバケットにコピーしておくとかもできますね。
そして何よりレイヤーを使ってコンテナの中身を軽くしたい。Lambdaの課金形態的に実行時間は短ければ短いほど、メモリ数は小さければ小さいほど良いです。
また、欲を言えば非構造化データにも挑戦してみたいですね。Gitのリポジトリを覗いてパスとかを識別して適切な画像と一緒にアプリケーションの仕様について答えてくれる仕組みづくりをしたい。カスタマーサクセスの方や頻繁にアップグレードされるソフトウェアを売る営業の方の仕様把握の負担が減るような仕組みを作れたら良いなと思ってます。