Aidemy 2020/12/3
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、レコメンデーション入門の2つ目の投稿になります。どうぞよろしくお願いします。
*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・協調フィルタリングについて
・類似度の計算方法
協調フィルタリングの分類
メリット・デメリット
・Chapter1で学んだ__コンテンツベースフィルタリング__と__協調フィルタリング__のメリットとデメリットについて考える。
・コンテンツベースフィルタリングについて、これは「個人の嗜好などの情報__から類似した商品をレコメンドする」ものであるので、メリットとして「他ユーザーの情報が必要ない」他、利用者のデータがない場合でも「商品のデータさえあればレコメンドできる」と言うメリットがある。デメリットとしては、「大量の正しい商品データ」__が必要であり、商品に精通している必要があることが挙げられる。
・協調フィルタリングについて、これは「似ているユーザーの購入履歴等を参考__にして商品をレコメンドする」ものであるので、メリットとして、「商品の属性データや知識が必要ない」__と言うものが挙げられる。デメリットとしては、「__多くの利用者がいないと__データを集められず、正しくレコメンドできない」と言うものがある。
・総括すると、コンテンツベースフィルタリングは__個人ユーザー/商品依存__であり、協調フィルタリングは__多くのユーザーのデータ依存__ということになる。
データの扱い方
・協調フィルタリング__には「メモリベース」と「モデルベース」__がある。
・メモリベースとは、__利用者の購入履歴をそのまま利用する__ものである。利用者の購入履歴から__類似度__を算出しレコメンドを行うもので、一般的にはこちらが使われる。以降の項でも、こちらを重点的に扱う。
・モデルベースとは、利用者の購入履歴をデータとするモデルを作成__し、より高度なレコメンドを行う方法のことである。例としては「ベイジアンネットワーク協調フィルタリング」と言うものがある。これは__ベイズの定理__を利用してベイジアンネットワークを構築することで、「今まで選ばれてきたデータをもとにどれが選ばれる傾向にあるか」__と言う観点からレコメンドを行うものである。
