こんにちは!ギです。
最近、プロジェクトでAthenaというサービスを触り始めました。超便利なサービスだと思いますので、今回はAthenaの使い方をご紹介いたします。
Amazon Athenaとは?
Amazon Athena は、標準 SQL を使用して Amazon S3 内のデータを直接分析することができるインタラクティブなクエリサービスです。
Athena は簡単に使えます。Amazon S3 にあるデータを指定して、スキーマを定義し、標準的な SQL
を使ってデータのクエリを開始するだけです。
詳細情報は公式サイトに書いてあります。
サービスの料金
サービスの料金は実行したクエリに対してのみ料金が発生します。クエリごとに、スキャンされたデータ1TBあたり5USDですが、データの圧縮、分割、列形式への変換を行うことにより、クエリに対するコストを 30%~90% 削減できます。データベースに関する操作(データベースの作成やテーブルの作成、アップデート、削除など)、または、実行が成功しなかったクエリに対しては課金されません。
コスト削減に関するヒント
- S3とAthenaは同じリージョンに置く:データ転送料金が削減できる。現在、Tokyoリージョンもサポートされている
- パーティション切れる構成を設定する:スキャンするデータ量が減るため
- 圧縮データ(gzip)を使う
Athenaの設定する方法
Amazonサービス一覧画面に、AthenaサービスURLが書いてあり、そのページにアクセスしてください。