・ベイズの定理__について、商品1〜10まであるとして、あるユーザーAがまだ商品1を選んでいない時に商品1がレコメンドされる確率を考える。他ユーザーの結果から「最初に商品「i」が選ばれる確率」を「P(i)」とし、「商品1が選ばれていてかつ商品iが選ばれる確率」を「P(i|1)」__とする。この時、Aが商品1を選ぶ確率は以下のように表される。
$$\frac{1}{u}\sum_{i \in u} \frac {P(i|1) P(1)}{P(i)}$$
$\sum_{i \in u}$ の「i」には対象のユーザの聞いたことのある商品を代入する。
・ベイジアンネットワークでは、似ているユーザーを探す必要がなく、データ量が少なくても機能するので、協調フィルタリングのデメリットである「システムの使い始めはデータがなく十分なレコメンドができない」という__コールドスタート問題__を解消できる。
・その他、モデルベースの例として、クラスタリングを使う手法や、次元削減を使う手法がある。
フィルタリングの分類
・Chapter1でも取り上げたが、協調フィルタリングにおけるフィルタリングの分類として改めて見ていく。フィルタリングには__「アイテムベース」と「ユーザーベース」がある。
・アイテムベースは、他の利用者の購入履歴から類似したアイテムのデータを探し、「よくセットで買われているもの」__をレコメンドする方法である。__アイテム間の類似度__を計算する。
・ユーザーベースは、他のユーザーの中で購入履歴が__似ているユーザーを参考__にして、「それらの人が買うことの多いもの」をレコメンドする方法である。こちらは__ユーザー間の類似度__を計算する。
・その他のフィルタリングの手法としては、商品のランキング__もその一つである。価格の低い順や高い順に並び替えるものを「スペックランキング型」といい、人気順に並べ替えるものを「人気ランキング型」__という。これらは対象者ごとにレコメンドは変化しないので、__新規利用者にも有効なレコメンド__を行える。
・他にも、第三者の目線から__関連づけを行ったりレコメンドすることを「ナレッジベース」__という。会社がある商品を売り出したい時は、このナレッジベースを利用者の行動や履歴に適応させてレコメンドする。
ユーザーベース協調フィルタリングの実装
流れ
・今回はユーザーベース協調フィルタリングを実装していく。流れは以下の通り。
①ユーザーの情報を取得する
②評価値などからユーザー間の__類似度__を測定する
③類似度と___評価値__を使って計算する
④計算結果を予想した評価値として出力する
②評価値などからユーザー間の類似度を測定する
コサイン類似度
・Chapter1でも学んだ__「コサイン類似度」__について、ここでは実際に自分で実装する。