メインスクリーンの右隅に「Tutorial」の項目があります。そのチュートリアルには、サービスの使い方が書いてあるので、初心者は是非閲覧してみてください。
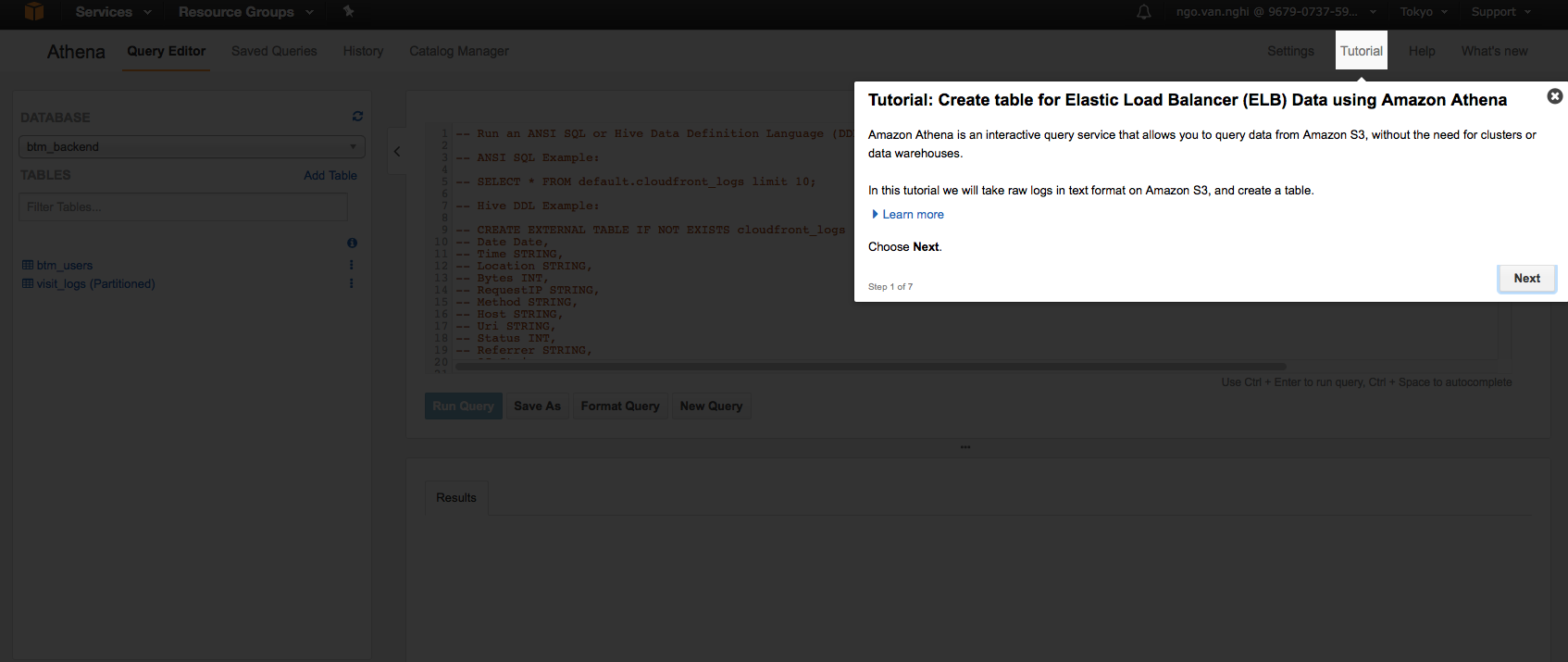
これから、 データベースの作成やテーブル作成をやってみましょう。
メインスクリーンの左メニューに「Catalog Manager」項目があり、そのURLをアクセスすると、データベース管理画面に推移します。
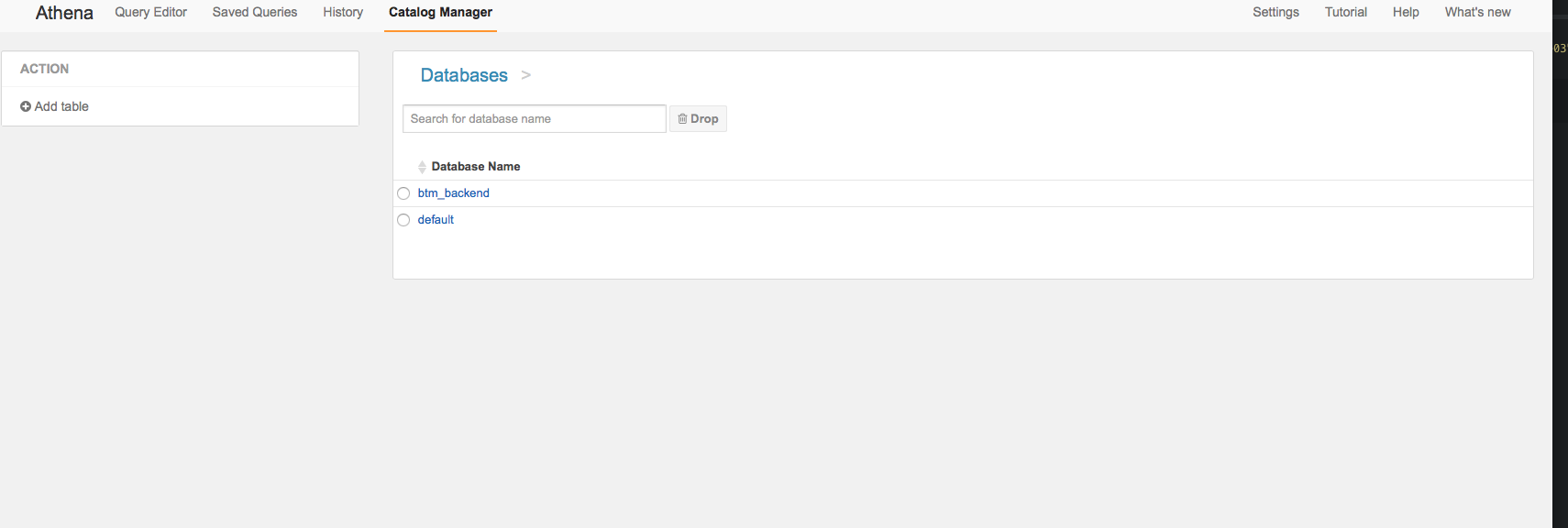
左にある「Add table」ボタンをクリックすると、データベース作成画面が表示されます。
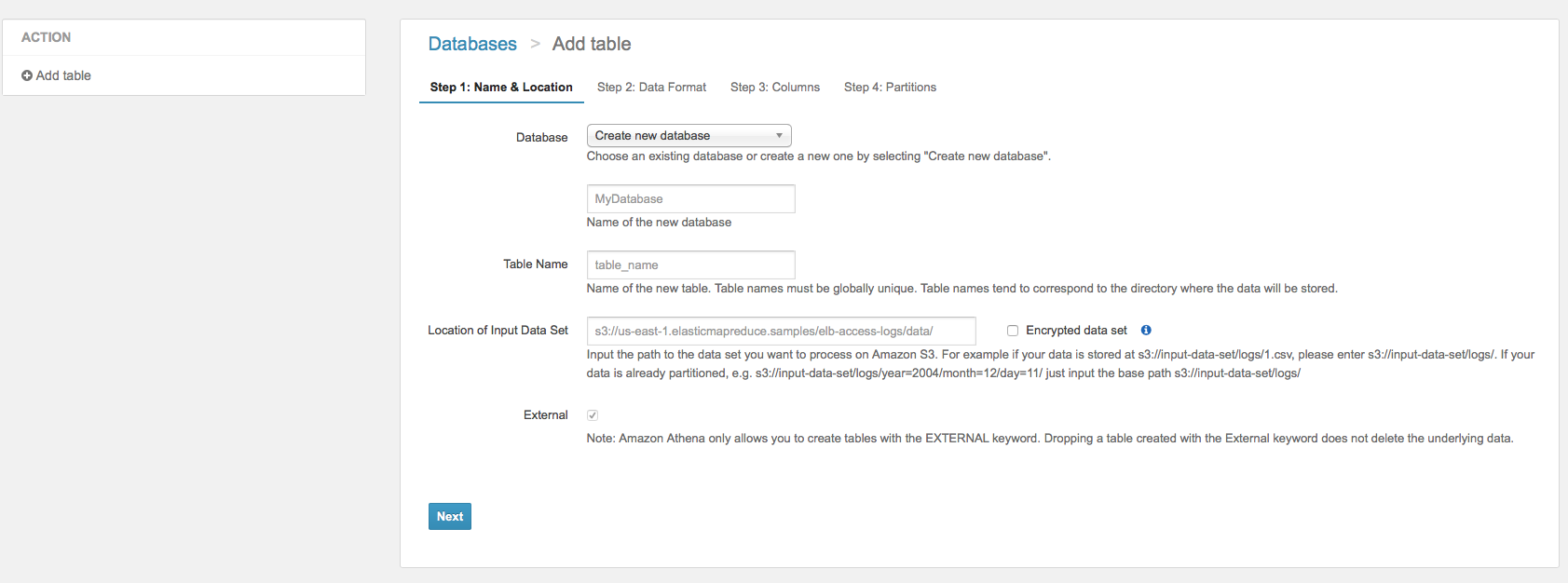
基本的に、データベースの作成は4つの段階があります。それぞれのステップをやってみます。
ステップ1: データベースやテーブルを設定する
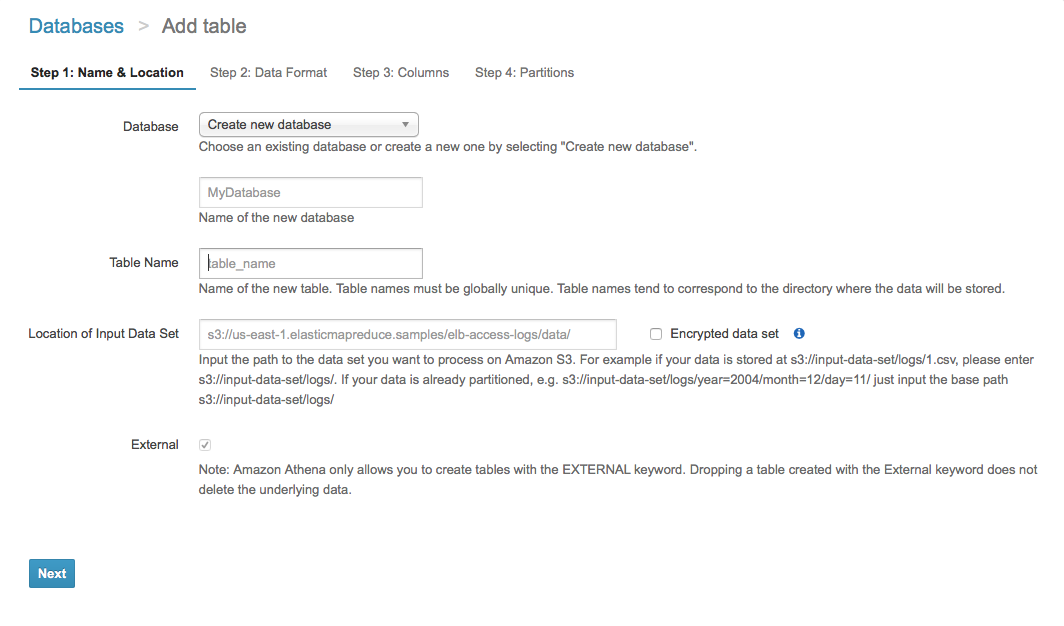
既存のデータベースを選択したり、新データベースを追加したりすることができます。
クエリのInputはS3に保存されるので、InputファイルのS3のpathを指定ください。
ステップ2: Inputファイルのフォーマットを設定する
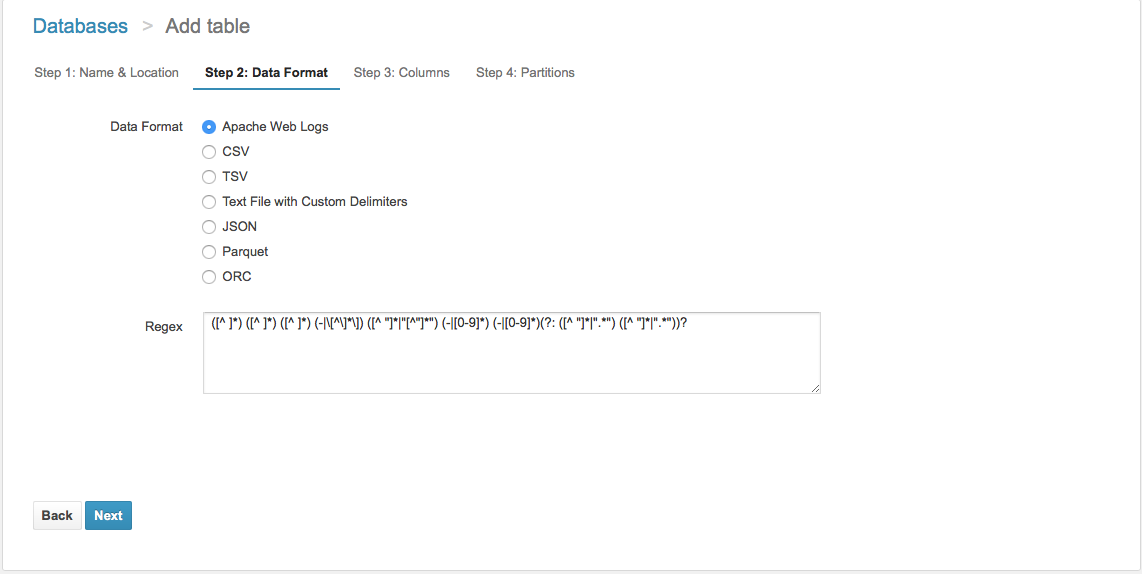
AthenaはいろんなInputフォーマットをサポートしています。このステップで、インプットファイルのフォーマットに合わせて設定ください。
ステップ3: テーブルのカラムを設定する