・ベクトル$\vec{a},\vec{b}$に対するcosは
$$ \cos,\theta = \frac{\vec{a}・\vec{b}}{|\vec{a}||\vec{b}|}$$
で表される。これがそのままコサイン類似度となる。この値が1に近いほど類似していると言える。
・コードは以下の通り。
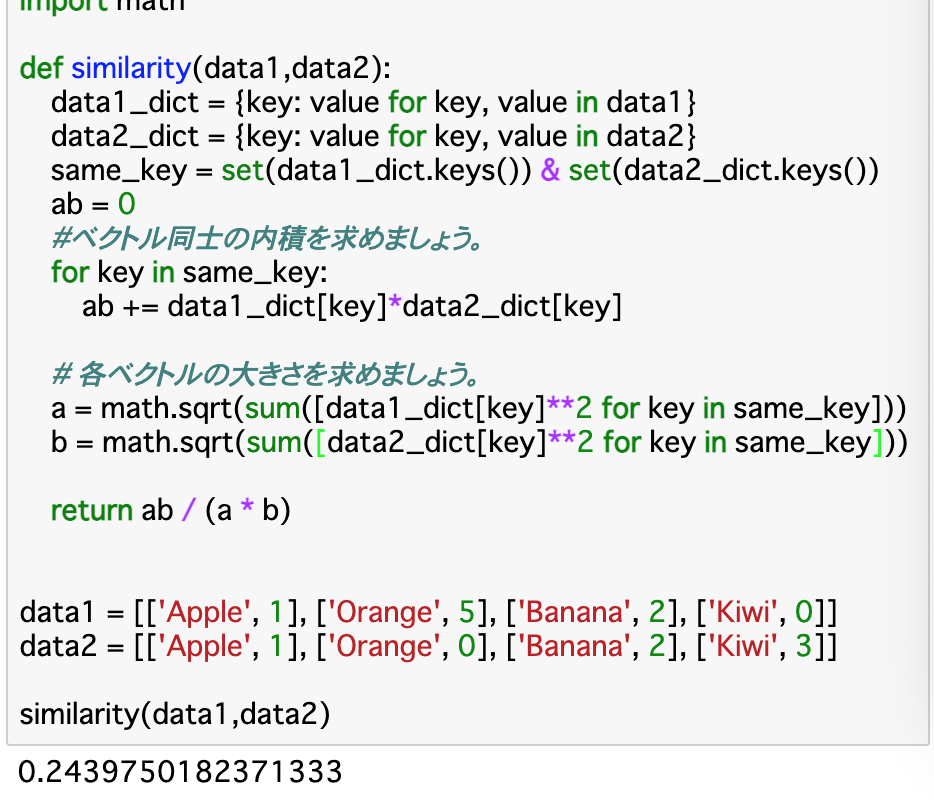
・コードについて、まずは渡されたデータをそれぞれ__{key:value}のベクトルに変換する。また、keyが同じものは「same_key」__として(set()で和集合にして)ひとまとめにする。ここまで行ったら、same_keyのそれぞれのkeyについて、__2つのベクトルの内積(ab)を求める。これが上記式の分子となる。
・分母については「それぞれのベクトルの大きさ」を求めれば良いので、それぞれのベクトルの各要素(key)を2乗し、全て足し合わせたものの平方根をとることで求められる。最終的に、「ab/(a*b)」__を返す。
ピアソン相関
・ピアソン関数__とは、2つのデータの直線的な強さ__を-1~1で表したものである。2つのデータが同じように増加減少するとき相関は1に近づき、逆向きに増加減少する時-1に近づく。また、片方のデータの増加減少が他方に影響しないとき、0に近づく。
・$S_x$と$S_y$を__標準偏差、すなわち(データ-平均)^2の平方根__をとることで算出できるものと、$S_{xy}$を__共分散__、すなわちそれぞれの__(データ-平均)を掛け合わせる__ことで算出できるものとすると、ピアソン相関は$\frac{S_{xy}}{S_x S_y}$で表される。
・ピアソン相関が活きる場面として、例えば普段から商品に高評価をつける人が星5をつけるのと、辛口の人が星5をつけるのでは重みが異なる。これをピアソン相関では考慮に入れることができる。
・以下はピアソン相関を算出する関数__「sim_pearson()」__である。
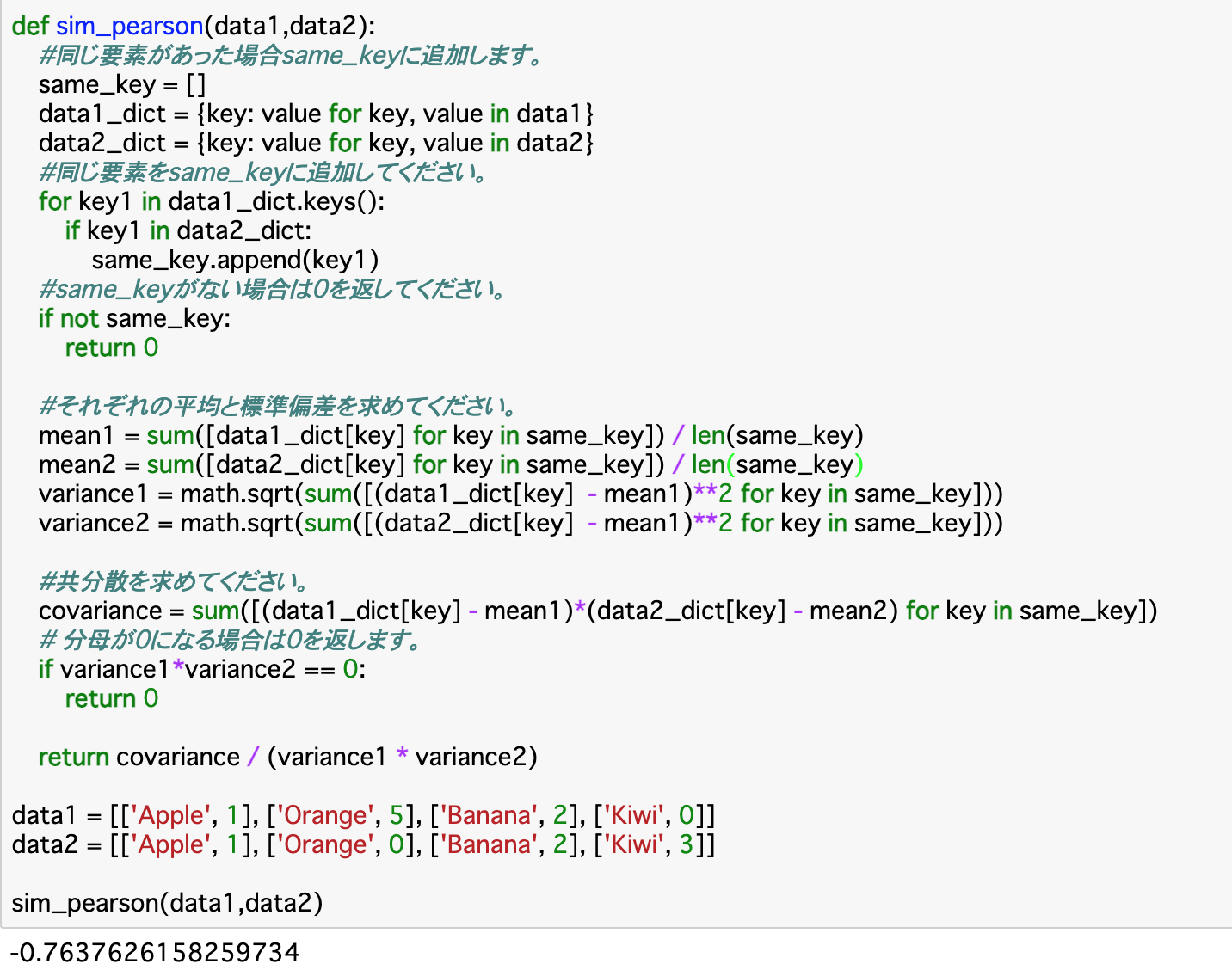
・上記コードについて、まずは前項と同様に渡されたデータを__{key:value}のベクトルに変換し、同じkeyを持つものは「same_key」に格納する。same_keyがない場合はその時点でピアソン相関がないということになるので、0を返す。