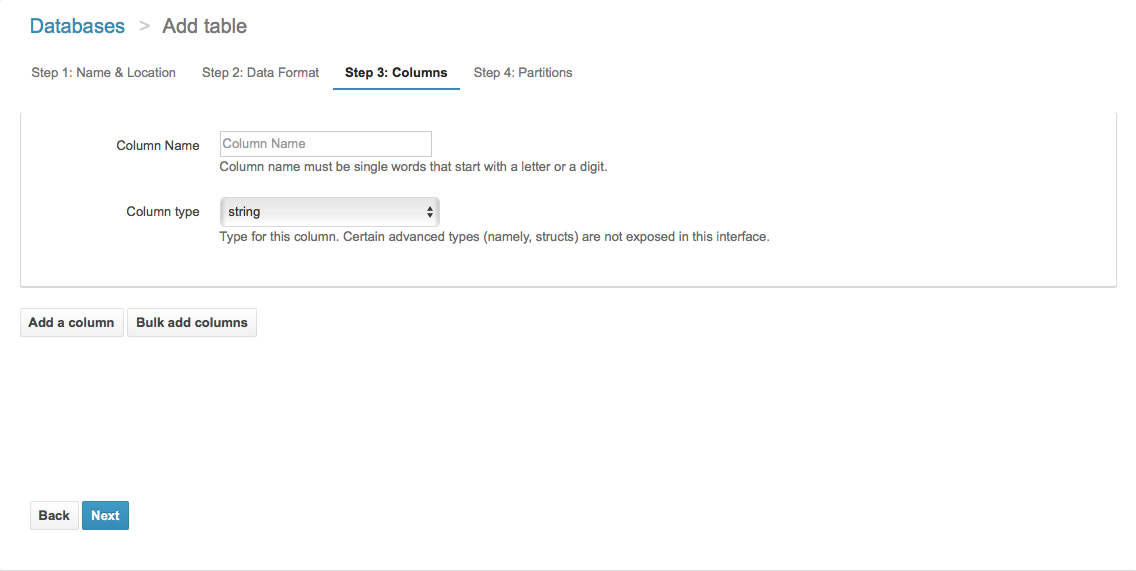
カラム毎に追加でき、さらに一括で複数カラムを追加することもできます。
ステップ4: パーティションを設定する
Athenaでパーティションを指定することで、各クエリで特定の領域に対するスキャンを実行できるようになります。例えば、S3上のデータがs3://log/date=YYYY-MM-dd/log.csvのような形でS3へ保存されるとします。パーティションを指定することで、検索時に特定の日付配下のデータだけをスキャンすることができるので、パフォーマンスが向上します。また、スキャンするデータ量も減るため、コストも削減できます。
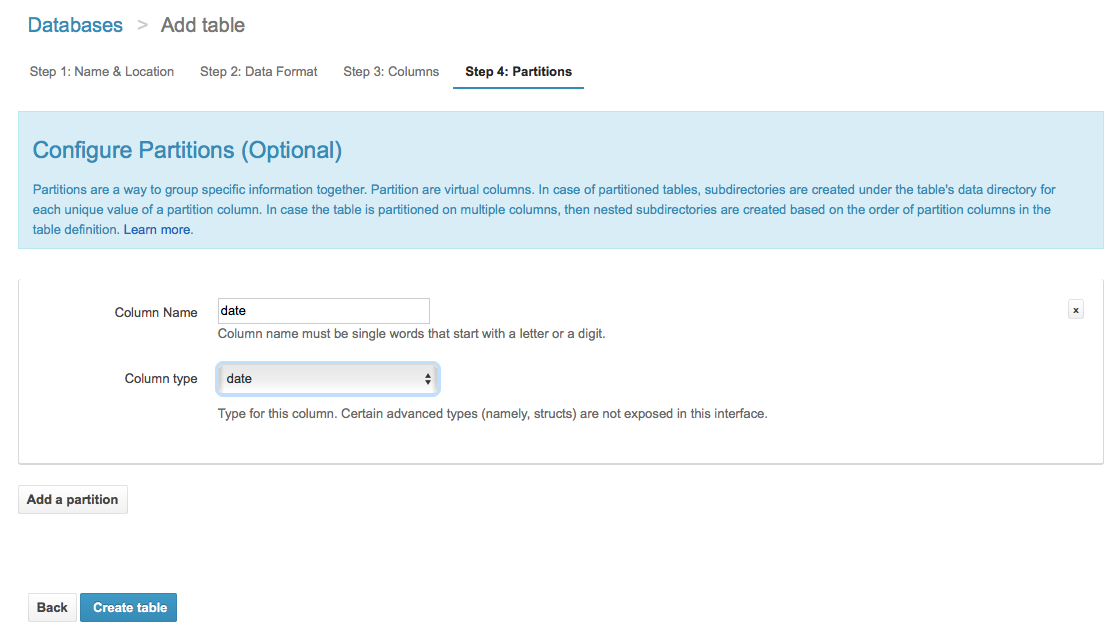
ログフォルダ名はdate=YYYY-MM-ddなので、パーティションカラム名は「date」になり、パーティションカラムタイプはdateになります。
ここまで、新しいテーブルを作ってきました。次はデータをクエリしてみましょう。
データをクエリしてみる
ウェブ画面でやってみる
まず、「Query Editor」画面をアクセスします。この画面で、右側のクエリエディタボックスでSQLクエリを入力して、実行すると、下部に結果が表示されます。
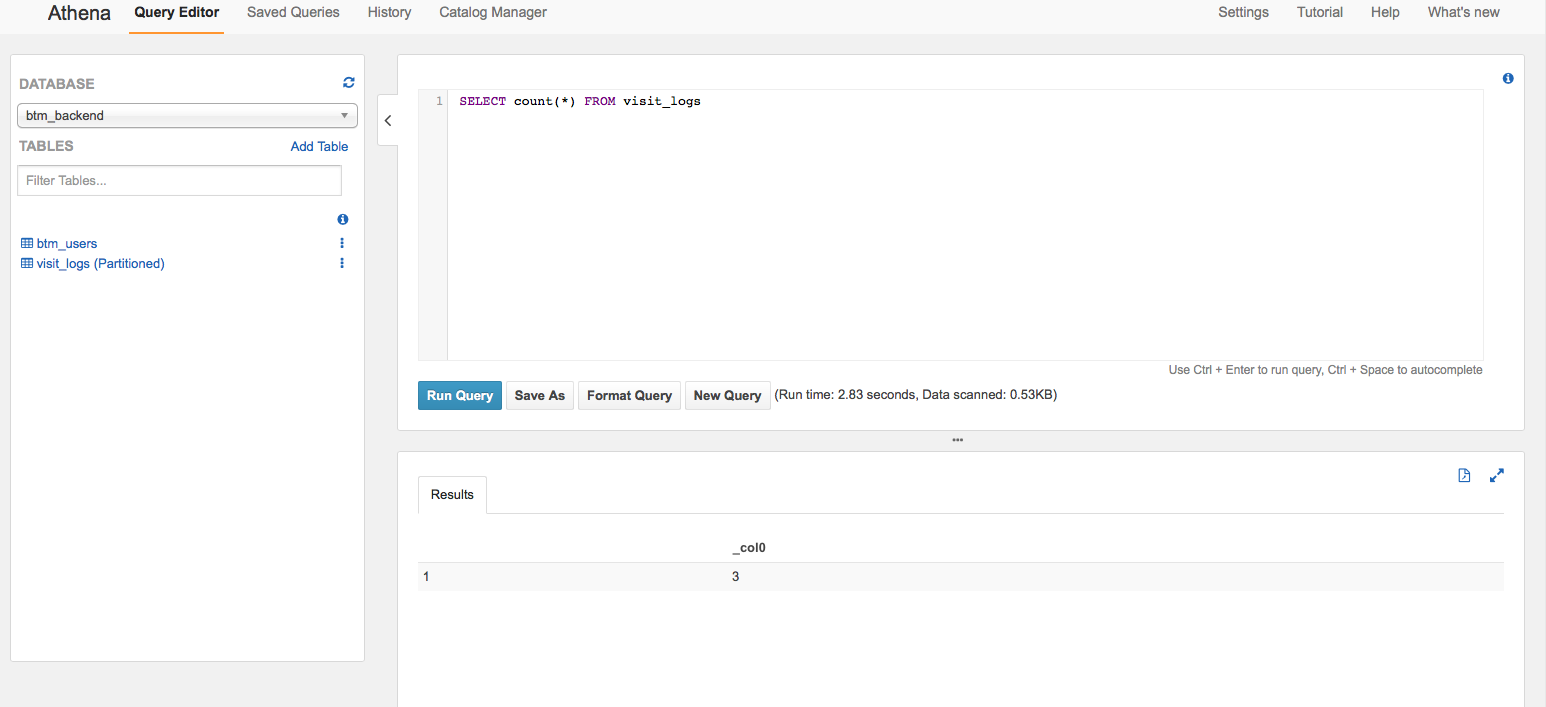
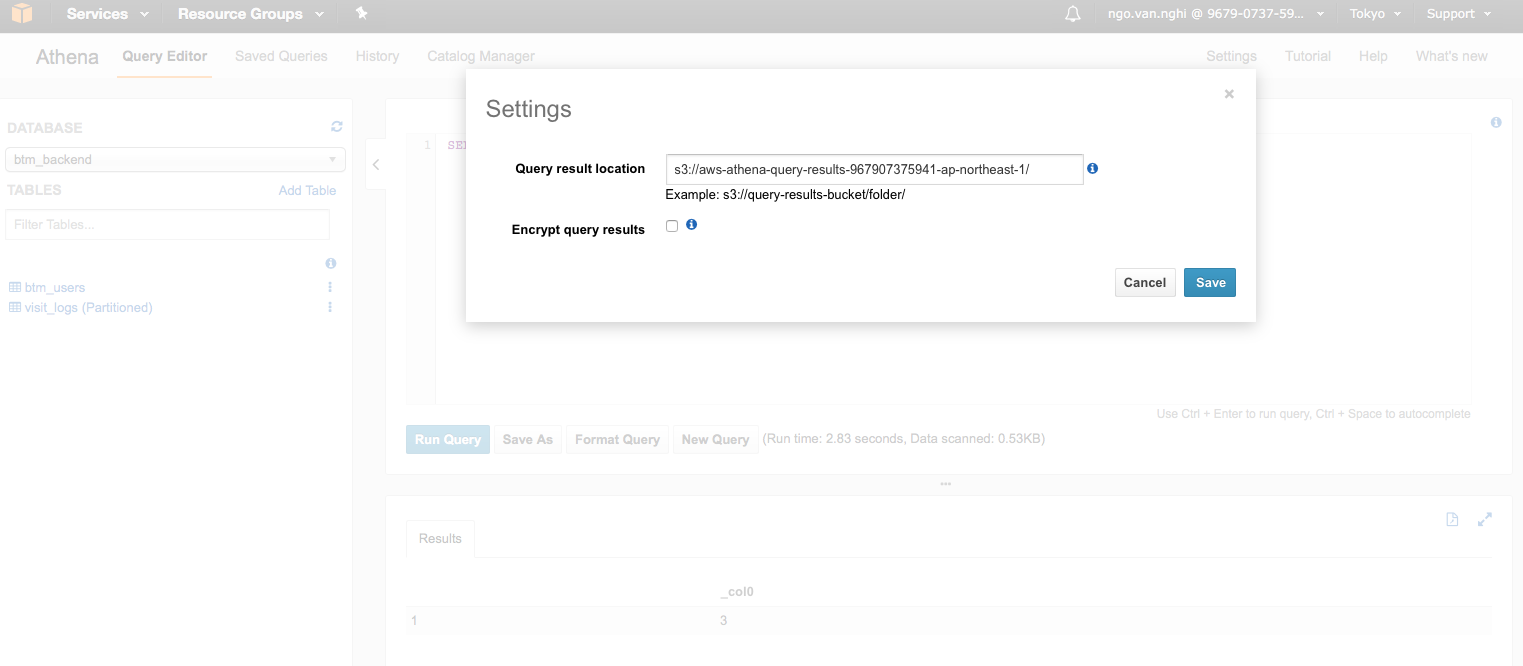
クエリの結果もS3に保存してくれます。クエリの結果Pathも自由に指定できます。