・次に、それぞれの__平均(mean)と、それを使って__標準偏差__(variance)を求める。平均については、same_keyのそれぞれのkeyについて、__「sum(data_dict[key])」でdataの合計を求められるので、これを「len(same_key)」で割れば良い。標準偏差については「data_dict[key]-mean」を2乗したものを合計して、「math.sqrt()」で平方根を取れば良い。
・また、共分散(covariance)も求める。それぞれの「data_dict[key]-mean」__をかけるだけで良い。
・ここまで行ったら、実際に先述した式に当てはめる。__ゼロ除算__として、分母(標準偏差の積)が0になるときは0を返す。
スピアマン順位相関係数
・順位データから求める__直線的な強さ__について考える指標を__「スピアマン順位相関係数」__という。$\rho$(rho)で表す。ピアソン相関の__評価値の部分を順位データとしたもの__であり、これを行うと式がピアソン相関よりも簡単になる。__N__をデータの個数とすると、以下のように表される。
$$1 - \frac{6 \sum_i (x_i - y_i)^2}{N(N^2 -1)}$$
・以下はスピアマン順位相関係数を計算する関数__「spearman()」__である。
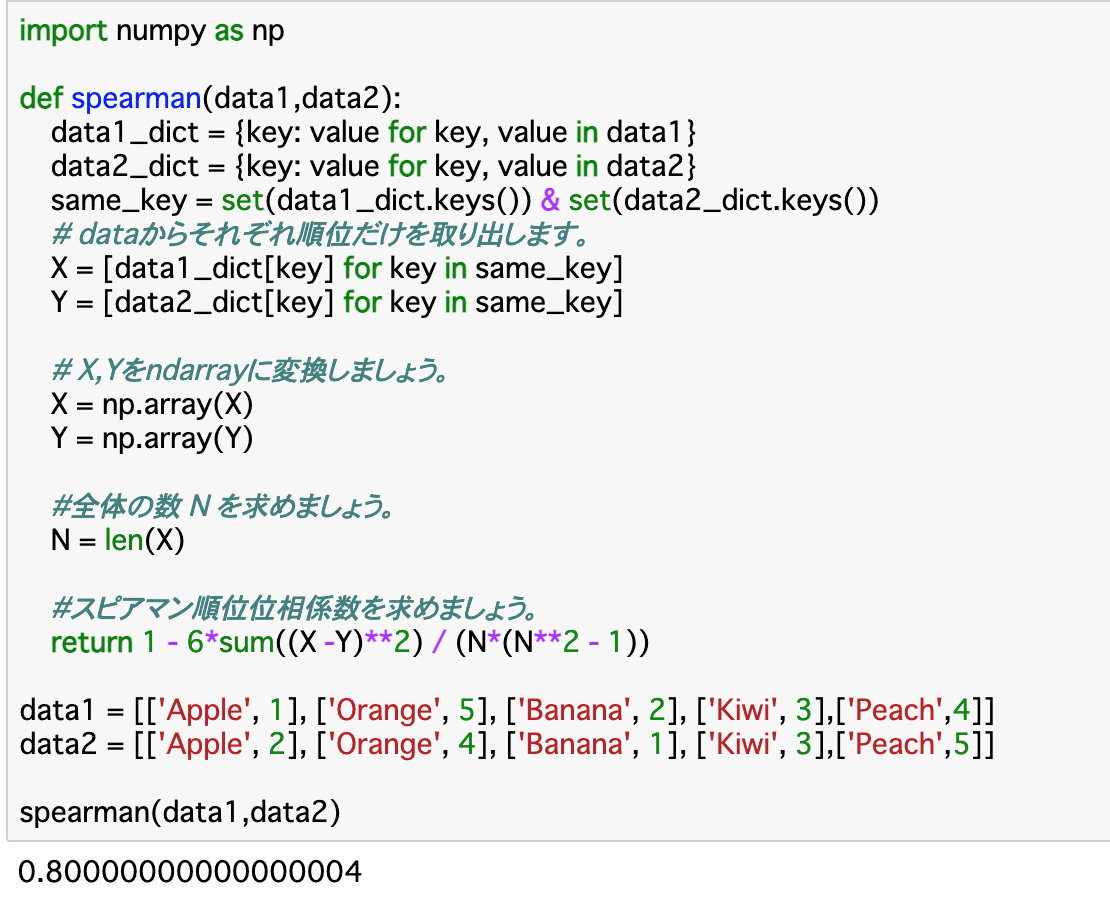
・上記関数について、渡された__データの順位__(変数で言うとvalue)を取り出し、XとYに格納する。また、直後の計算で使用するので、ndarray__に変換する。データの個数Nは「len(X)」__で良い。
・返り値は上記式をそのまま記述すれば良い。
ジャッカード係数
・ジャッカード係数__は単純に、全要素(keys)のうちの__2つのデータの両方に含まれる要素(same_key)の割合__である。すなわち、両方に含まれる要素数が多いほど1に近づき、類似度が高いと言える。要素の評価値(value)は一切考慮されない。
・ジャッカード係数を算出する関数「jaccard()」__は以下のようになる。

・コードではsame_keyを「common_word」としているが、抽出の仕方は今までと同じで良い。今回は個数だけ分かれば良いので、抽出した個数分をcommon_wordに格納している。それぞれの要素数は「len(data)」のようにして求める。
実践
・ここでは7人のユーザーが6種類の映画の中から見たことのある映画とその評価が格納されたデータセットを使って、ユーザーベース協調フィルタリングでTobyさんに最もおすすめな映画を選ぶ。
・レコメンドの基準は__「(類似度×評価)の合計/類似度の合計」で算出する。これが最も大きい映画をレコメンドする。