GOでサンプルプログラムをやってみる
GOの練習も兼ねて、今回、AthenaのGO SDKを使って、データをクエリしてみます。
SDKのドキュメント: http://docs.aws.amazon.com/sdk-for-go/api/
SDKをインストールするため、プロジェクトで以下のコマンドを実行してください。
go get -u github.com/aws/aws-sdk-go
まずは、Athena Client を作成します
// Amazon API guide: http://docs.aws.amazon.com/sdk-for-go/api/
type Athena struct {
C *athena.Athena
}
// Create New Athena Client with accessKey , secretAccessKey, region info
func NewAthenaClient(k string, sk string, r string) (*Athena, error) {
creds := credentials.NewStaticCredentials(k, sk, "")
_, err := creds.Get()
if err != nil {
return nil, fmt.Errorf("Init S3 Client Error: %s", err)
}
cfg := aws.NewConfig().WithRegion(r).WithCredentials(creds)
sess := session.Must(session.NewSession(cfg))
return &Athena{
C: athena.New(sess),
}, nil
}
次に、クエリをAthenaサービスに送ります。
// Submit Query Request
// db: target db to query
// query: standard sql
// o : output location. s3 output path
func (a *Athena) SubmitAthenaQuery(db *string, query *string, o *string) (*string,error) {
// Set Database to query
queryExecutionContext := &athena.QueryExecutionContext{Database: db}
// Set results of the query
resultConfiguration := &athena.ResultConfiguration{OutputLocation: o}
// Create the StartQueryExecutionRequest to send to Athena which will start the query.
startQueryExecutionInput := &athena.StartQueryExecutionInput{
QueryExecutionContext: queryExecutionContext,
ResultConfiguration: resultConfiguration,
QueryString: query,
}
startQueryExecutionOutput,err := a.C.StartQueryExecution(startQueryExecutionInput)
if err != nil {
return nil, fmt.Errorf("Submit Query To Athena Error: %v", err)
}
return startQueryExecutionOutput.QueryExecutionId, nil
}
送信が成功だったら、クエリの実行IDをもらいます。これから、クエリの実行IDを使って、結果を取得します。
クエリが実行できたか確認するため、関数を作ります。
// Wait for an Athena query to complete, fail or is canceled.
// If a query fails or is canceled, then Error
// Query finish will return nil
func (a *Athena) WaitForQueryToComplete(queryExecutionId *string) error {
getQueryExecutionInput := &athena.GetQueryExecutionInput{
QueryExecutionId: queryExecutionId,
}
isQueryStillRunning := true
for isQueryStillRunning {
getQueryExecutionOutput,err := a.C.GetQueryExecution(getQueryExecutionInput)
if err != nil {
return fmt.Errorf("Athena Query was cancelled. queryExecutionId = " + *queryExecutionId)
}
queryState := getQueryExecutionOutput.QueryExecution.Status.State
switch *queryState {
case "SUCCEEDED" :
isQueryStillRunning = false
case "CANCELLED":
return fmt.Errorf("Athena Query was cancelled. queryExecutionId = " + *queryExecutionId)
case "FAILED":
return fmt.Errorf("Athena Query Failed to run with Error Message: " + *getQueryExecutionOutput.QueryExecution.Status.StateChangeReason)
}
}
return nil
}
最後に、ページングで結果を取って、処理します。
func (a *Athena) ProcessResultRows(queryExecutionId *string, fn ProcessRow) error {
// Get max 1000 record for each query
maxResult := new(int64)
*maxResult = 1000
getQueryResultsInput := &athena.GetQueryResultsInput{
MaxResults: maxResult,
QueryExecutionId: queryExecutionId,
}
err := a.C.GetQueryResultsPages(getQueryResultsInput, fn)
if err != nil {
return fmt.Errorf("Athena Query Result Process Error. queryExecutionId = " + *queryExecutionId)
}
return nil
}
type ProcessRow func(output *athena.GetQueryResultsOutput, lastPage bool) bool
結果処理はProcessRowでやります。
上記の全ソースコードの例は私のGitアカウント(https://github.com/ngonghi/athena_s3_sample)にアップロードしました。
最後に
以上です。Amazon Athenaを軽く紹介しました。
S3を使って、データを分析したい方は是非Athenaを試してみてください!