・コードについて、「similarity()」には2つの特徴ベクトルを渡し、それらついて$\frac{\vec{a}・\vec{b}}{|\vec{a}||\vec{b}|}$を算出する。これが__類似度__となる。
・「get_recommend()」では「(類似度×評価)の合計/類似度の合計」を算出し、ランキングの一番目をレコメンドとして出力する。「(類似度×評価)の合計」は「total」に格納し、「類似度の合計」は「sim_sums」に格納する。
・今回レコメンドするのは「targetがまだ見ていない映画」である必要があるので、これをリストで作成する。target以外の人が見た映画のリスト(set_person)からtargetが見た映画のリスト(set_target)を引けば良い。
・次にsimilarity()でpersonとtargetの類似度を算出し、「sim」に格納する。そして、先程のtarget見ていない映画のそれぞれ(movie)について、「dataset[person][movie]」__でその人のその映画に対する評価を取りだし、__これと類似度「sim」をかけたもの__を「total」に格納する。同様に、「sim_sums」にはpersonごとのtargetとの類似度を加算する。
・これらについて「(類似度×評価)の合計/類似度の合計」を算出し、ランキングを作成し、値が大きいものから降順に並び替え、どの一番目のものをオススメとして出力する。
・dataset
・関数

まとめ
・協調フィルタリング__は、商品データは必要ないが、多くのユーザーの情報は必要になる。また、この時のフィルタリングとして、アイテム間の類似度を算出する「アイテムベース」と、ユーザー間の類似度を算出する「ユーザーベース」__がある。
・ユーザー間の類似度についても、cos類似度__で算出する。$\frac{\vec{a}・\vec{b}}{|\vec{a}||\vec{b}|}$で求められる。
・他の類似度の算出方法について、二つのデータの直線的な強さを示す相関係数「ピアソン相関」を求める方法がある。二つのデータについて、「共分散/標準偏差の積」で求められる。また、これを順位データから考える「スピアマン順位相関係数」というものもある。こちらの方がピアソン相関より計算量は少なくて済む。
・また、評価値を考慮しないで類似度を算出する手法として、「ジャッカード係数」__がある。これは、両方に含まれる要素数の割合である。
今回は以上です。最後まで読んでいただき、ありがとうございました。